
Linux-从入门到入土
Linux学习笔记-B站韩顺平_KK-Greyson的博客-CSDN博客
Linux-从入门到入土

VMware 下载
进入官网的 VMware Workstation Pro 页面,浏览功能特性、应用场景、系统要求等。下滑页面点击 试用 Workstation 16 Pro 下方的下载链接,跳转至下载页面。
在下载页面中下滑,根据操作系统选择合适的产品,在这里以 Windows10 系统为例,选择 Workstation 16 Pro for Windows,开始下载安装文件。

VMware 安装
打开下载好的 .exe 文件, 即可开始安装。
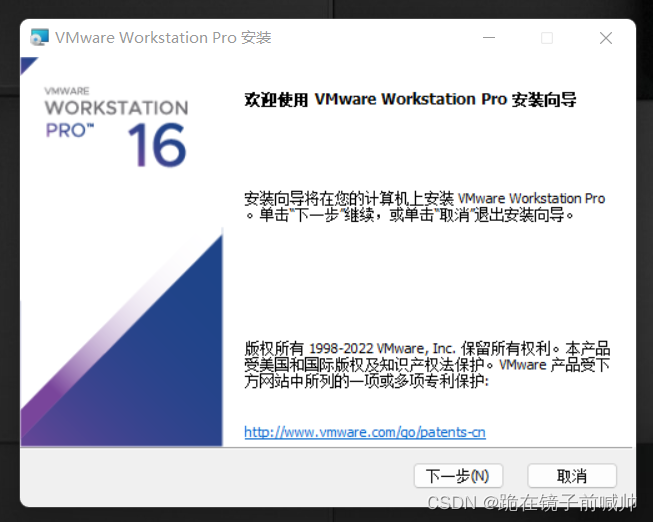
安装位置默认在 C 盘下,在这里我选择安装在 D 盘,安装路径尽量不要有中文。可勾选 增强型键盘驱动程序 ,此功能可更好地处理国际键盘和带有额外按键的键盘。
一直点击 下一步 等待软件安装完成。
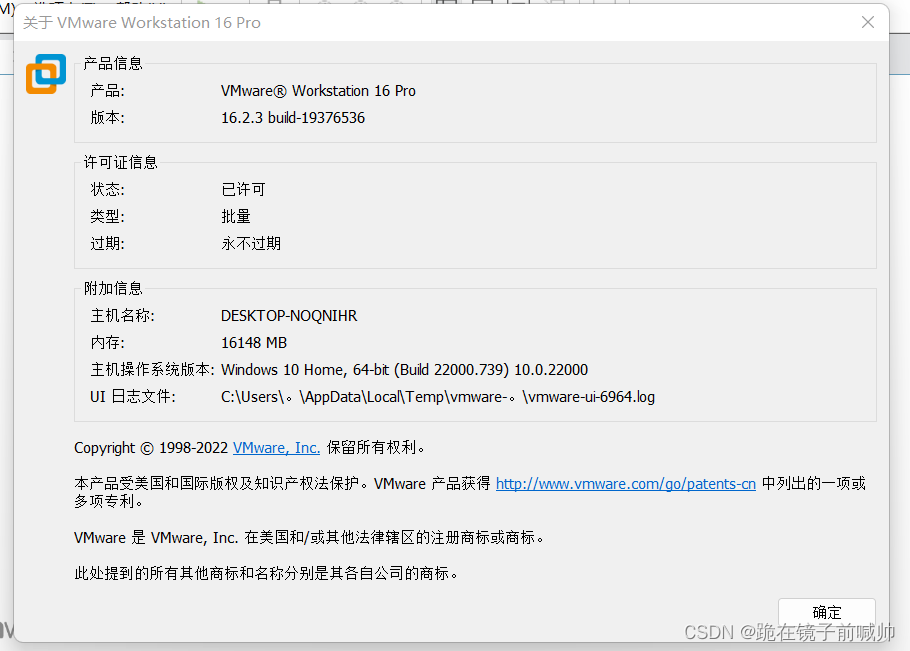
安装成功后点击 许可证 输入密钥激活软件。
将 密钥 (过期了可以自行百度一个)填写到文本框中点击 输入。
安装后可能要求重启系统,重启后进入软件。依次点击导航栏中的 帮助 -> 关于 VMware Workstation ,查看许可证信息的状态,如下图所示即为激活成功。
VMware创建虚拟机
1、首先打开下载好的VMware软件,在主页上点击“创建新的虚拟机”
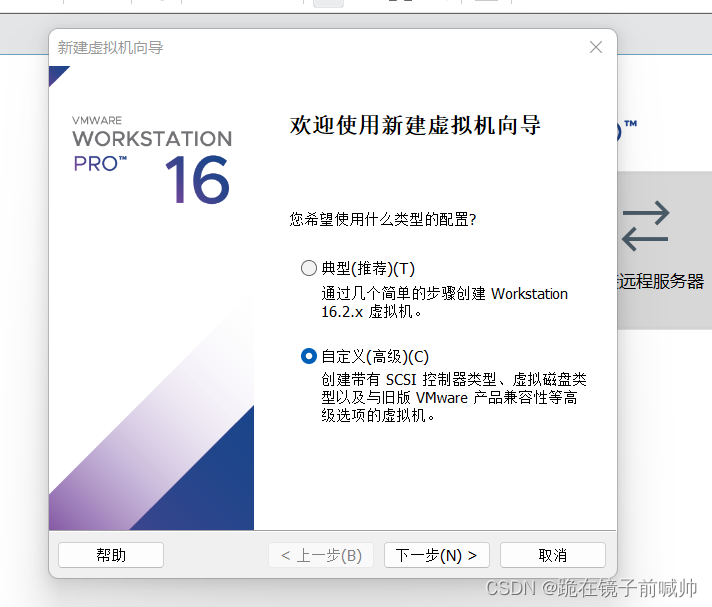
2、弹出向导窗口,“典型”选项安装过程比较简单,“自定义”选项则可以提供更多高级的选项。这里我选择“自定义”
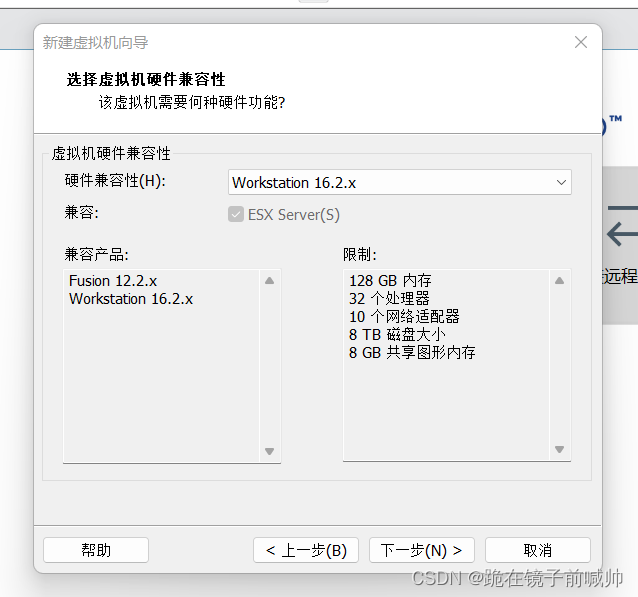
3、选择虚拟机硬件兼容性。理论上来说硬件版本越高,兼容性越好。所以我选择列表中版本最高的Workstation 16.x
4、 安装客户机操作系统。因为该软件比较智能,现在安装会将操作系统直接装好而不需要向导,基于对linux系统安装的学习,这里我选稍后安装。其实只是先后顺序的问题,无太大影响。
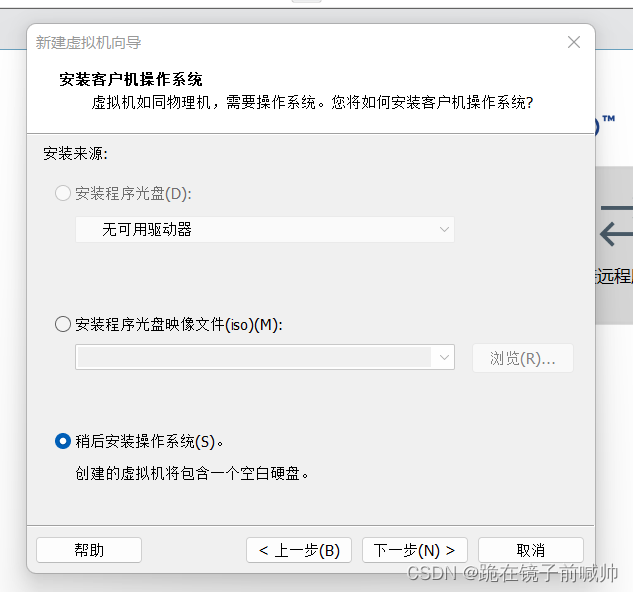
5、 选择操作系统。这里就看使用者的个人要求了,版本众多,都可以。这里我选择Linux(版本如图)
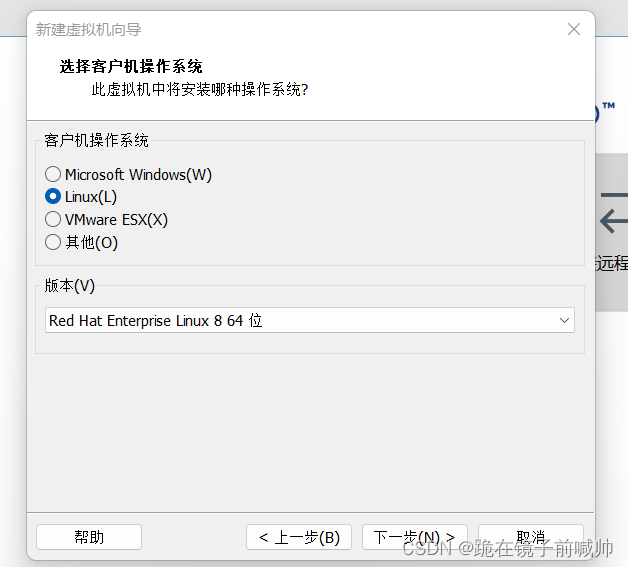
6、下一步,命名虚拟机。为虚拟机起一个好听的名字,在给他安个家(就是命名虚拟机和设置虚拟机文件位置,最好别放到C盘)
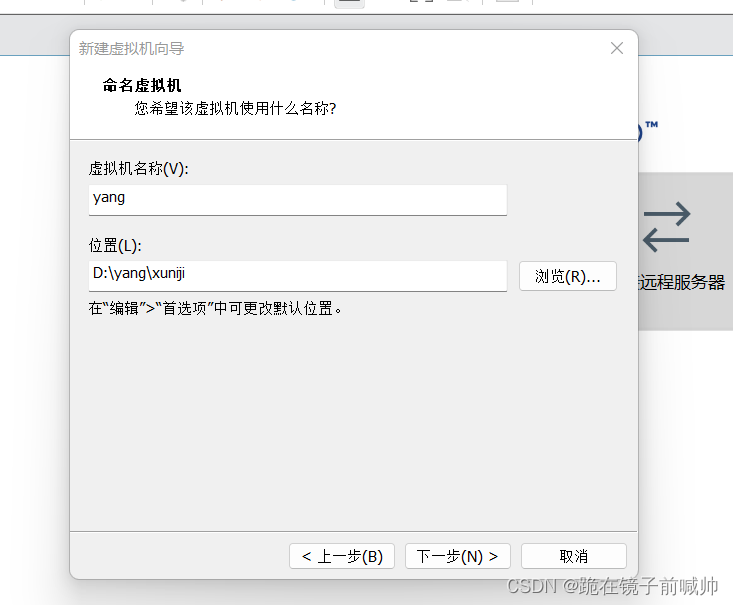
7、下一步,处理器配置。处理器内核总数=处理器数量*每个处理器内核数量,根据自己电脑配置,合理选择数量
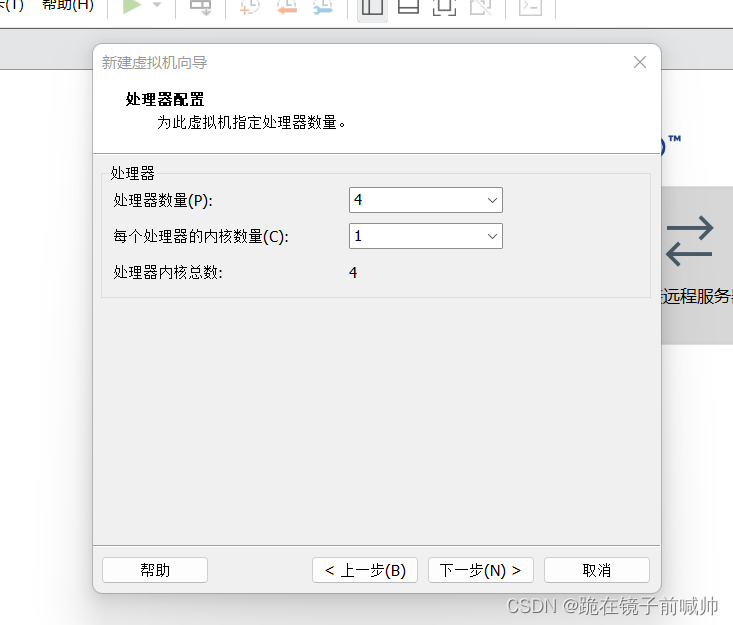
8、设置虚拟机内存。在推荐范围内均可,虚拟机是用多少内存就占多少内存(也用不了多少),所以不用担心浪费,只要不太多或太少就行
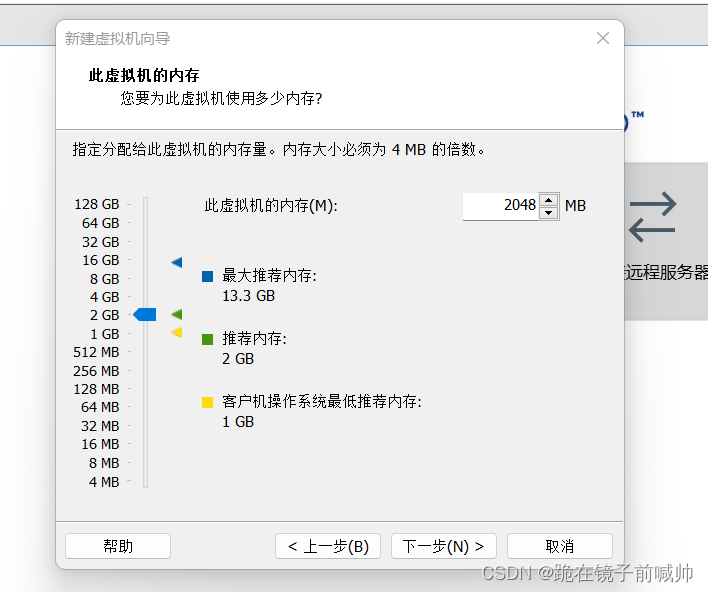
9、 网络类型。也就是选择网卡类型。一般选第二个或第三个即可。这里我选第三个。
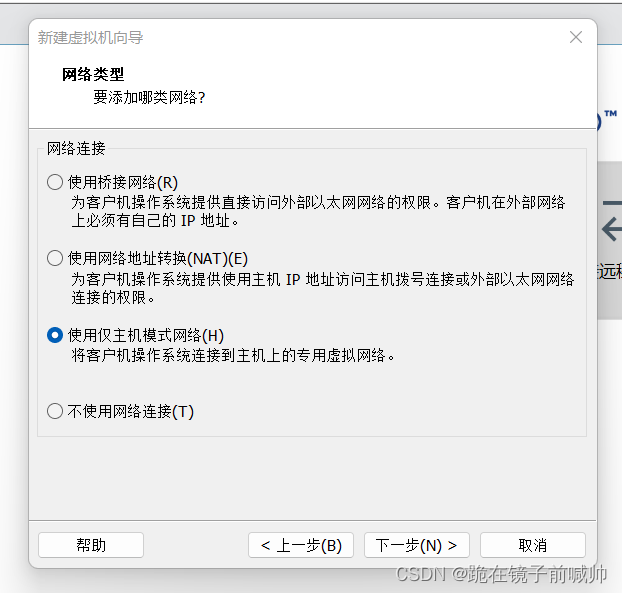
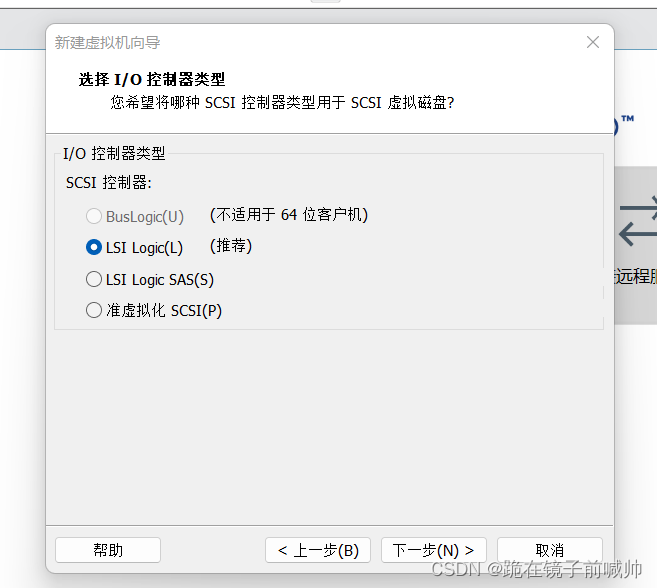
10、 后两步选择I/O控制器类型和磁盘类型均选择系统推荐的选项即可
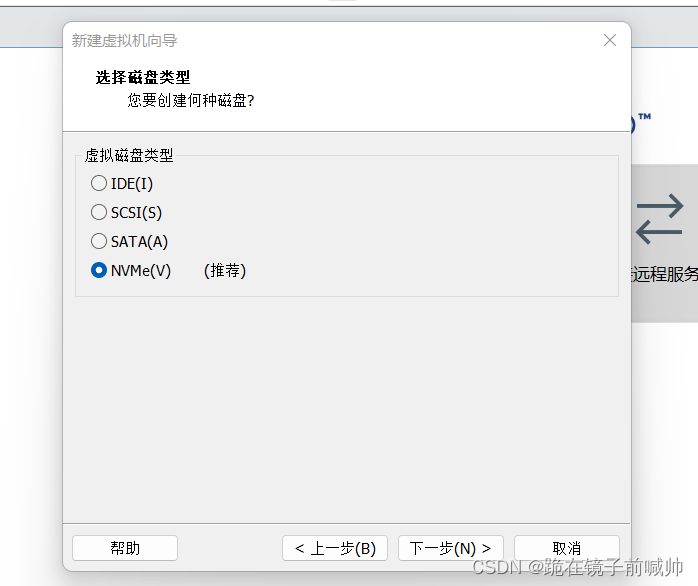
11、选择磁盘。若以前没有配置的磁盘,选第一个选项“创建新虚拟磁盘”,若有则选第二个即可
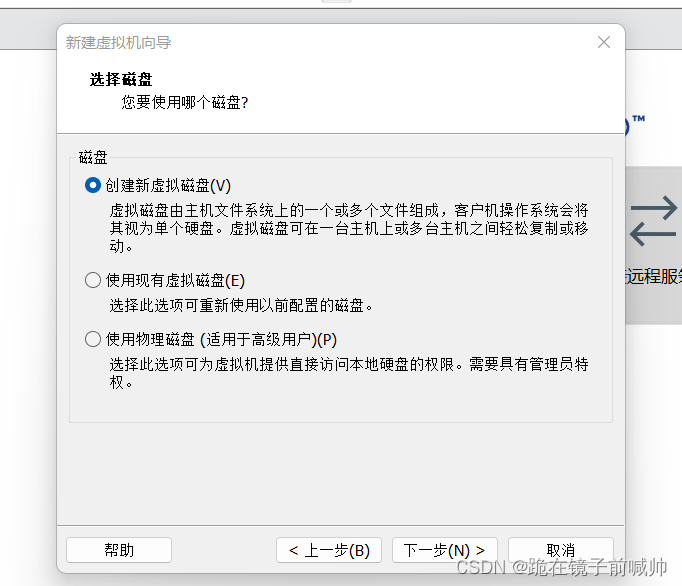
12、指定磁盘容量。即分配给磁盘的空间大小。推荐大小就够用,也是用多少占多少。注意不要勾选下面的复选框(勾上它就把你设置的磁盘空间全部占为己有了),下面单选选择第一个选项(单个文件便于管理,提高磁盘性能)
13、到这里虚拟机雏形就准备好了
14、下面通过配置ISO映像文件来安装系统
首先,我们需要访问CentOS的官方网站。并选择好需要下载的CentOS的版本以及系统架构。
然后点击镜像所在的下载地址,本文中选择使用了来自清华源的镜像地址
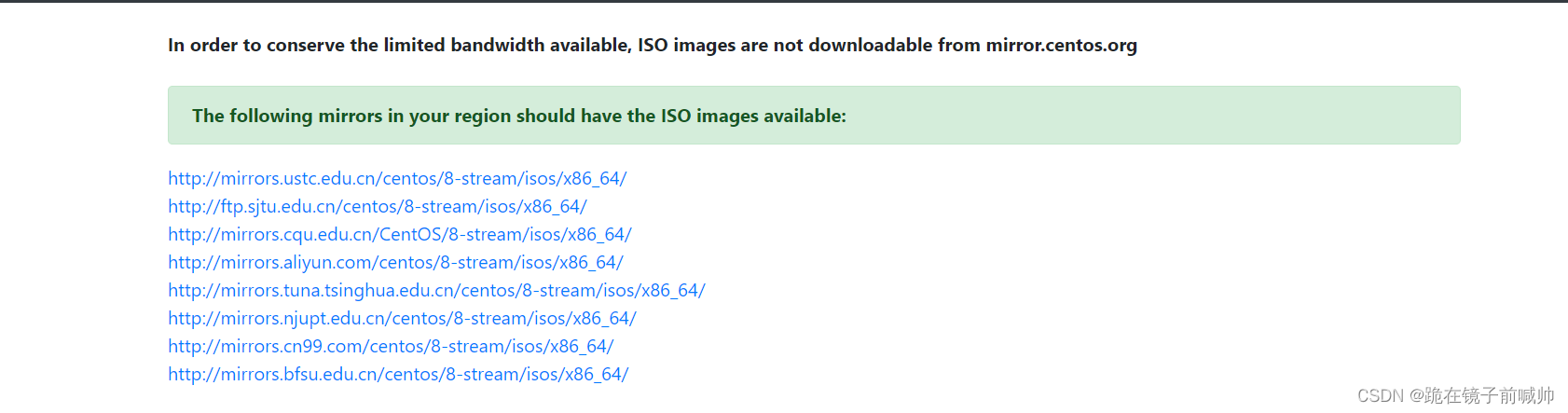
然后选择一下需要下载的iso镜像文件的版本。如果自己电脑配置比较低,可以选择boot类型的iso镜像文件。本文选择了dvd带图形界面的镜像文件。
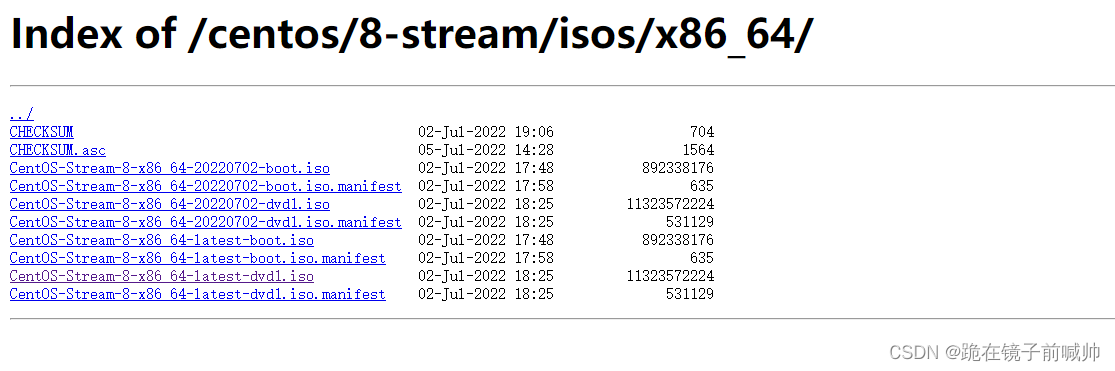
选择ISO文件准备开机
网络连接的三种方式
1、桥接模式
在此模式下,虚拟机就像是独立的主机,和真实的物理主机是一样的地位,可以通过虚拟机所在的物理主机访问外网,外网中的其他主机也可以访问此虚拟机。虚拟机与外网主机通讯需要满足以下条件:
- 虚拟机所创建保存的物理主机与其他主机在同一局域网下
- 为虚拟机设置一个与创建该虚拟机的主机的物理网卡在同一网段的IP
- 虚拟机与创建该虚拟机的物理主机设置为桥接模式
下面针对以上三个条件进行详解:
条件1只需满足几台电脑连接在同一局域网即可;
条件2需要设置虚拟机和物理主机的网络在同一网段下,具体设置方法如下(以VM软件为例):
1、在VW的编辑菜单中选择虚拟网络编辑器,并将VMnet信息中的模式选为桥接模式。若物理主机使用的无线网卡连接局域网,则同样需要在VM中设置为桥接至无线网卡;同理桥接至有线网卡。设置好点击确定即可。
2、设置好桥接模式之后,由于模式的改变,需要在Linux终端中重启网络连接,否则无法实现通讯。重启网络连接的命令行为:
1 | systemctl restart network |
3、网络重启之后,在物理主机的系统上(默认为Win)查看当前正在使用的网卡的IP地址:
4、最后在Linux终端上修改虚拟机的IP,为保证虚拟机IP与物理主机的IP在同一网段,需要保证IP地址的前三位是相同,最后一位在符合定义的情况下随意设置即可。命令行操作为:
1 | ifconfig ens33 10.141.117.12/24 |
其中,ens33为虚拟机的网卡,/24表示子网掩码
至此,在桥接模式下即可实现虚拟机与其他物理主机的通讯,通讯命令为:ping 其他物理主机的IP地址
1 | ping 10.141.117.22 |
2、仅主机模式
仅主机模式表示的是物理主机与物理主机之间用同一局域网连接,虚拟机则是采用的虚拟网络连接,它与物理网络是隔开的,所以此模式下虚拟机与别的物理主机无法实现通信。一般在安装VM之后,软件会自动添加VMnet1和VMnet8两块虚拟网卡。也就是说,仅主机模式下,只能实现虚拟机和创建虚拟机的物理主机之间的通讯。该模式通讯需满足的条件为
- 虚拟机的IP和物理主机的VMnet1网卡的IP在同一网段内
下面针对该条件进行详解:
1.在VM中设置虚拟网络模式为仅主机模式,然后重启虚拟机的网络
2.在Win中找到VMnet1的IP地址,然后在虚拟机中设置为同一网段即可
3.最后ping 物理主机IP地址
3、NAT模式(网络地址转换模式)
NAT模式对应的虚拟网络为VMnet8,这是一个独立的网络。此模式下物理主机就像是一台支持NAT功能的代理服务器,虚拟机就像是NAT的客户端一样。虚拟机可以使用物理主机的IP地址访问互联网,但由于NAT技术的特点,外部网络中的主机无法主动与NAT模式下的虚拟机进行通讯。也就是说,只能是由虚拟机到外部网络计算机的单向通信。物理主机与NAT模式下的虚拟机是可以互通的,前提是要虚拟机的IP与VMnet8的网卡IP在同一网段内。
此模式的结构图与仅主机模式结构图一样。
主机与NAT模式下的虚拟机是可以互通的,前提是要虚拟机的IP与VMnet8的网卡IP在同一网段内。
虚拟机克隆
虚拟机快照
在学习阶段我们无法避免的可能损坏Linux操作系统。
如果损坏的话,重新安装一个Linux操作系统就会十分麻烦。
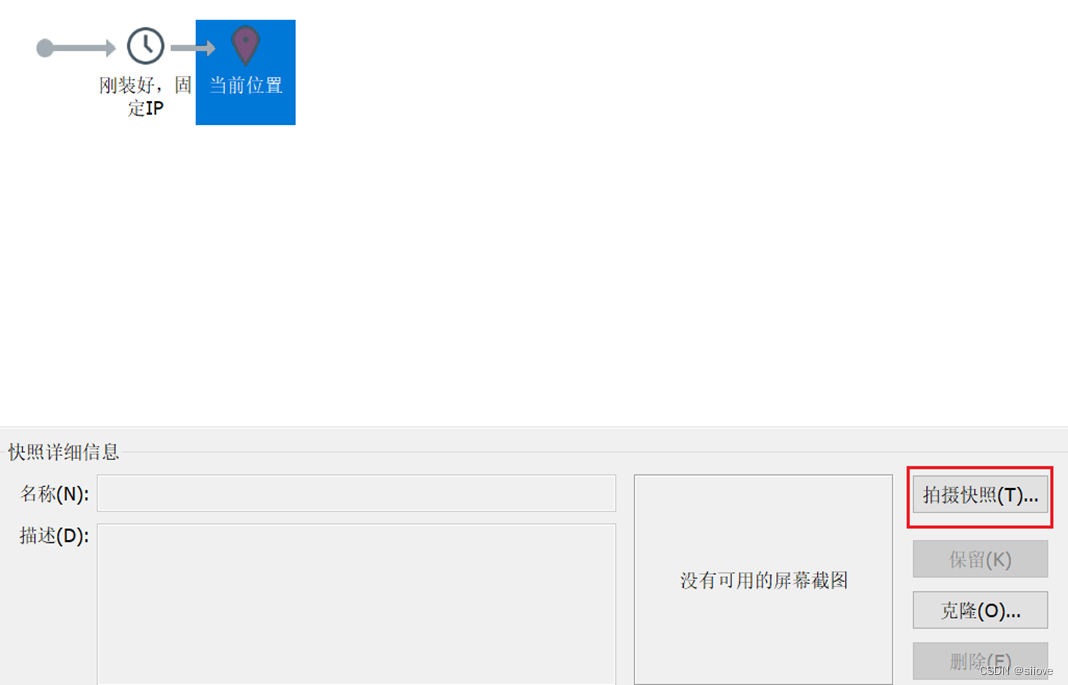
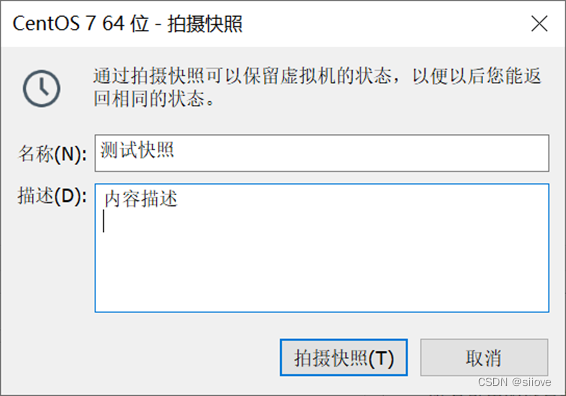
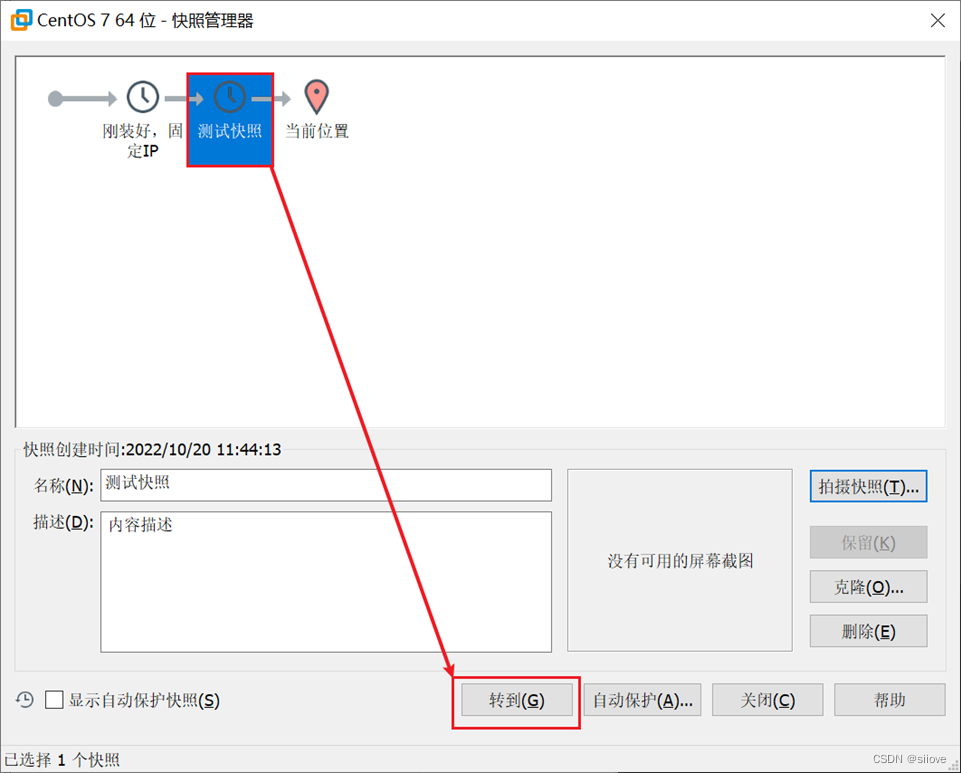
VMware虚拟机(Workstation和Funsion)支持为虚拟机制作快照。
通过快照将当前虚拟机的状态保存下来,在以后可以通过快照恢复虚拟机到保存的状态。
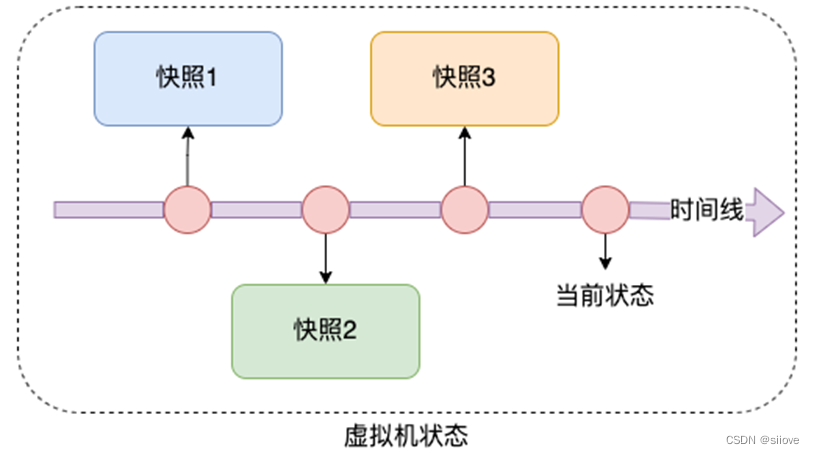
在VMware Workstation Pro中制作并还原快照(windows)
vmtools–与电脑主机共享文件
VM Tools安装过程
一、VM Tools安装步骤
此时系统会弹出装载虚拟CD驱动器 点击打开文件
打开文件后可将 文件夹里的文件全部复制到自己的某个文件夹中,比如桌面

注意:这里的文件名是你自己桌面上那个.gz文件 的名称,根据自己对应的版本来哦
这时候你的桌面上应该多了一个文件夹,下面执行命令:
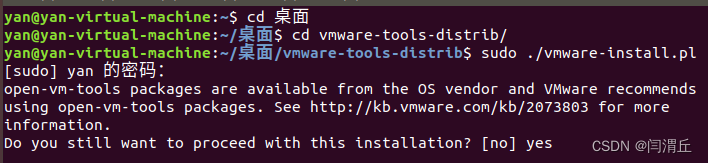
1 | cd vmware-tools-distrib |
然后输入密码,一路 enter/YES,就OK了!
到这里VMware tools安装完成,试着将文件拖动到liunx系统当中!
重启虚拟机,有个重新安装VM Tools证明安装成功了
二、安装后无法使用问题解决办法之一
root用户进入后设置共享文件夹总是启动
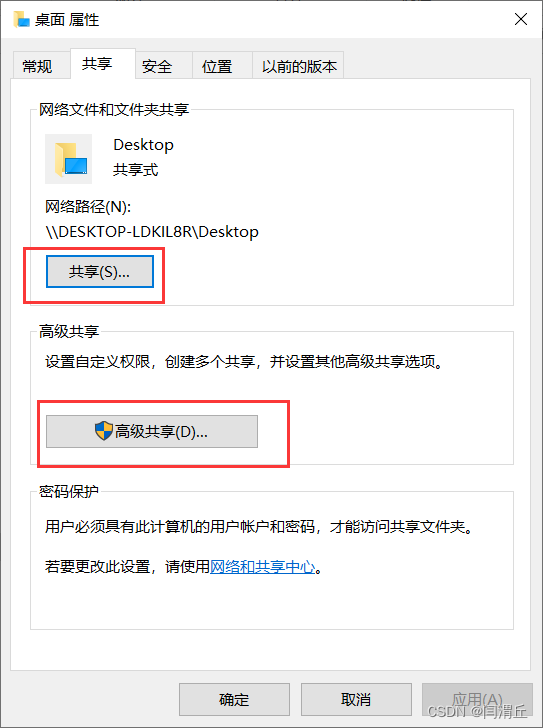
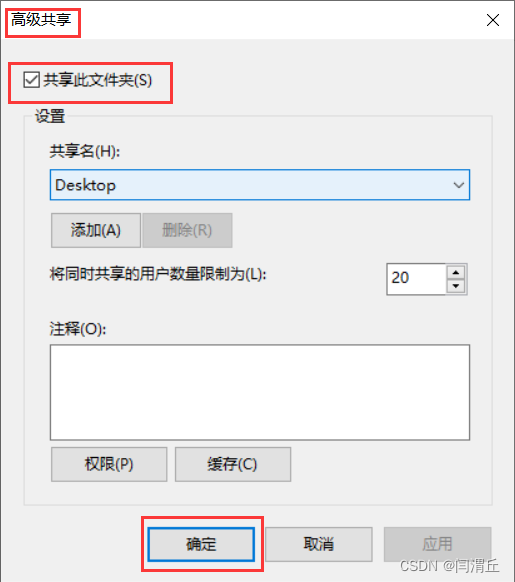
1.更改虚拟机设置,选择“编辑虚拟机设置”,在“选项”中启用“共享文件夹”,然后设置自己方便的文件夹,我这里设置为自己电脑的桌面,方便文件的复制。同时检查“客户机隔离”选项内是否启用拖放和复制粘贴,如果没有记得打开。
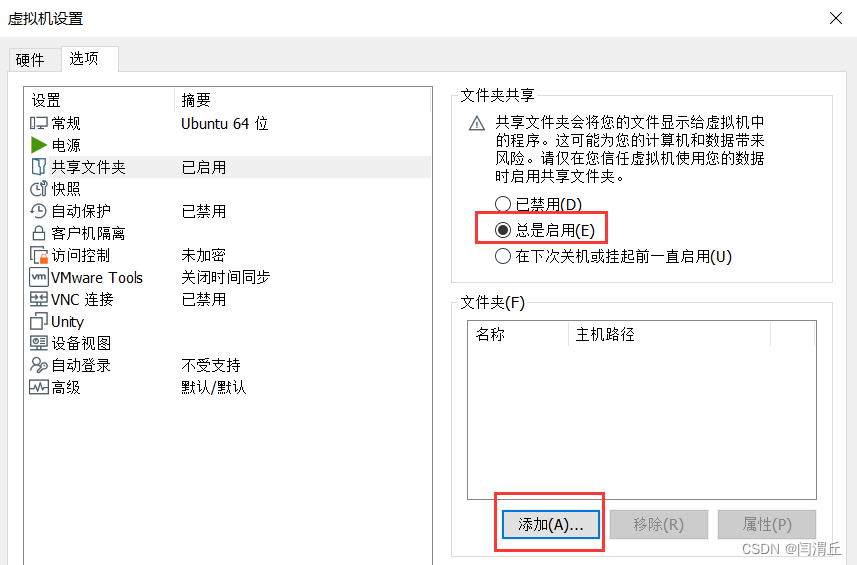
我设置的是我的桌面
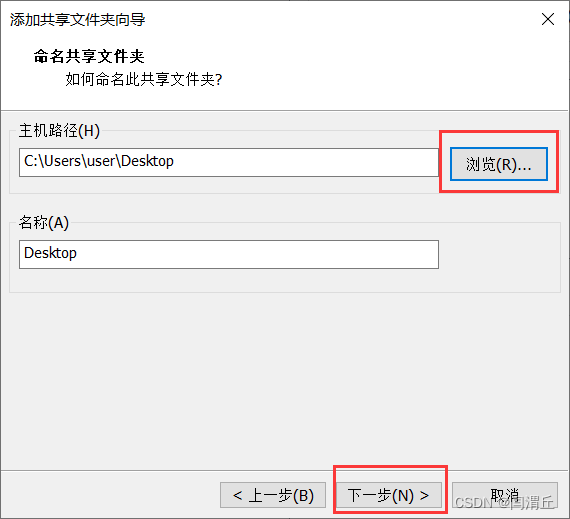
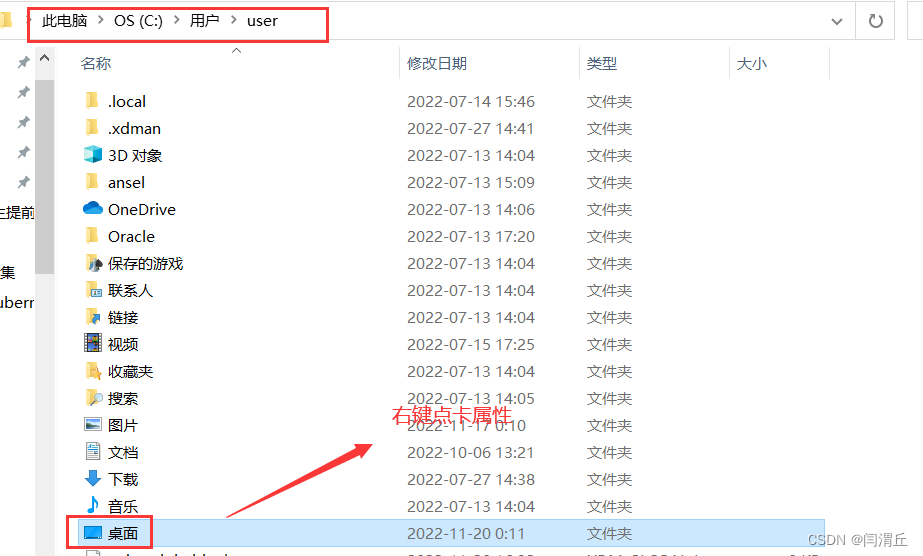
2.找到刚刚设置的文件夹路径(C:\Users\user\Desktop),将该文件夹路径开启共享权限,为了防止出现问题,我选择把“共享”和“高级共享”都开启
3.打开Ubuntu,在终端界面依次输入以下命令,检查共享的文件夹能否在Ubuntu内查看,首先进入mnt/hgfs文件夹,输入“ls”看看共享的文件夹“Desktop”是否存在,如果存在则说明共享成功。

这个时候进入Desktop里面的文件就是WIN桌面的文件
Linux系统目录结构----重点记忆!
目录
1、Linux目标结构的特点
Linux采用的是树型结构。最上层是根目录,其他的所有目录都是从根目录出发而生成的。 微软的DOS和windows也是采用树型结构,但是在DOS和 windows中这样的树型结构的根是磁盘分区的盘符,有几个分区就有几个树型结构,他们之间的关系是并列的。但是在linux中,无论操作系统管理几个磁盘分区,这样的目录树只有一个。从结构上讲,各个磁盘分区上的树型目录不一定是并列的。 Linux的虚拟文件系统允许众多不同类型的文件系统共存,并支持跨文件系统的操作。 Linux的文件是无结构字符流式文件,不考虑文件内部的逻辑结构,只把文件简单地看作是一系列字符的序列。 Linux的文件可由文件拥有者或超级用户设置相应的访问权限而收到保护。 Linux把所有的外部设备都看作文件,可以使用与文件系统相同的系统调用来读写外部设备。
2. Linux目录结构

常见:
/:是所有文件的根目录;
/bin:存放二进制可执行命令目录;
/home:用户主目录的基点目录,默认情况每个用户主目录都设在该目录下,如默认:用户user01的主目录是/home/user01,可用~user01表示
/lib:存放标准程序设计库目录,又叫动态链接共享库目录,目录中文件类似windows里的后缀名为dll的文件;
/etc:存放系统管理和配置文件目录;
/dev:存放设备特殊文件目录,如声卡文件,磁盘文件等;
/usr:最庞大的目录,存放应用程序和文件目录;
/proc[不能动]:虚拟目录,是系统内存的映射,可直接访问这个目录来获取系统信息;
/root:系统管理员的主目录(特权阶级)
/var:存放系统产生的经常变化文件的目录,例如打印机、邮件等假脱机目录、日志文件、格式化后的手册页以及一些应用程序的数据文件等;
/tmp:存放公用临时文件目录。
补充:
/etc/rc.d 启动的配置文件和脚本
/sbin 系统管理命令,这里存放的是系统管理员使用的管理程序
/mnt 系统提供这个目录是让用户临时挂载其他的文件系统。
/lost+found 这个目录平时是空的,用于存放系统非正常关机而留下未保存的文件
/opt 软件安装包文件夹
/usr其中包含:
/usr/X11R6 存放X window的目录
/usr/bin 众多的应用程序
/usr/sbin 超级用户的一些管理程序
/usr/doc linux文档
/usr/include linux下开发和编译应用程序所需要的头文件
/usr/lib 常用的动态链接库和软件包的配置文件
/usr/man 帮助文档
/usr/src 源代码,linux内核的源代码就放在/usr/src/linux里
/usr/local/bin 本地增加的命令
/usr/local/lib 本地增加的库
二、Linux文件系统介绍
文件系统指文件存在的物理空间,linux系统中每个分区都是一个文件系统,都有自己的目录层次结构。 linux会将这些分属不同分区的、单独的文件系统按一定的方式形成一个系统的总的目录层次结构。 一个操作系统的运行离不开对文件的操作,因此必然要拥有并维护自己的文件系统。
1. 索引介绍:
Llinux文件系统使用索引节点来记录文件信息,作用像windows的文件分配表。
索引节点是一个结构,它包含了一个文件的长度、创建及修改时间、权限、所属关系、磁盘中的位置等信息。
一个文件系统维护了一个索引节点的数组,每个文件或目录都与索引节点数组中的唯一一个元素对应。
系统给每个索引节点分配了一个号码,也就是该节点在数组中的索引号,称为索引节点号。
linux文件系统将文件索引节点号和文件名同时保存在目录中。
所以,目录只是将文件的名称和它的索引节点号结合在一起的一张表,目录中每一对文件名称和索引节点号称为一个连接。
对于一个文件来说有唯一的索引节点号与之对应,对于一个索引节点号,却可以有多个文件名与之对应。
因此,在磁盘上的同一个文件可以通过不同的路径去访问它。
2. Linux链接介绍
可以用ln命令对一个已经存在的文件再建立一个新的连接,而不复制文件的内容。连接有软连接和硬连接之分,软连接又叫符号连接。
linux文件系统操作
1. 文件的基本概念
在linux中,一切皆文件。文件是由创建者定义的,具有文件名的一组相关元素的集合,文件可以是文本文档、图片、程序等。Linux系统下文件名长度根据不同类型文件系统有所不同。
文件取名必须遵守以下规则:
\1. 除“/”外,所有字符都可使用;
\2. 转义字符最好不用,如“ ? ”," * “(星号),” "(空格),“ $ ”,“ & ”等;
\3. 避免使用“ + ”,“ - ”或“ . ”作为普通文件名的第一个字符(在Linux下以“ . ”开头的文件都是隐藏文件);
\4. Linux系统的文件名大小写敏感。
2. Linux系统下的通配符(20个)
* :通配符,代表任意字符(0到多个)
?:通配符,代表一个字符
# :注释
\ :转义符号,将特殊字符或通配符还原成一般符号
| :分割两个管线命令的界定
; :连续性命令的界定
~ :用户的根目录
$ :变量前需要加的变量值
! :逻辑运算中的“非”
/ :路径分割符号
> :输出导向,分别为“取代”和“累加”
>>:输出导向,分别为“取代”和“累加”
’ :不具有变量置换功能
" :具有变量置换功能
:quote符号,两个中间为可以先执行的指令
() :中间为子shell的起始与结束
[] :中间为字符组合
{} :中间为命令区块组合
&&:当该符号前一个指令执行成功时,执行后一个指令
|| :当该符号前一个指令执行失败时,执行后一个指令
3. Linux系统下的常用快捷操作(七个)
Ctrl+C:终止当前命令
Ctrl+D:输入结束
Ctrl+M:相当于Enter
Ctrl+S:暂停屏幕的输出
Ctrl+Q:恢复屏幕的输出
Ctrl+U:在提示符下,将整行命令删除
Ctrl+Z:暂停当前命令
四、Linux文件操作
\1. 显示文件内容(6个):cat、more、less、head、tail
\2. 搜索、排序、去重(三个):grep、sort、uniq
\3. 比较(两个):comm、diff
\4. 复制、删除、移动(三个):cp、rm、mv
\5. 统计(一个):wc
\6. 查找(一个):find locate which grep
\7. 压缩解压缩(三个):bzip2、gzip、tar
五、linux目录操作
\1. 切换工作目录和显示当前目录(3个):cd、pwd、ls
\2. 创建和新建目录(2个):mkdir、rmdir
\3. 改变文件或目录存取权限命令(1个):权限概念、文件长格式解读、chmod(改编权限)
\4. 改变用户组和文件组(2个):chgrp、chown
\5. 链接文件(1个):ln
Linux远程登录—xshell
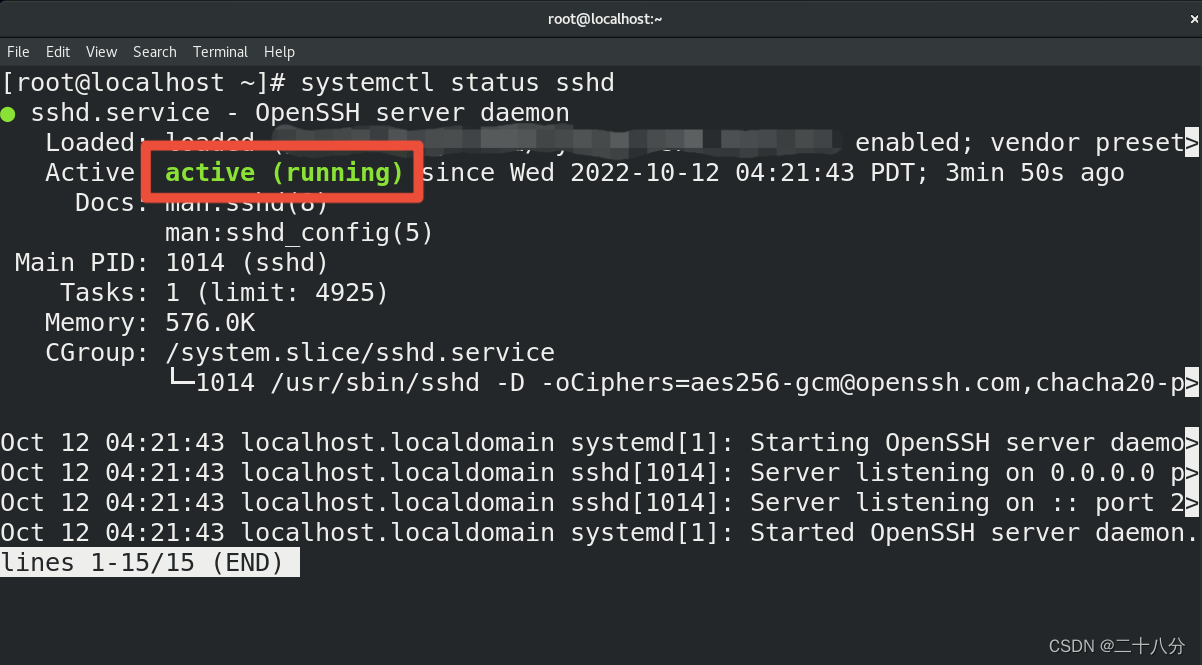
第一步:在Linux上查看SSH的工作状态:打开Linux终端,输入systemctl status sshd,如图所示,红色方框里的内容说明你安装了SSH并且正在工作;
第二步:查看服务器的IP地址:打开Linux终端,输入ifconfig,如图所示红色方框里的内容,即为IP地址(每一台电脑都不一样);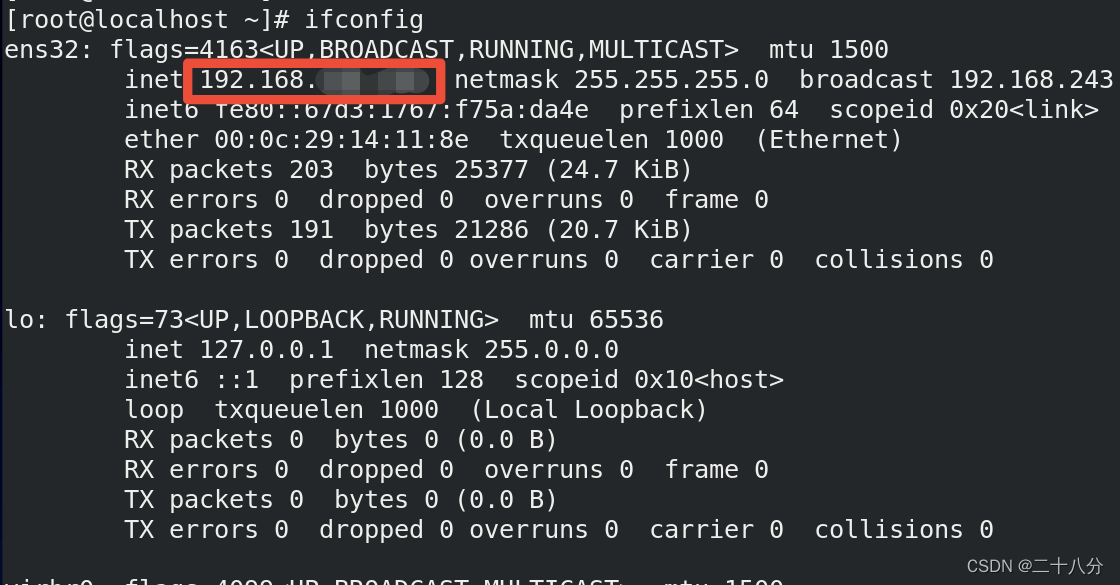
第三步:连通测试:打开Windows系统的黑窗口,按住Windows+R,输入cmd,打开之后直接输入ping+IP地址(为第二步里面的IP地址),显示如图所示,即为连通成功;
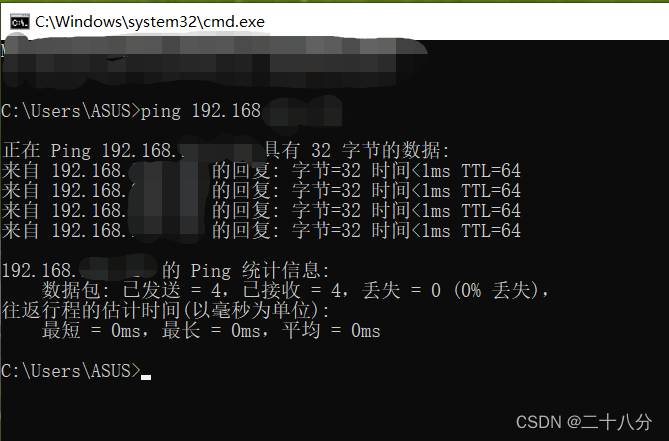
第四步:提前下载安装好Xmanager5,打开里面的xshell.exe(不止这一种远程登录工具,也可使用其他的),
即可看到会话窗口,点击新建,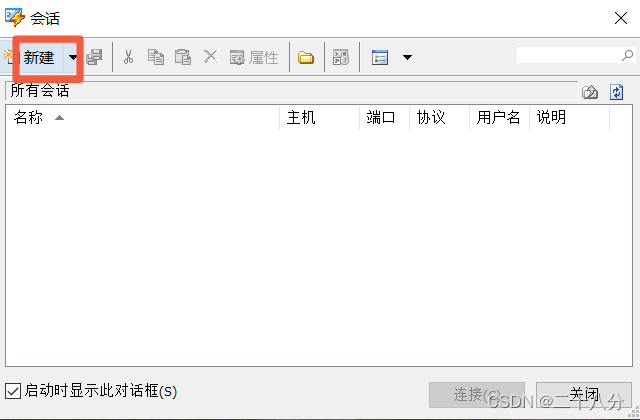
为了方便区分,可将名称改为 CentOS 虚拟机,协议和端口号不可以更改,将主机修改为IP地址(为第二步里的IP地址),点击确定,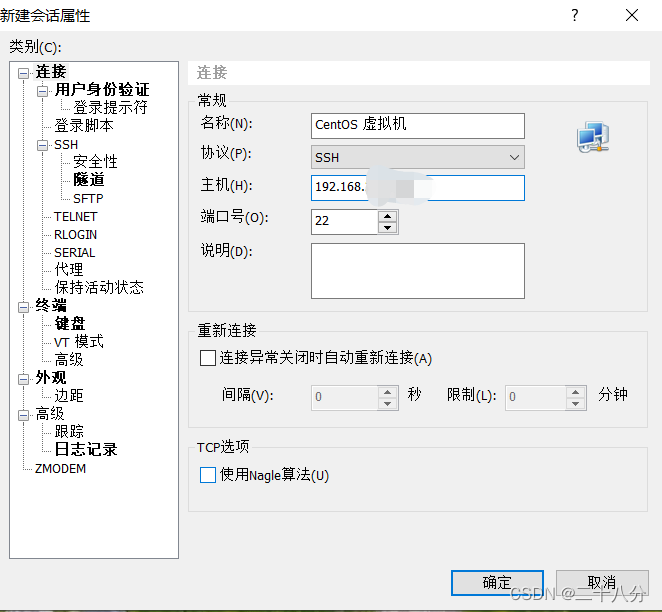
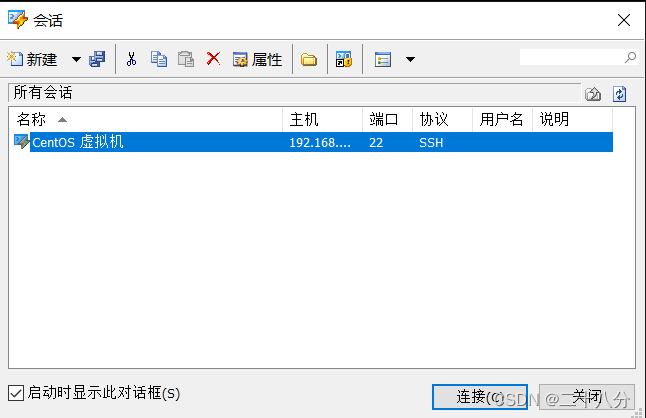
选择CentOS 虚拟机,点击连接,
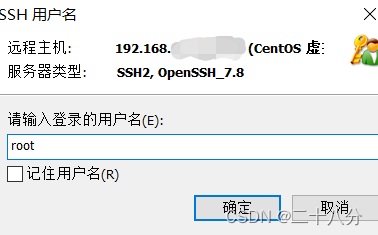
 输入root(为超级管理员),点击确定,
输入root(为超级管理员),点击确定,
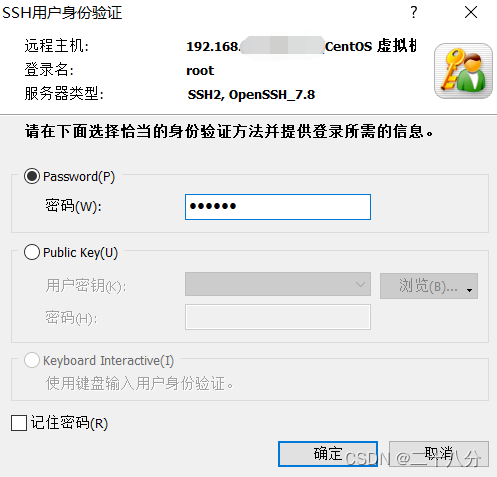
输入root的密码,再点击确定。(注意:如果登录失败,可以试试使用普通用户登录,且虚拟机登录的用户也需要是普通用户,虚拟机和xshell的用户需要保持一致。)
如图所示,即为远程登录Linux成功 。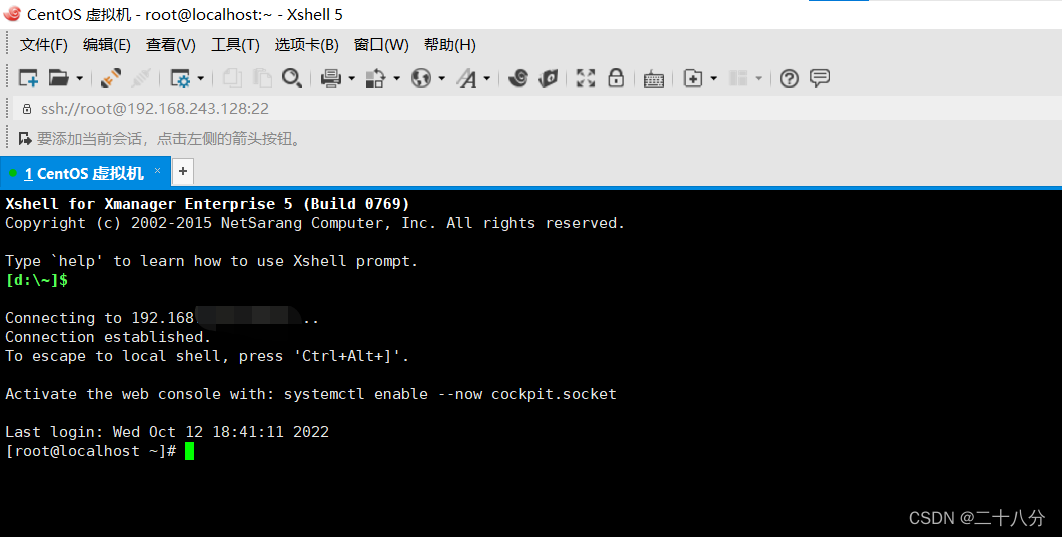
Linux远程传输文件—xtfp6
4.3 远程上传下载文件-Xftp6
4.3.1 Xftp介绍
是一个基于 windows 平台的功能强大的 SFTP、FTP 文件传输软件。使用了 Xftp 以后,windows 用户能安全地在 UNIX/Linux 和 Windows PC 之间传输文件

软件下载方法在前面说过了
4.3.2 Xftp6安装
步骤一:以管理员的身份运行 这个安装包
点击下一步
接受协议,点击下一步
用户名和公式名称默认,点击下一步
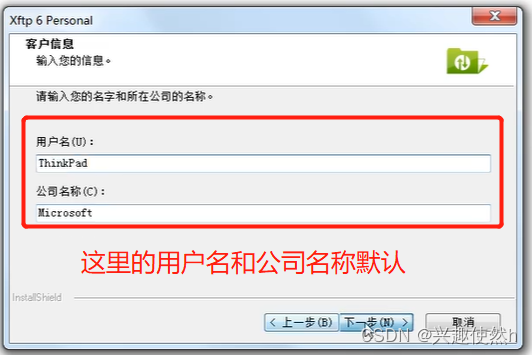
步骤二:选择安装目录,点击下一步
点击安装

安装成功,点击完成
到这里 Xftp6 就安装成功了!
4.3.3 Xftp6的配置和使用
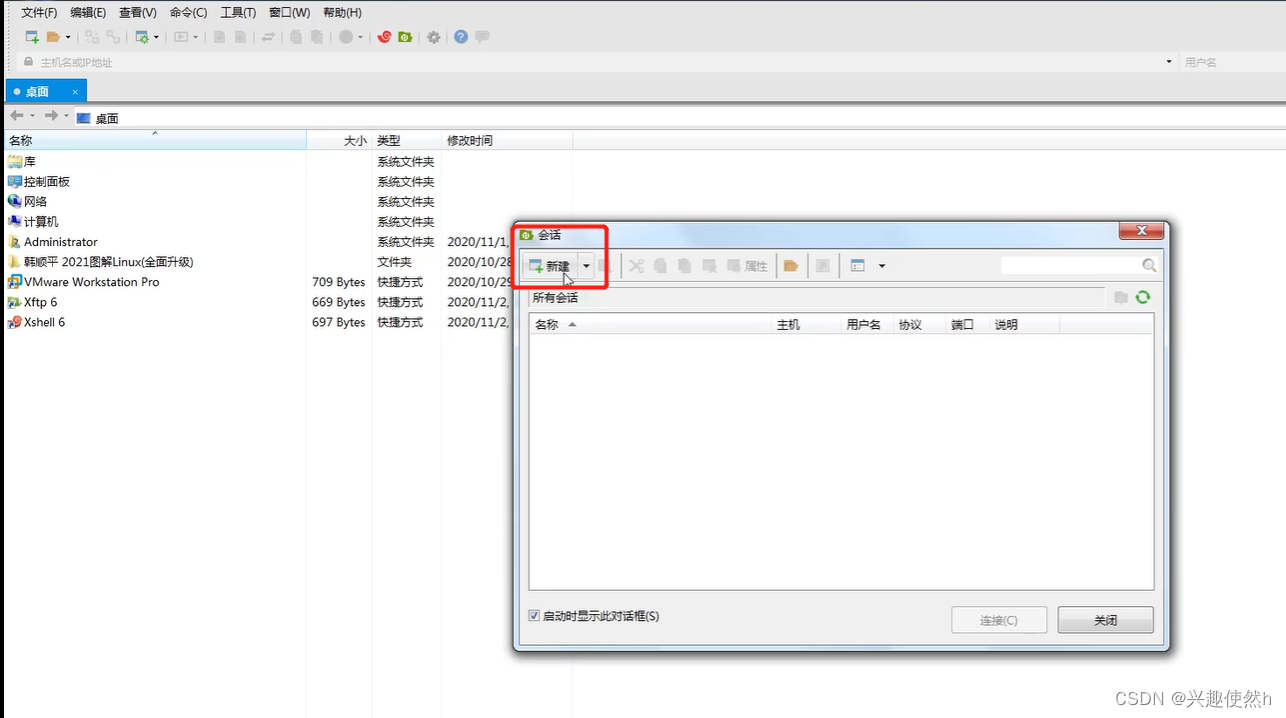
步骤一:双击打开 Xftp6,点击新建
步骤二:输入会话名称,可以随意 => 输入主机地址,要连接的虚拟机的IP地址 => 协议选择:SFTP => 端口号选则:22。点击确定。
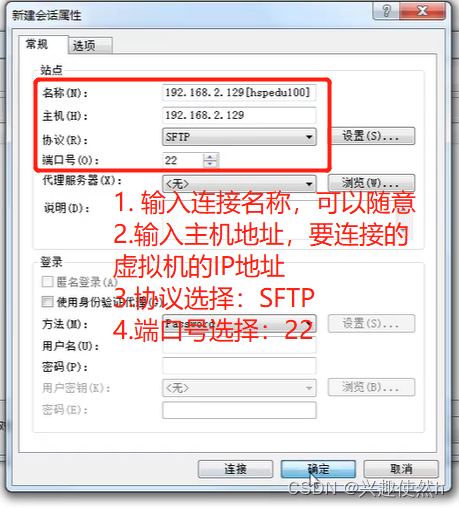
步骤三:选择刚刚创建的会话,点击连接
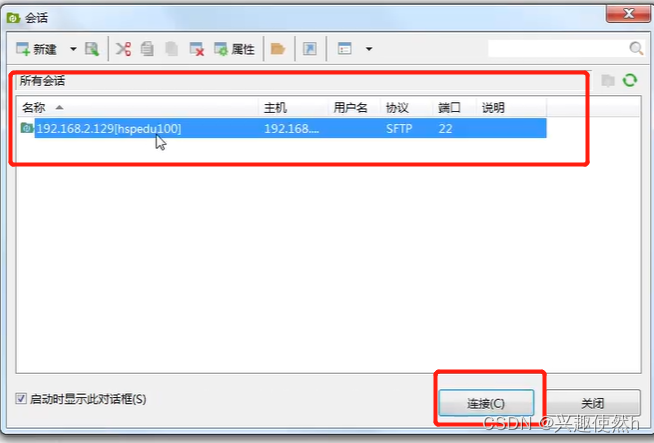
点击一次性接受
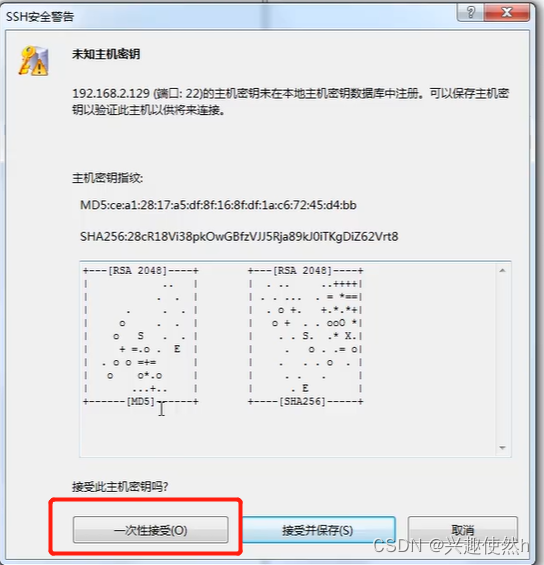
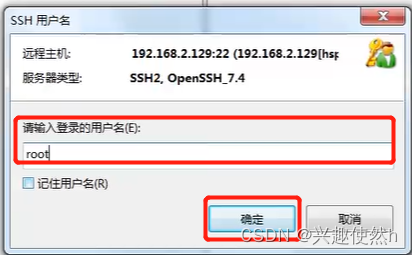
**步骤四:输入用户名,点击确定。输入密码,点击确定。(*这里的用户名和密码,就是你虚拟机的用户名密码,*账号为:root,密码为:root)
这个时候就连接成功了。左边为我们 Windows 的文件目录,而右边的是 虚拟机Linux 的文件目录。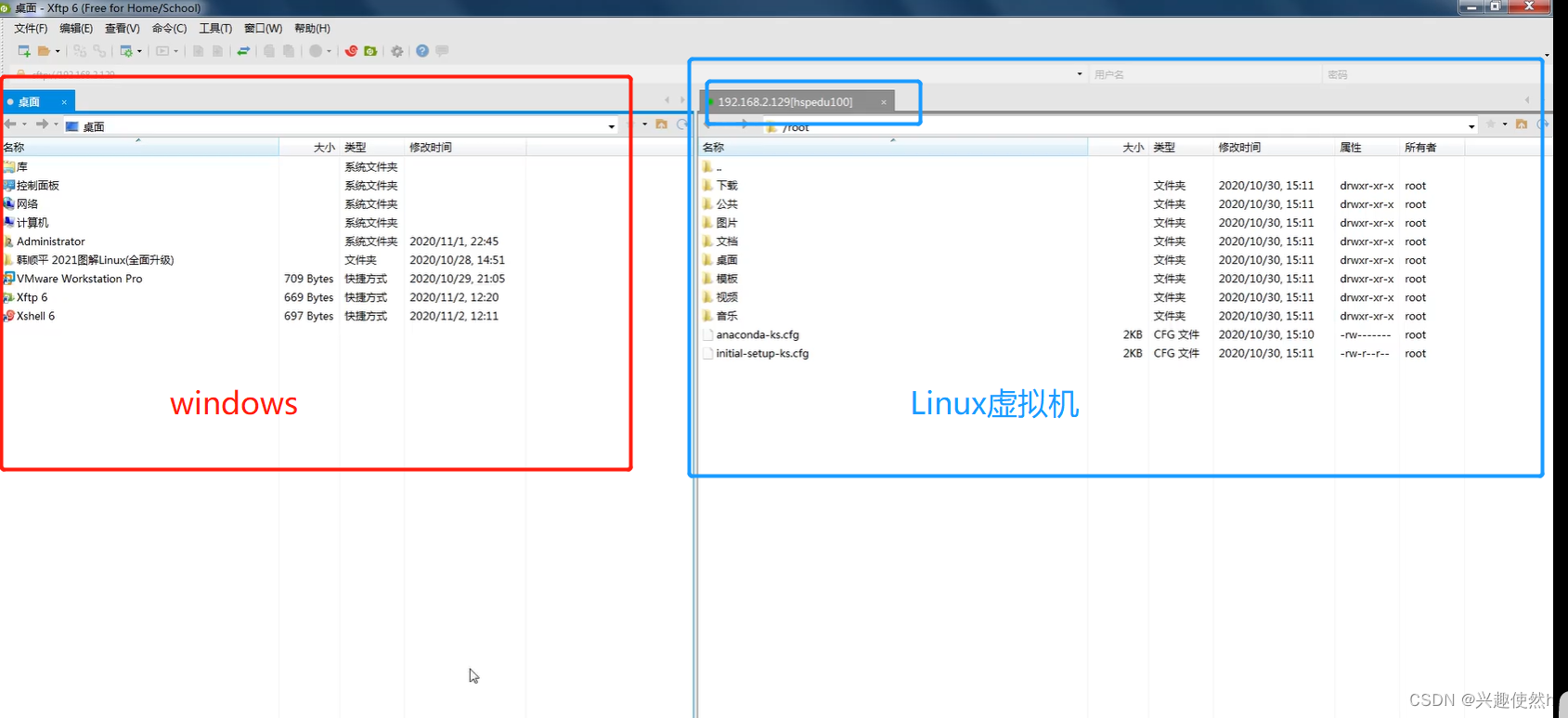
4.3.4 使用 Xftp6 传输文件
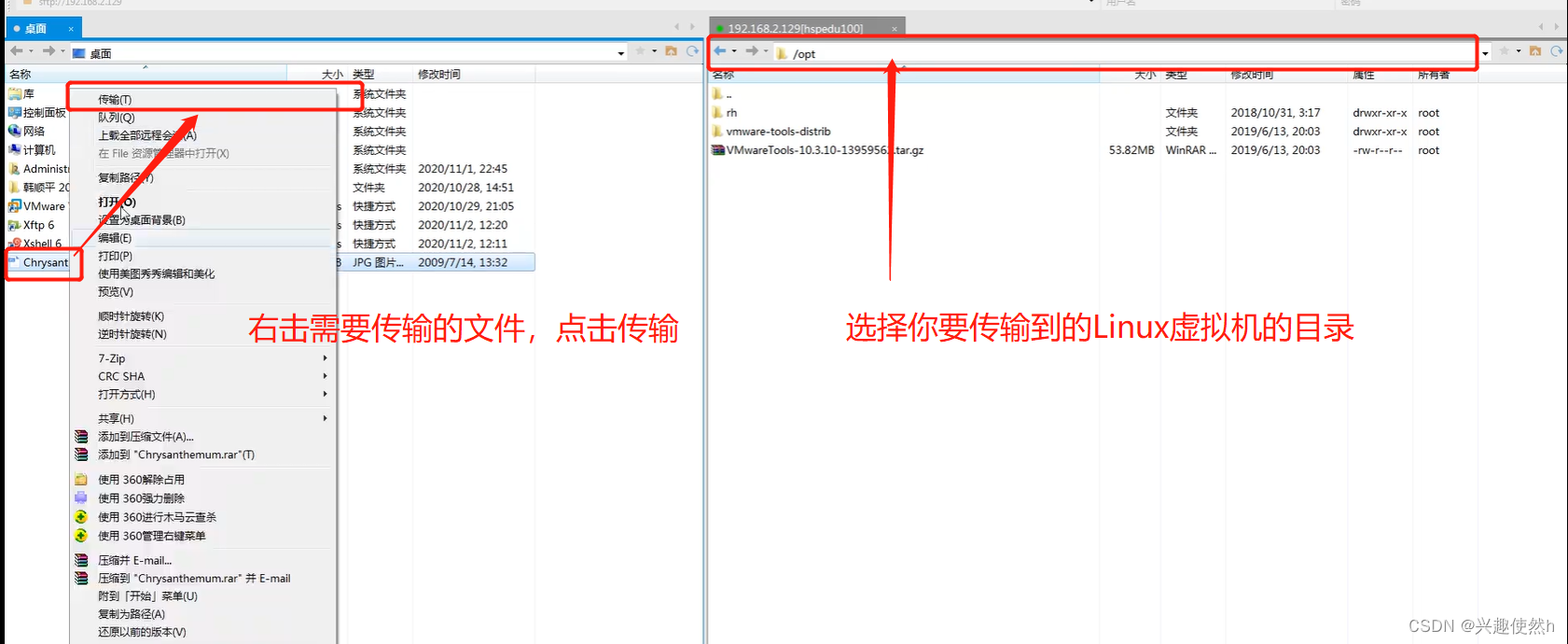
鼠标右击 需要传输到Linux虚拟机的文件,点击传输。
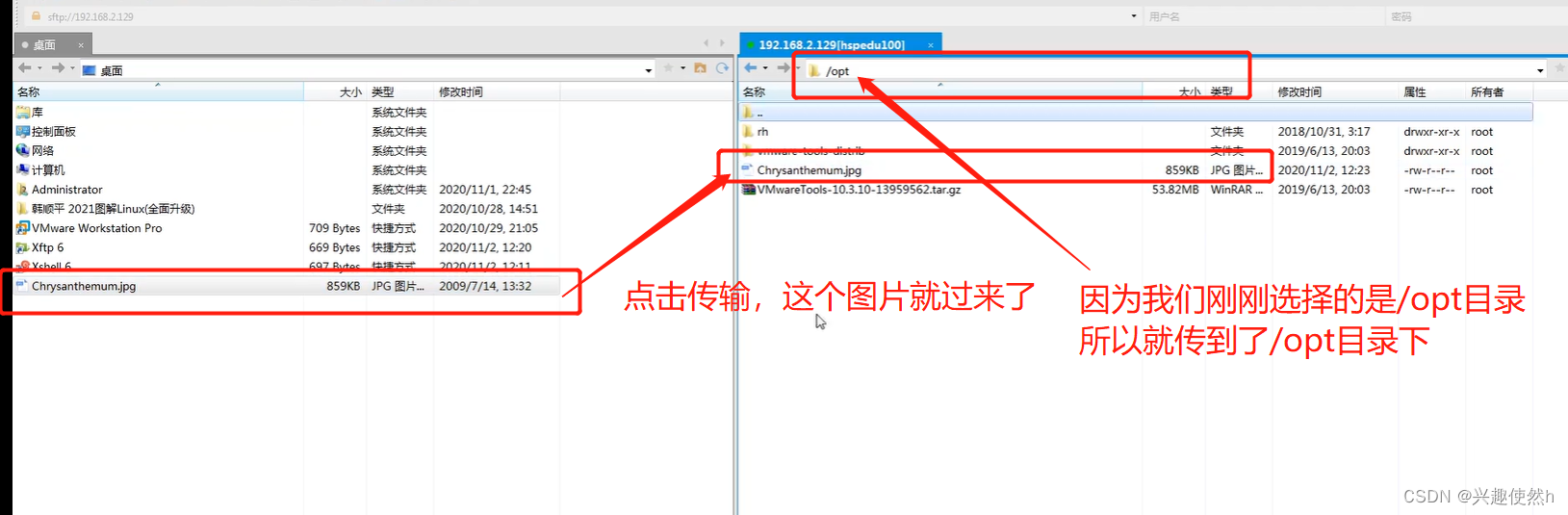
此时打开Linux虚拟机,进入/opt目录下,就可以查看到这张图片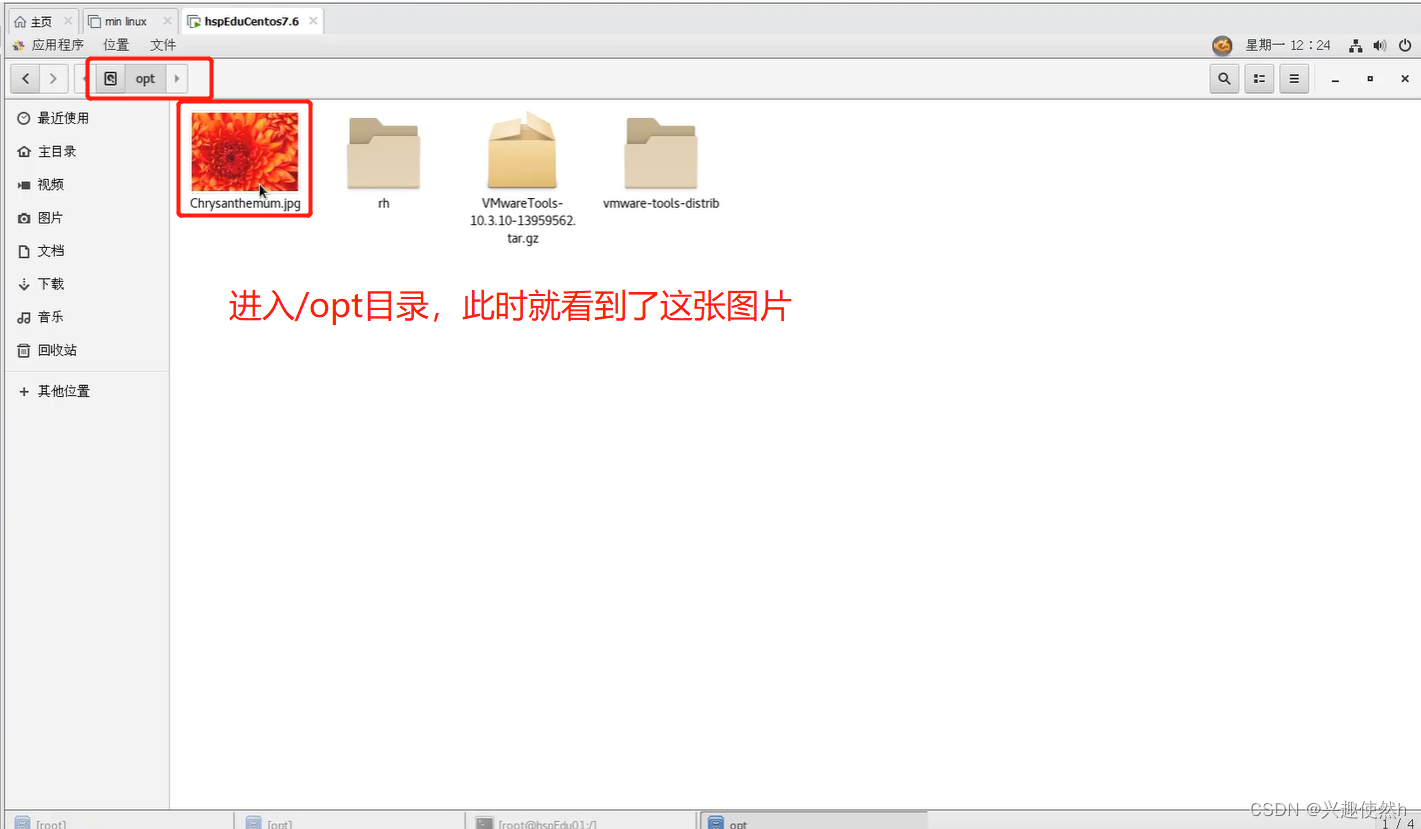
到这,我们的文件传输就成功了。同样的道理,也可以把Linux中的文件传输到Windows。
Linux中的记事本软件–vim
一、VIM编辑器
1)vi概述
vi(visual editor)编辑器通常被简称为vi,它是Linux和Unix系统上最基本的文本编辑器,类似于Windows 系统下的notepad(记事本)编辑器。
2)vim编辑器
Vim(Vi improved)是vi编辑器的加强版,比vi更容易使用。vi的命令几乎全部都可以在vim上使用。
3)vim编辑器的安装
☆ 已安装
Linux通常都已经默认安装好了 vi 或 Vim 文本编辑器,我们只需要通过vim命令就可以直接打开vim编辑器了,如下图所示:
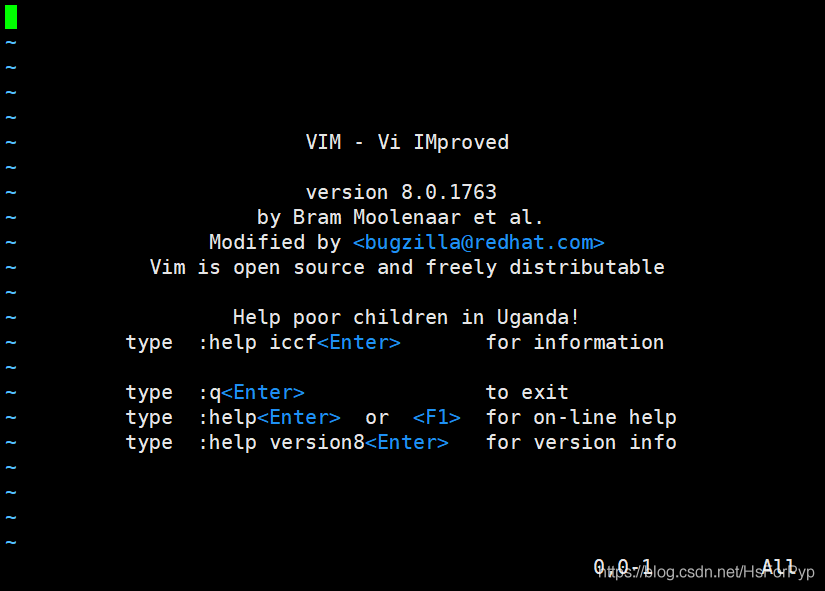
☆ 未安装
有些精简版的Linux操作系统,默认并没有安装vim编辑器(可能自带的是vi编辑器)。当我们在终端中输入vim命令时,系统会提示"command not found"。
解决办法:有网的前提下,可以使用yum工具对vim编辑器进行安装
1 | # 安装vim且询问是否时自动选择yes |
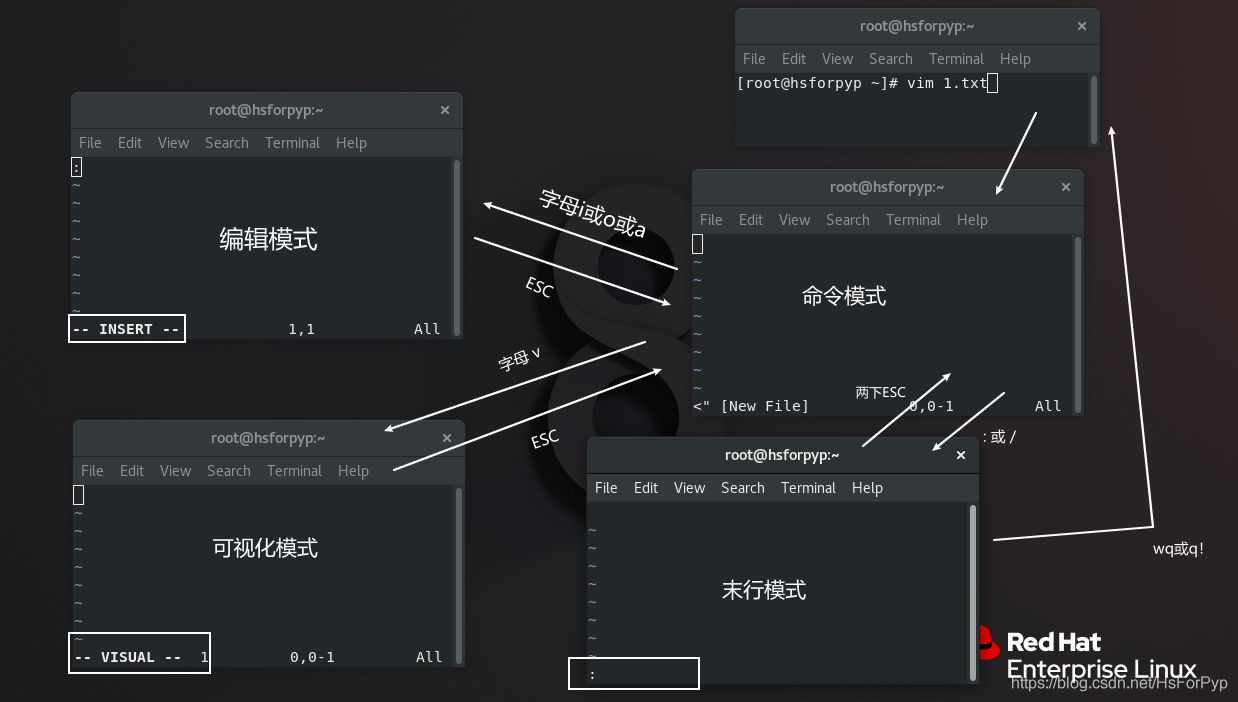
4)vim编辑器的四种模式(!)
☆ 命令模式
使用VIM编辑器时,默认处于命令模式。在该模式下可以移动光标位置,可以通过快捷键对文件内容进行复制、粘贴、删除等操作。
☆ 编辑模式或输入模式
在命令模式下输入小写字母a或小写字母i即可进入编辑模式,在该模式下可以对文件的内容进行编辑
☆ 末行模式
在命令模式下输入冒号:即可进入末行模式,可以在末行输入命令来对文件进行查找、替换、保存、退出等操作
☆ 可视化模式
可以做一些列选操作(通过方向键选择某些列的内容,类似于Windows鼠标刷黑)
二、VIM四种模式的关系
1)VIM四种模式
- 命令模式
- 编辑模式
- 末行模式
- 可视化模式
2)VIM四种模式的关系
三、VIM编辑器的使用
1)使用vim打开文件
基本语法:
1 | # vim 文件名称 |
① 如果文件已存在,则直接打开
② 如果文件不存在,则vim编辑器会自动在内存中创建一个新文件
案例:使用vim命令打开readme.txt文件
1 | # vim readme.txt |
2)vim编辑器保存文件
在任何模式下,连续按两次Esc键,即可返回到命令模式。然后按冒号:,进入到末行模式,输入wq,代表保存并退出。

3)vim编辑器强制退出(不保存)
在任何模式下,连续按两次Esc键,即可返回到命令模式。然后按冒号:,进入到末行模式,输入q!,代表强制退出但是不保存文件。

vim命令大全
1.vim介绍
vim编辑器有三种模式:
命令模式、编辑模式、末行模式
模式间切换方法:
(1)命令模式下,输入:后,进入末行模式
(2)末行模式下,按esc慢退、按两次esc快退、或者删除所有命令,可以回到命令模式
(3)命令模式下,按下i、a等键,可以计入编辑模式
(4)编辑模式下,按下esc,可以回到命令模式
vim打开文件:
| Vi 使用的选项 | 说 明 |
|---|---|
| vim filename | 打开或新建一个文件,并将光标置于第一行的首部 |
| vim -r filename | 恢复上次 vim 打开时崩溃的文件 |
| vim -R filename | 把指定的文件以只读方式放入 Vim 编辑器中 |
| vim + filename | 打开文件,并将光标置于最后一行的首部 |
| vi +n filename | 打开文件,并将光标置于第 n 行的首部 |
| vi +/pattern filename | 打幵文件,并将光标置于第一个与 pattern 匹配的位置 |
| vi -c command filename | 在对文件进行编辑前,先执行指定的命令 |
2.命令模式
1.光标移动
| 快捷键 | 功能描述 |
|---|---|
| jkhl | 基本上下左右 |
| gg | 光标移动到文档首行 |
| G | 光标移动到文档尾行 |
| ^或_ | 光标移动到行首第一个非空字符 |
| home键或0或者g0 | 光标移动到行首第一个字符 |
| g_ | 光标移动到行尾最后一个非空字符 |
| end或或者 g 或者g或者g | 光标移动到行尾最后一个字符 |
| gm | 光标移动到当前行中间处 |
| b/B | 光标向前移动一个单词(大写忽略/-等等特殊字符) |
| w/W | 光标向后移动一个单词(大写忽略/-等等特殊字符) |
| e/E | 移到单词结尾(大写忽略/-等等特殊字符) |
| ctrl+b或pageUp键 | 翻屏操作,向上翻 |
| ctrl+f或pageDn键 | 翻屏操作,向下翻 |
| 数字+G | 快速将光标移动到指定行 |
| `. | 移动到上次编辑处 |
| 数字+上下方向键 | 以当前光标为准,向上/下移动n行 |
| 数字+左右方向键 | 以当前光标为准,向左/右移动n个字符 |
| H | 移动到屏幕顶部 |
| M | 移动到屏幕中间 |
| L | 移动到屏幕尾部 |
| z+Enter键 | 当前行在屏幕顶部 |
| z+ . | 当前行在屏幕中间 |
| z+ - | 当前行在屏幕底部 |
| shift+6 | 光标移动到行首 |
| shift+4 | 光标移动到行尾 |
| - | 移动到上一行第一个非空字符 |
| + | 移动到下一行第一个非空字符 |
| ) | 向前移动一个句子 |
| ( | 向后移动一个句子 |
| } | 向前移动一个段落 |
| { | 向前移动一个段落 |
| count l | 移动到count 列 |
| counth | 向左移动count 字符 |
| countl | 向右移动count字符 |
| countgo | 移动到count字符 |
2.选中内容
| 快捷键 | 功能描述 |
|---|---|
| v | 进行字符选中 |
| V 或shift+v | 进行行选中 |
| gv | 选中上一次选择的内容 |
| o | 光标移动到选中内容另一处结尾 |
| O | 光标移动到选中内容另一处角落 |
| ctr + V | 进行块选中 |
3.复制(配合粘贴命令p使用)
| 快捷键 | 功能描述 |
|---|---|
| y | 复制已选中的文本到剪贴板 |
| n+yy | 复制光标所在行,此命令前可以加数字 n,可复制多行 |
| yw | 复制光标位置的单词 |
| ctrl+v + 方向键+yy | ctrl+v,并按方向键选中区块,按下yy复制 |
4.剪切
| 快捷键 | 功能描述 |
|---|---|
| dd | 剪切光标所在行 |
| 数字+dd | 以光标所在行为准(包含当前行),向下剪切指定行数 |
| D | 剪切光标所在行 |
5.粘贴
| 快捷键 | 功能描述 |
|---|---|
| p | 将剪贴板中的内容粘贴到光标后 |
| P(大写) | 将剪贴板中的内容粘贴到光标前 |
6.删除
| 快捷键 | 功能描述 |
|---|---|
| x | 删除光标所在位置的字符 |
| X(大写) | 删除光标前一个字符 |
| dd | 删除光标所在行,删除之后,下一行上移 |
| D | 删除光标位置到行尾的内容,删除之后,下一行不上移 |
| ndd | 删除当前行(包括此行)后 n 行文本 |
| dw | 移动光标到单词的开头以删除该单词 |
| dG | 删除光标所在行一直到文件末尾的所有内容 |
| :a1,a2d | 删除从 a1 行到 a2 行的文本内容 |
7.撤销/恢复
| 快捷键 | 功能描述 |
|---|---|
| u | 撤销 |
| ctrl+r | 恢复 |
| U(大写) | 撤销所有编辑 |
8.字符转换
| 快捷键 | 功能描述 |
|---|---|
| ~ | 转换大小写 |
| u | 变成小写 |
| U | 变成大写 |
9.编辑命令的快捷键
| 快捷键 | 功能描述 |
|---|---|
| ↑或ctr + p | 上一条命令 |
| ↓或ctr + n | 下一条命令 |
| ctr + b | 移动到命令行开头 |
| ctr + e | 移动到命令行结尾 |
| ctr + ← | 向左一个单词 |
| ctr + → | 向右一个单词 |
3.末行模式(: xxx命令)
1.保存/退出文件操作
| 命令 | 功能描述 |
|---|---|
| :wq | 保存并退出 Vim 编辑器 |
| :wq! | 保存并强制退出 Vim 编辑器 |
| :q | 不保存就退出 Vim 编辑器 |
| :q! | 不保存,且强制退出 Vim 编辑器 |
| :w | 保存但是不退出 Vim 编辑器 |
| :w! | 强制保存文本 |
| :w filename | 另存到 filename 文件 |
| x! | 保存文本,并退出 Vim 编辑器 |
| ZZ | 直接退出 Vim 编辑器 |
2.查找:“/关键词”
在查找结果中,用N、n可以切换上下结果;输入nohl,可以取消高亮
| 快捷键 | 功能描述 |
|---|---|
| /abc | 从光标所在位置向前查找字符串 abc |
| /^abc | 查找以 abc 为行首的行 |
| /abc$ | 查找以 abc 为行尾的行 |
| ?abc | 从光标所在位置向后查找字符串 abc |
| n或; | 向同一方向重复上次的查找指令 |
| N或, | 向相反方向重复上次的查找指定 |
3.替换
| 快捷键 | 功能描述 |
|---|---|
| r | 替换光标所在位置的字符 |
| R | 从光标所在位置开始替换字符,其输入内容会覆盖掉后面等长的文本内容,按“Esc”可以结束 |
:s/a1/a2 |
替换当前光标所在行第一处符合条件的内容 |
:s/a1/a2/g |
替换当前光标所在行所有的 a1 都用 a2 替换 |
:%s/a1/a2 |
替换所有行中,第一处符合条件的内容 |
:%s/a1/a2/g |
替换所有行中,所有符合条件的内容 |
:n1,n2 s/a1/a2 |
将文件中 n1 到 n2 行中第一处 a1 都用 a2 替换 |
:n1,n2 s/a1/a2/g |
将文件中 n1 到 n2 行中所有 a1 都用 a2 替换 |
4.行号显示:“: set nu”;
- 行号显示
:set nu - 取消行号显示:
:set nonu
5.文件切换
使用vim打开多个文件后,在末行模式下可以进行切换。
- 查看当前已经打开的所有文件:
:files(%a表示激活状态,#表示上一个打开的文件) - 切换到指定文件:
:open 文件名 - 切换到上一个文(back previous):
:bp - 切换到下一个文件(back next):
:bn
4.编辑模式
| 快捷键 | 功能描述 |
|---|---|
| i | 在当前光标所在位置插入,光标后的文本相应向右移动 |
| I | 在光标所在行的行首插入,行首是该行的第一个非空白字符,相当于光标移动到行首执行 i 命令 |
| o | 在光标所在行的下插入新的一行。光标停在空行首,等待输入文本 |
| O(大写) | 在光标所在行的上插入新的一行。光标停在空行的行首,等待输入文本 |
| a | 在当前光标所在位置之后插入 |
| A | 在光标所在行的行尾插入,相当于光标移动到行尾再执行 a 命令 |
| esc键 | 退出编辑模式 |
5.扩展
1.代码颜色显示:“:syntax on/off”
2.vim内置计算器:
a.进入编辑模式
b.按“ctrl+r,光标变成引号,,输入=,光标转到最后一行
c.输入需要计算的内容,按下enter后,计算结果回替代上一步中的引号,光标恢复
3.vim的配置
a.文件打开时,末行模式下输入的配置为临时配置,关闭文件后配置无效
b.修改个人配置文件,可以永久保存个人配置(~/.vimrc,如果没有可以自行创建)
c.修改全局配置文件,对每个用户生效(vim自带,/etc/vimrc)
注:个人配置文件优先级更高,当个人配置和全局配置发生冲突时,系统以当前用户的个人配置文件为准
4.异常退出
在编辑文件后,未正常保存退出时,会产生异常退出交换文件(.原文件名.swp)
将交换文件删除后,再次打开文件时,无提示:“#rm -f .原文件名.swp”
5.别名机制:自定义指令
Linux中,存在一个别名映射文件: ~/.bashrc
修改文件内容,可以自定义指令,重新登录账号后生效
6.文件快捷方式
对于深层文件,可以创建文件快捷方式,便于后续操作:#ln -s 源路径 新路径
\7. 退出方式
(1)在vim中退出文件编辑模式,可以使用:q或者:wq
(2)建议使用:x:使用效果等同于wq,如果文件有改动则先保存后退出;但是如果文件没有做修改,会直接退出,不会修改文件更新时间,避免用户混淆文件的修改时间
五、可视化模式
1)如何进入到可视化模式
在命令模式中,直接按ctrl + v(可视块)或V(可视行)或v(可视),然后按下↑ ↓ ← →方向键来选中需要复制的区块,按下y 键进行复制(不要按下yy),最后按下p 键粘贴
退出可视模式按下Esc
2)可视化模式复制操作
第一步:在命令模式下,直接按小v,进入可视化模式
第二步:使用方向键↑ ↓ ← →选择要复制的内容,然后按y键
第三步:移动光标,停在需要粘贴的位置,按p键进行粘贴操作
3)为配置文件添加#多行注释(!)
第一步:按Esc退出到命令模式,按gg切换到第1行
第二步:然后按Ctrl+v进入到可视化区块模式(列模式)
第三步:在行首使用上下键选择需要注释的多行
第四步:按下键盘(大写)“I”键,进入插入模式(Shift + i)
第五步:输入#号注释符
第六步:输入完成后,连续按两次Esc即可完成添加多行注释的过程
4)为配置文件去除#多行注释(!)
第一步:按Esc退出到命令模式,按gg切换到第1行
第二步:然后按Ctrl+v进入可视化区块模式(列模式)
第三步:使用键盘上的方向键的上下选中需要移除的#号注释
第四步:直接按Delete键即可完成删除注释的操作
六、VIM编辑器实用功能
1)代码着色
之前说过vim 是vi 的升级版本,其中比较典型的区别就是vim 更加适合coding,因为vim比vi 多一个代码着色的功能,这个功能主要是为程序员提供编程语言升的语法显示效果,如下:
第一步:定义后缀名为网页文件的代码文件
1 | # vim index.php |
第二步:编写对应的PHP代码
1 |
|
在VIM编辑器中,我们可以通过:syntax on或:syntax off开启或关闭代码着色功能。
2)异常退出解决方案
什么是异常退出:在编辑文件之后并没有正常的去wq(保存退出),而是遇到突然关闭终端或者断电的情况,则会显示下面的效果,这个情况称之为异常退出:
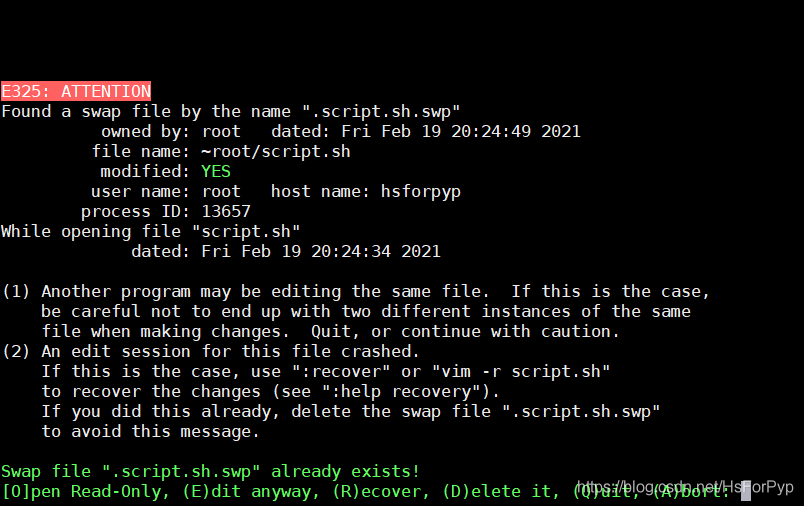
温馨提示:每个文件的异常文件都会有所不同,其命名规则一般为
.文件名称.swp
解决办法:将交换文件(在编程过程中产生的临时文件)删除掉即可【在上述提示界面按下D 键或者使用rm 指令删除交换文件】
1 | # rm .1.php.swp |
3)退出vim编辑器
回顾:在vim中,退出正在编辑的文件可以使用:q或者:wq除了上面的这个语法之外,vim 还支持另外一个保存退出(针对内容)方法:x
① :x在文件没有修改的情况下,表示直接退出(等价于:q),在文件修改的情况下表示保存并退出(:wq)
② 如果文件没有被修改,但是使用wq 进行退出的话,则文件的修改时间会被更新;但是如果文件没有被修改,使用x 进行退出的话,则文件修改时间不会被更新的;主要是会混淆用户对文件的修改时间的认定。
Linux中的关机与重启命令
1. 关机重启命令汇总
| halt | 关机 | root用户 | halt:只关闭系统,电源还在运行 halt -p:关闭系统,关闭电源(先执行halt,再执行poweroff) |
|---|---|---|---|
| poweroff | 关机 | root用户 | poweroff会发送一个关闭电源的信号给acpi |
| reboot | 重启 | root用户 | |
| shutdown | -h:关机 -r:重启 -c:取消shutdown操作 | root用户 | shutdown实际上是调用init 0, init 0会cleanup一些工作然后调用halt或者poweroff shutdown -r now:一分钟后重启 shutdown -r 05:30:最近的5:30重启 shutdown -r +10:十分钟后重启 |
| init | init 0:关机 init 6:重启 | root用户 | init:切换系统的运行级别 |
| systemctl | systemctl halt [-i]:关机 systemctl poweroff [-i]:关机 systemctl reboot [-i]:重启 | 普通用户 超级用户 | 普通用户需要加-i root用户不需要加-i |
在关机或者重启之前,执行3至4次sync,将在内存中还未保存到硬盘的数据更新到硬盘中,否则会造成数据的丢失。执行sync时要以管理员的身份运行,因为管理员具有所有文件的权限,而普通用户只具有自己的部分文件的权限。
最经常使用的关机重启的命令是shutdown,因此下面详细学习的使用。
2.shutdown命令
基本格式:shutdown [选项] [时间] [警告信息]
选项:
- -h:关机
- -r:重启
- -c:取消shutdown执行的关机或者重启命令
- -k:不关机,发出警告
时间:
- shutdown:一分钟后关机(默认)
- shutdown now:立刻关机
- shutdown +10:10分钟后关机
- shutdown 5:00:5点关机
示例:
shutdown -r now:一分钟后重启
shutdown -r 05:30:最近的5:30重启
shutdown -r +10:十分钟后重启
shutdown -h now:一分钟后关机
shutdown -h 05:30:最近的5:30关机
shutdown -h +10:十分钟后关机
shutdown -c:取消上面的关机重启操作
shutdown -k +10 “I will shutdown in 10 minutes”:10分钟后并不会真的关机,但是会把警告信息发给所有的用户。
3.sync命令:
sync :linux同步数据命令,将所有未写的系统缓冲区写到磁盘中,包含已修改的 i-node、已延迟的块 I/O 和读写映射文件。如果不去手动的输入sync命令来真正的去写磁盘,linux系统也会周期性的去sync数据。
使用场景:
1.在 关机或者开机之前最好多执行这个几次,以确保数据写入硬盘。
2.挂载时,需要很长时间的操作动作(比如,cp 大文件,检测文件),在这个动作之后接sync。
3.卸载U盘或其他存储设备,需要很长时间,使用sync。
关机与重启命令
1.1 基本介绍
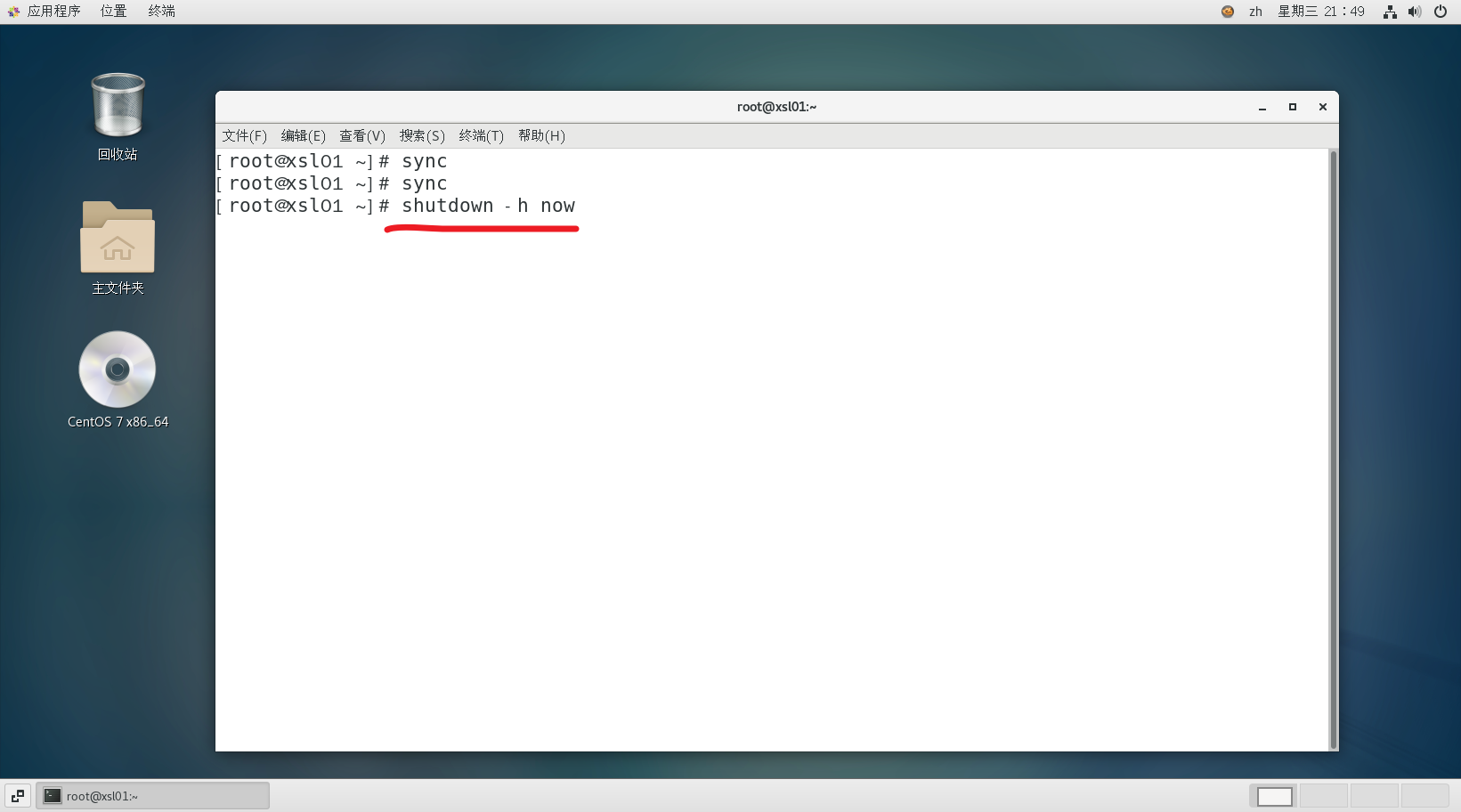
shutdown -h now-----立刻进行关机shutdown -h 1--------“hello, 1分钟后会关机了”shutdown -r now------立刻重新启动计算机halt-----------------------关机,作用和上面一样reboot--------------------立刻重启计算机sync-----------------------把内存的数据同步到磁盘
1.2 注意细节
- 不管是重启系统还是关闭系统,首先要运行 sync 命令,把内存中的数据写到磁盘中
- 目前的 shutdown / reboot / halt 等命令均已经在关机前进行了 sync 【特别提醒,小心驶得万年船】
2.用户登录与注销
2.1 基本介绍
- 登录时尽量少用 root 账号登录,因为它是系统管理员,最大的权限,避免操作失误,可以利用普通用户登录,登录后再
su-用户名命令来切换成系统管理员身份 - 在提示符下输入 logout ,即可注销用户
2.2 使用细节
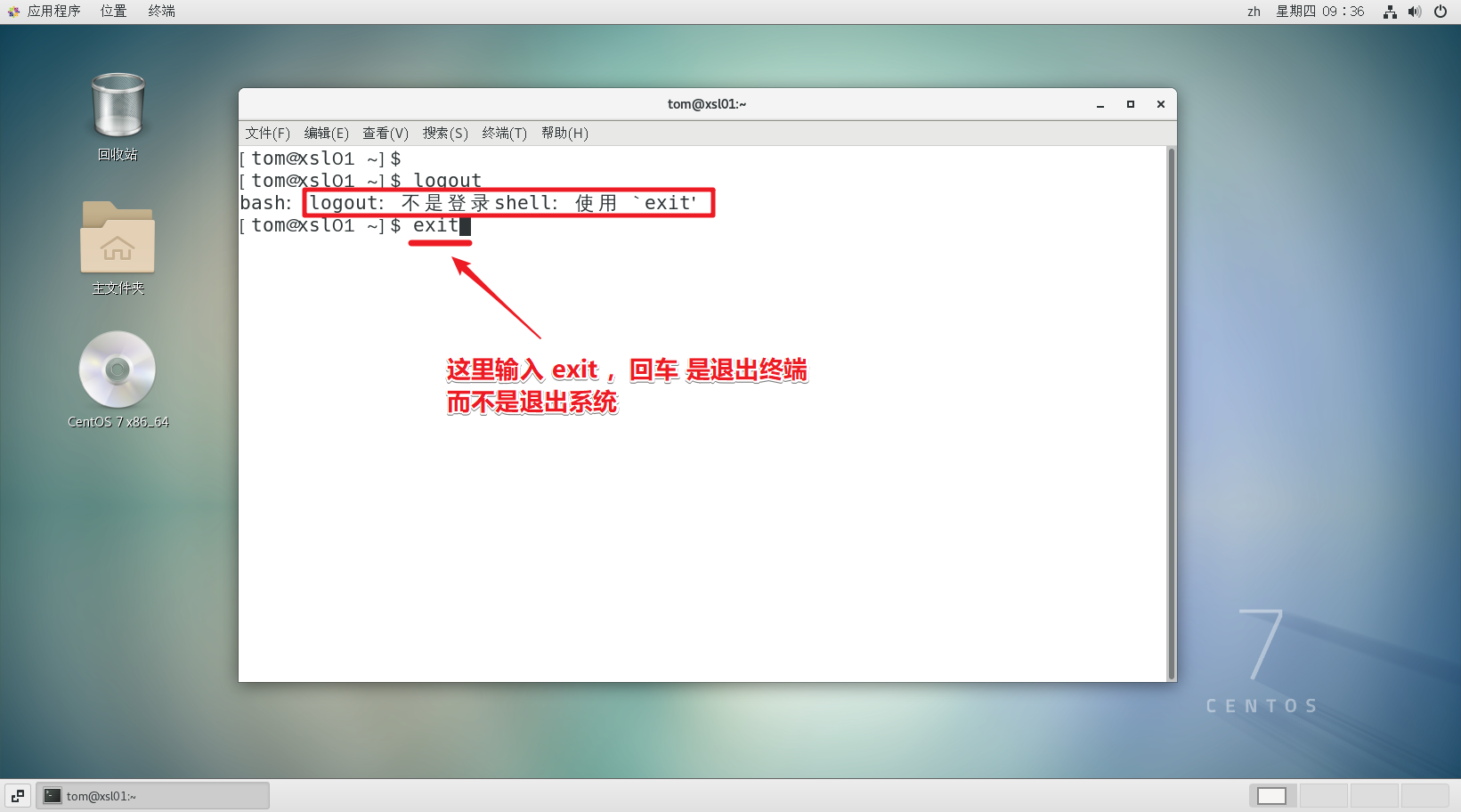
- logout 注销指令在图形运行级别无效,在运行级别 3 下有效
- 运行级别这个概念,后面再介绍
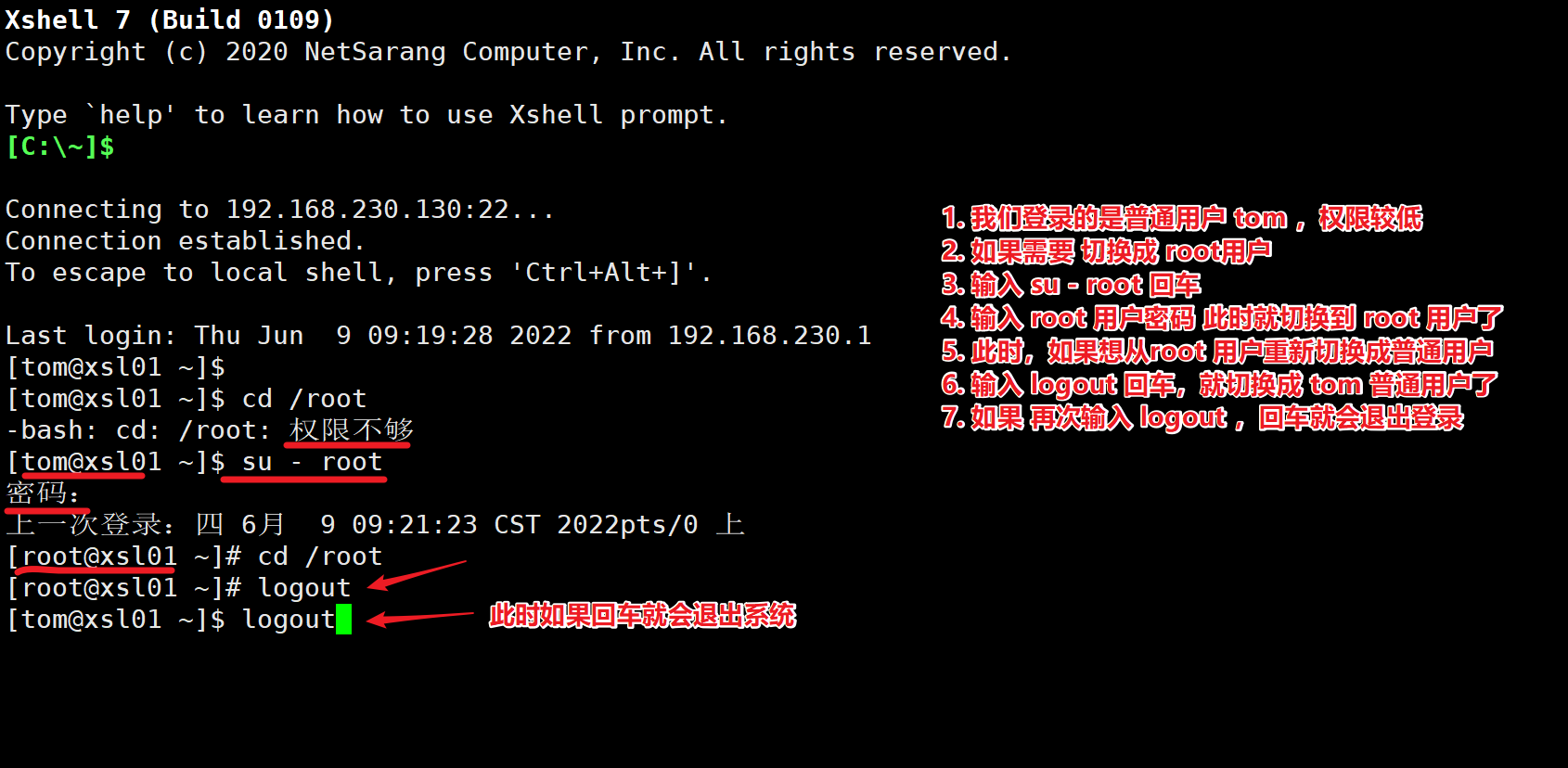
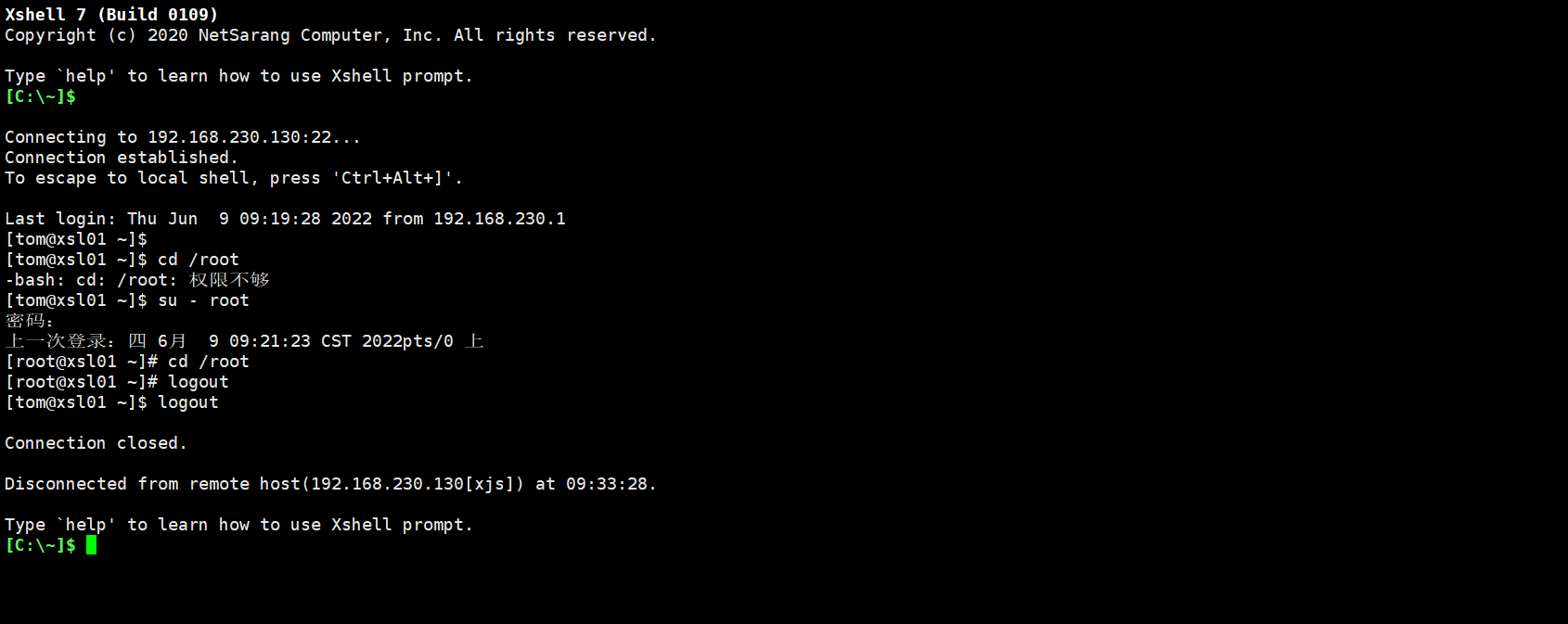
-----logout 注销指令在图形运行级别无效-----
🐧用户和组的概念
🌏用户的概念
有的人喜欢说“用户”,有的人喜欢说“账号”,再Linux系统中,他们是指同一个概念:使用Linux系统的人,他的信息必须事先已经在Linux系统中登记好,
在Linux中,创建(即登记)一个用户时需要提供如下信息:
1、用户名:也叫账号,合法的账号由AZ,az,09,-和_组成,账号长度介于132.在Linux系统中用户名是唯一的,用户名主要用于身份鉴别。
2、口令:或称为密码,主要用于身份鉴别,一个好的口令最好同时包含大小写字母、数字和其他字符,长度建议大于6 注意:密码中字符的大小写是由区分的
3、用户ID号:简称为UID,犹如人的身份证号,
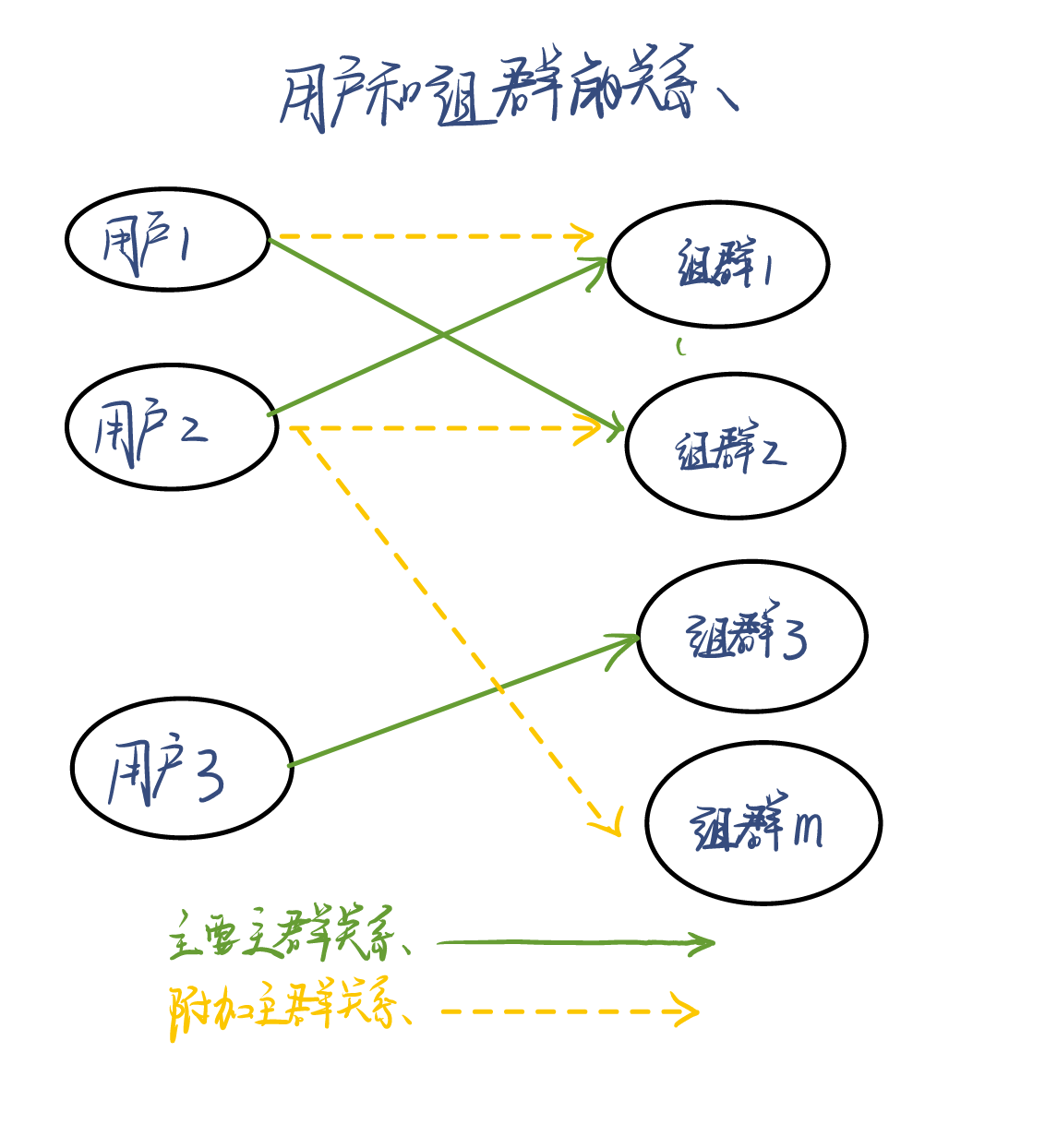
4、组:每一个用户只能归属于一个主要组群,但是可以同时归属于多个附加组群。给用户分组主要是便于管理同一类用户的权限,例如赋予一个组某种权限,那么这个组所有的用户自动拥有该权限
5、家目录:使用户登录之后默认进入的目录,如果不特别指定,用户的家目录就是/home/<账号>,例如创建用户Gremmie102,那么默认的家目录就是/home/Gremmie102。root用户的家目录有些特别,默认是/root
6、登录shell:用户登录Linux的过程中,会自动执行一系列的程序,其中最后执行的那个程序成为shell程序。shell以为“壳”,可以想象为包裹在Linux系统外面的壳,用户登录之后就一直在这个壳中,用户输入的任何命令都由Shell代为执行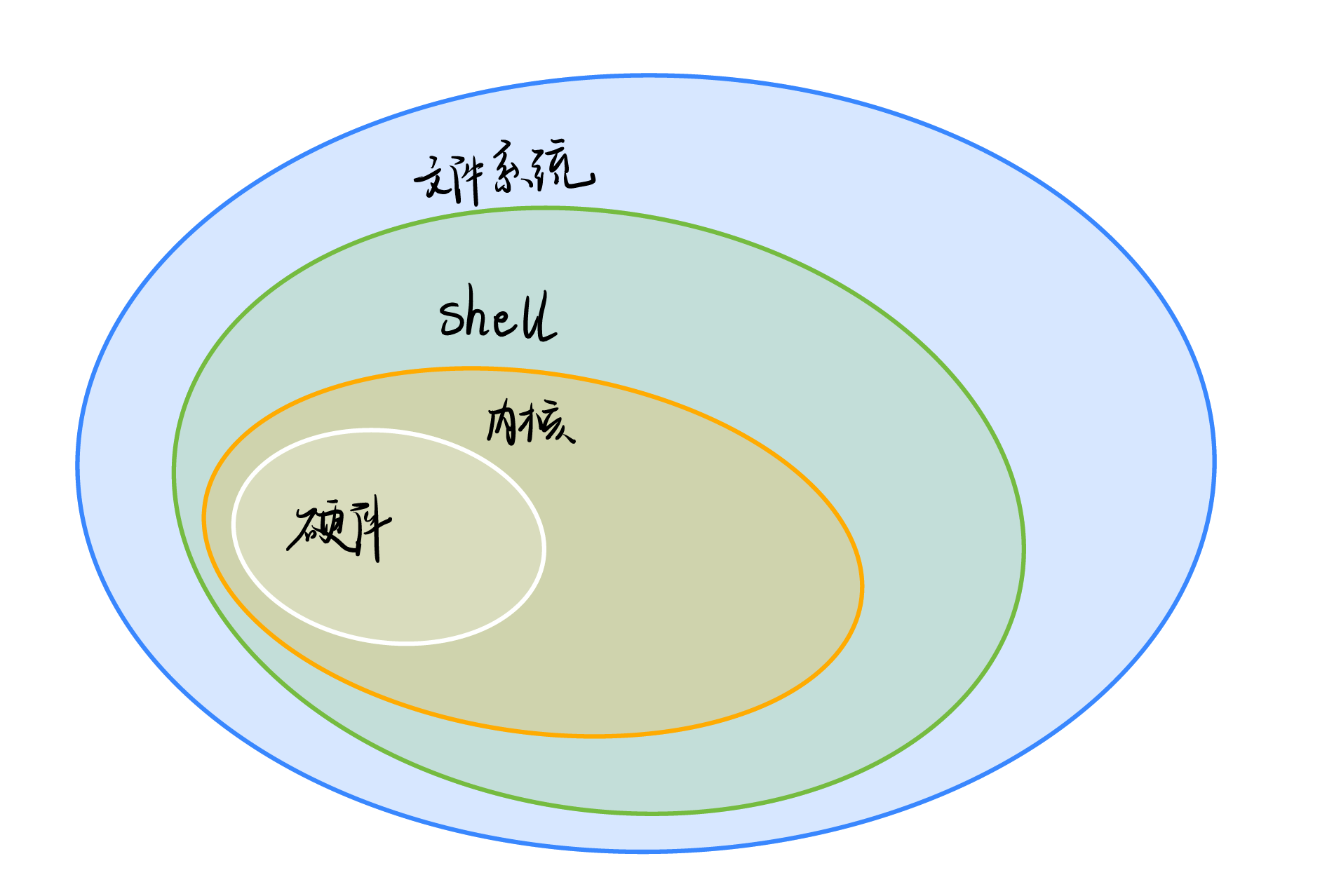
7、备注:对用户的描述,这个可以省略
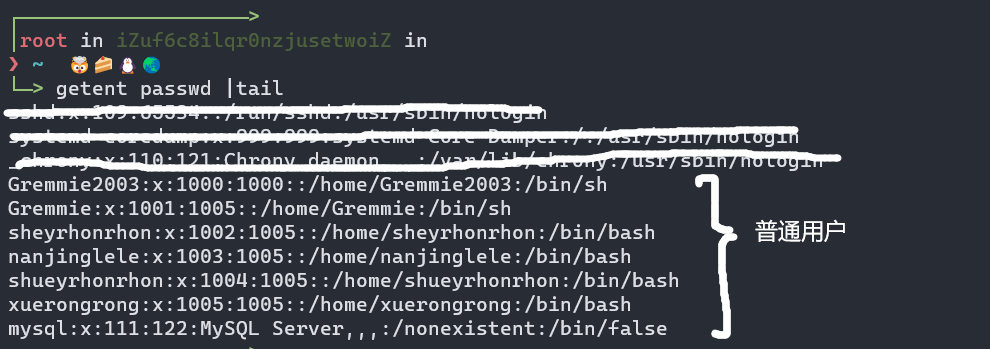
这些用户信息主要保存在文件/etc/passwd中,加密过后的密码保存在文件/etc/shadow中。/etc/passwd每一行对应一个用户,格式如下。
用户名:密码:UID:GID:备注:家目录:登录shell
每个参数之间用“:”分开,其中的“密码”都用x来表示,GID是该用户的主要组群的组号。
例如/etc/passwd文件中由如下一行:
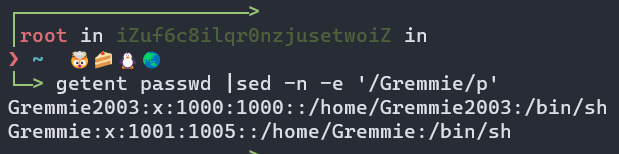
从上面这一行可以获得这些信息:用户名是Gremmie3,密码的位置出现x是表示加密后的密码串错放在/etc/shadow中,用户ID号是1000,隶属主要族群1000号,用户的家目录是/home/Gremmie2003,登录Shell是bin/bash,没有备注信息。
同样/etc/shadow也是一行对应一个用户,格式如下:
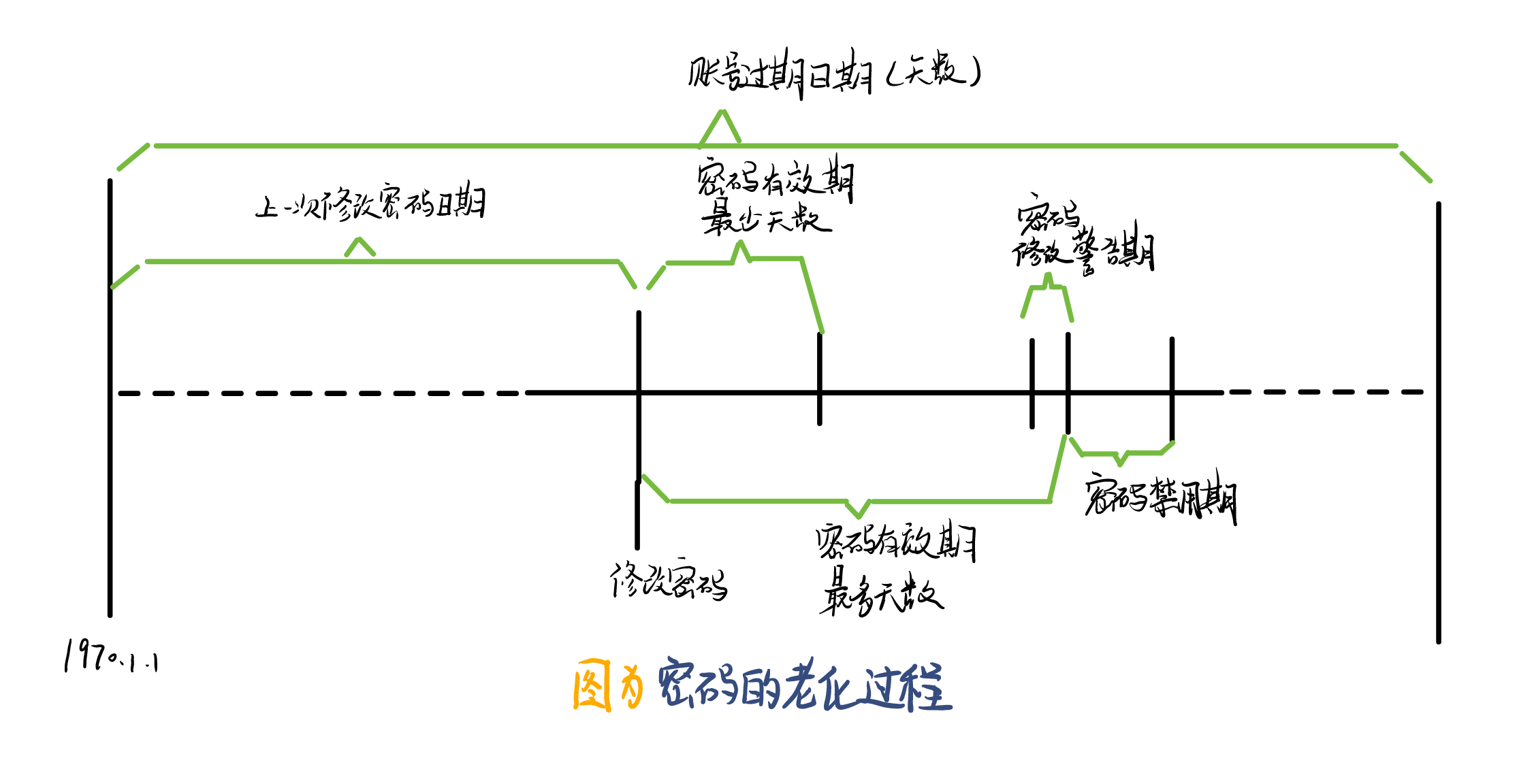
账号:密码:最后一次更改密码的日期:密码有效期最少天数:密码有效期最多的天数:密码修改警告期:密码禁用期:账号过期日期:保留字段
1、密码:经过加密之后的密文。这种加密算法是不可逆的,也就是说不能从密文反推出原始密码。在用户登录校验密码时,Linux系统采用相同的加密方法对用户登录时输入的密码进行加密得到密文,然后通过比较两份密文是否相同来判断密码输入是否正确,这里图中的感叹号则表示还未设置密码
2、上一次更改密码的日期:具体表现为从1970年1月1日以来的天数。例如在2022年3月26日修改过密码,那么这里就是19077.

3、密码有效期最少天数:即上次修改密码之后要过多少天之后才允许再次修改密码。如果为0或者空表示没有显示,即可随时修改密码。
4、密码有效期最多天数:即多少天前必须修改密码,如果过了有效期最多天数还没有修改密码,那么下一次用户登录时提示用户必须修改密码;为空则表示没有限制,同时也没有密码修改警告期;如果密码有效期最多天数小于密码有效期最少天数,那么用户不能修改密码。
5、密码修改警告期:即开始不断地通知用户要修改密码,如果为0或者空则不通知
6、密码警用期:过了密码有效期最多天数如果仍然没有修改密码,则进入密码禁用期,在禁用期内,用户登录时要求强行修改密码。过了禁用期,那么账号就完全冻结了,冻结的账号经过解冻之后就可以继续使用
7、账号过期日期:表示为从1970年1月1日以来的天数,为空则表示没有限制。账号过期之后不能再使用了。例如打算让账号在2022年3月26日失效,那么这里的值就是19077.
参数之间的关系表示为👇:
Linux系统的用户分为3类,分别是超级用户root、系统用户和普通用户。在安装系统时默认创建超级用户root,root的权力没有限制,它的UID和GID都是0.
超级用户的作用是管理系统,例如创建用户、给硬盘分区、配置网络等。系统用户主要用来启动服务或者用作一些特殊权限控制,系统用户的权限收到限制,系统用户也是在安装Linux或者应用软件时自动创建的,它们得到UID小于1000,系统用户不能登录。普通用户也是由超级用户root创建并分配给Linux系统的使用者,权限有限制,使用者用普通用户登录以完成他们的日常工作,普通用户的UID一般大于等于1000.
🍰组的概念
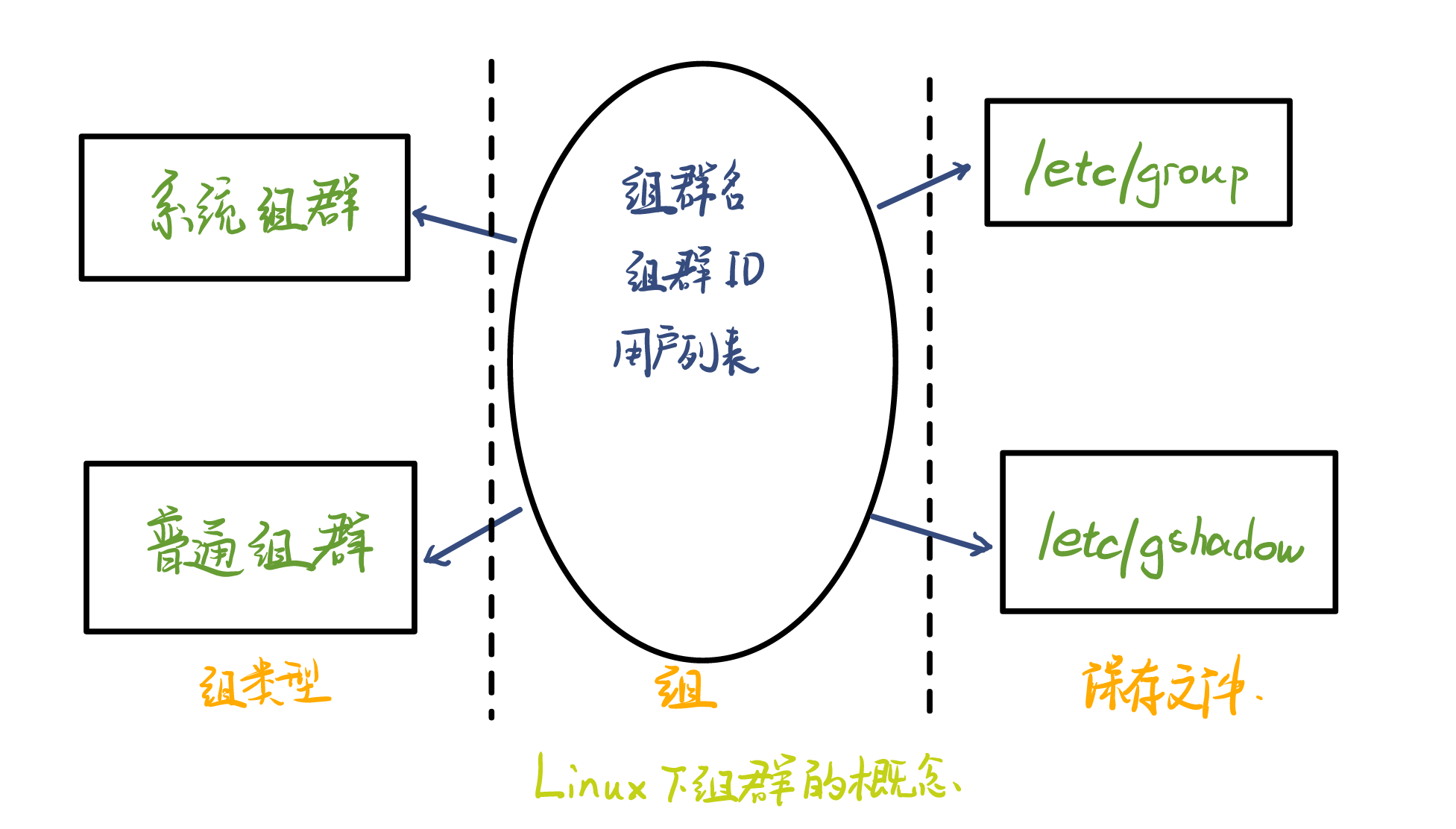
Linux下组群的概念如下👇:
一个用户必须且只能属于一个主要组群,但是可以属于0个或者多个附加组群,一个组群可以包含0个或者多个用户。例如我是南京医科大学的一个学生,我只能属于21生物信息班(主要族群),但我可以同时加入计算机设和音乐社(附加组群)。
🤯用户和组的管理
用户和组的管理包括创建、删除、修改属性、修改密码等。具体操作可以采用可视化的图形界面方式,也可以采用命令方式,这里重点介绍后者。Linux下的命令语法为:*<命令> <选项> <目标>*
“命令”是用来操纵“目标”的,那么怎么操纵呢?这是由“选项”规定的。由于可能存在多个选项,所以选项采用 “-<一个数字或字母>[参数]”或者“-<多个数字或字母>[参数]”的形式,例如创建用户Gremmie102的命令为:useradd -u 1007 -d /home/zbc–shell/bin/bash Gremmie102

命令是useradd,目标是Gremmie102,选项是-u 1007 -d /home/zbc–shell/bin/bash
文件/etc/login.defs定义了组群和用户的默认属性,在创建用户和组的时候,如果没有给出相对应的参数,那么就去默认值。主要参数如下👇:
| 序号 | 参数 | 默认值 | 说明 |
|---|---|---|---|
| 1 | PASS_MAX_DAYS | 99999 | 密码有效期最多多少天 |
| 2 | PASS_MIN_DAYS | 0 | 密码有效期最少多少天 |
| 3 | PASS_WARN_AGE | 7 | 密码警告十七,密码到期前7天发出警告 |
| 4 | PASS_MIN_LEN | 5 | 密码最小长度,即密码必须多于5个字符 |
| 5 | UID_MIN | 1000 | 创建用户时默认选择的UID最小值 |
| 6 | UID_MAX | 60000 | 创建用户时默认选择的UID最大值 |
| 7 | GID_MAX | 1000 | 创建组群时默认选择的GID最小值 |
| 8 | GID_MIN | 60000 | 创建组群时默认选择的GID最大值 |
🦖组的管理
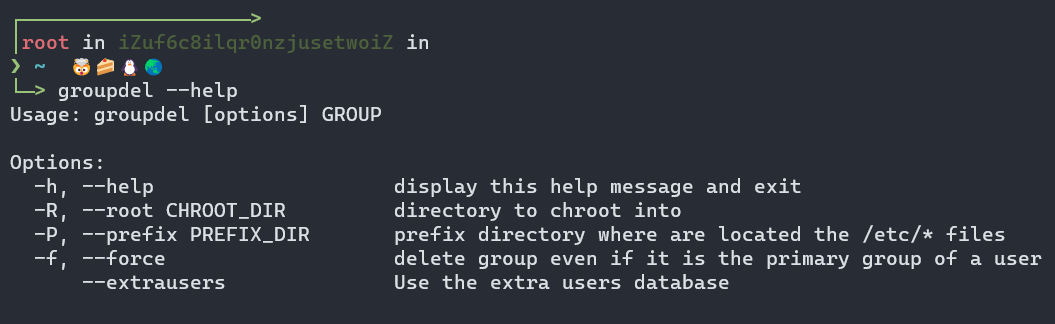
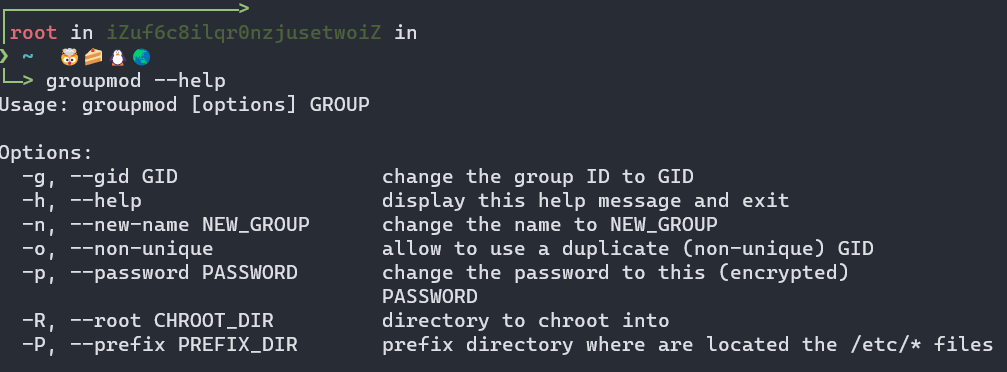
我们可以利用groupadd --help、groupdel --help、groupmod --help来查询相关的命令说明
🦉创建组
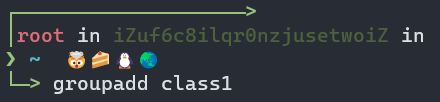
(1)创建组群class1:groupadd class1
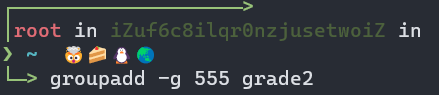
(2)创建组群grade2且指定GID为555:groupadd -g 555 grade2
(3)创建已经存在的组群root的别名组群administrators:groupadd -g 0 -o administrators
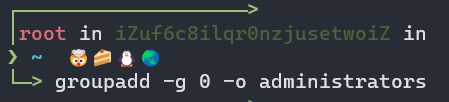
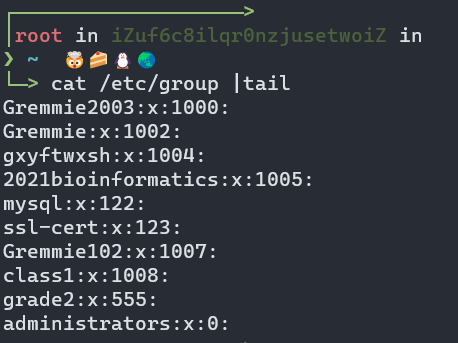
注意:只能创建不存在的组群。新建的组信息保存在/etc/group中,可以采用more或cat命令查看,例如
cat /etc/group
🦝删除组群
删除组群class1:groupdel class1
注意:只能删除已经存在的空组群,也就是组里没有用户成员
🦌修改组群的属性
- 修改组群sales的组号(GID)为1650:groupmod -g 1650 sales
- 修改组群sales的组群名为sales1:groupmod -n sales1 sales
- 用一条命令完成上述两个任务:groupmod -g 1650 -n sales1 sales
注意:只能修改已经存在的组群属性。
🛹查看组群的信息
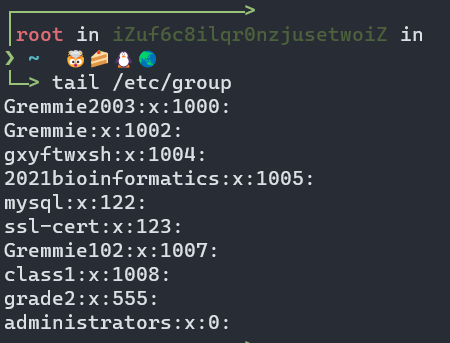
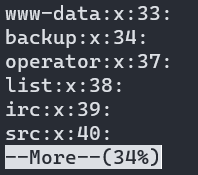
查看文件/etc/group 的内容即可,可以采用cat、more、tail等命令进行查看
(1)查看文件/etc/group的末尾10行:tail /etc/group
(2)翻页显示/etc/group的信息:more /etc/group
🚃用户管理
同样,我们可以用useradd --help、userdel --help、usermod --help来查询命令信息
在添加用户时,可以指定将该用户添加到哪个组中,同样的用 root 的管理权限可以改变某个用户所在的组。
1 | 改变用户所有组 |
1、所有者
一般为文件的创建者,谁创建了该文件,就自然成为了该文件的所有者。
1.1、查看文件的所有者
指令:ls -ahl
1.2、修改文件/目录的所有者-chown
1 | 基本介绍 |
2、所在组
2.1、组的创建
基本指令:groupadd 组名
创建monster组:groupadd monster
创建fox用户并放入monster组:useradd -g monster fox
2.2、所在组
当某个用户创建一个文件后,该用户的所在组就是该文件的所在组
查看文件/目录所在组
基本指令:ls -ahl
2.3 修改文件/目录的所在组-chgrp
1 | chgrp newgroup 文件/目录 (改变所在组) |
3、其他组
处文件的所有者和所在组的用户外,系统的其他用户都是文件的其他组
4、改变用户所在组
在添加用户时,可以指定将该用户添加到哪个组中,也可以使用root用户改变某个用户的所在组。
改变用户所在组:
1、usermod -g 组名 用户名
2、usermod -d 目录名 用户名 (改变该用户登录的初始目录)
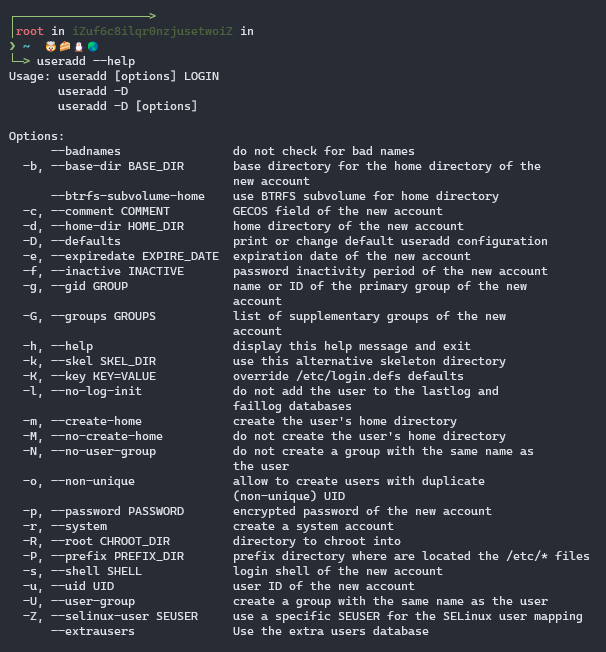
🎥创建用户
我们常常用到这几个选项
-d, --home-dir HOME_DIR home directory of the new account
-m, --create-home create the user’s home directory
-g, --gid GROUP name or ID of the primary group of the new account
-s, --shell SHELL login shell of the new account
*在你的创建的classmates中加入一个叫做bingdundun的用户*
useradd -m -g classmates bingdwendwen
useradd -m -g classmates -s /bin/bash bingdwendwen
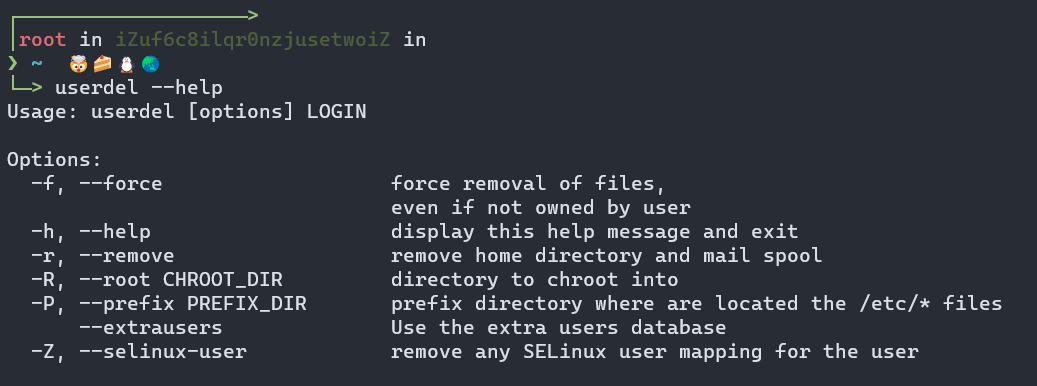
📸删除用户
userdel -r bingdundun 删除用户bingdundun
userdel -r bingdundun 删除用户bingdundun,连同家目录一起删除
userdel -f -r bingdundun 强行删除用户bingdundun ,即便此用户已经登录
注意,只能删除已经存在的用户
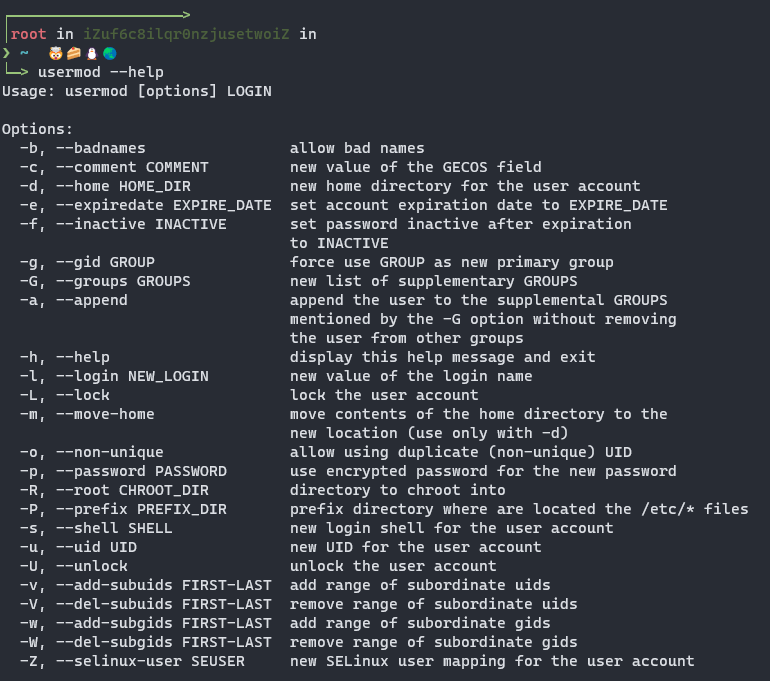
修改用户属性
uesermod -d /opt/bingdundun -s /bin/tcsh
👆修改用户的家目录和登录的shell
usermod -g grade1 -G class2 -a bingdundun
👆修改用户的主要族群为grade1,同时再加入附加组群class2
usermod -l bingdundun Gremmie
👆修改bingdundun的用户名为Gremmie
usermod -u 1020 bingdundun
修改用户bingdundun的UID为1020
usermod -d /opt/bingdundun -s /bin/tcsh -g grade1 -G class2 -a -l Gremmie -u 1020 -m bingdundun
合并上述操作
🐱用户密码管理
passwd -l bingdundun
锁住bingdundun,被锁的用户不能登录
passwd -u bingdundun
解锁后的用户可以继续登录
passwd bingdundun
修改bingdundun的密码
注意:用户的密码只有root和用户本人可以修改
passwd -d nanjinglele
删除用户nanjinglele的密码,这样nanjinglele就可以不用密码直接登录了
passwd -n 10 -x 20 -w 3 -i 5 bingdundun
修改用户bingdundun的密码老化时间,密码有效期最少天数10,最大天数20,过期前3天会发出警告,密码禁用期5天。
🥽查看用户信息
id Gremmie
查看Gremmie的UID、主要组群和附加组群的GID

more /etc/passwd
这里有个小细节,我将Gremmie放入了sudo系统组群中,这样Gremmie就可以使用sudo的权限
rwx权限
-rw-------. 1 root root 1696 Jul 16 09:27 anaconda-ks.cfg
-rw-r–r–. 1 root root 0 Aug 16 12:14 at
-rw-r–r–. 1 root root 12 Aug 1 10:48 at_alram
-rw-r–r–. 1 root root 4 Jul 30 16:11 at_task2
-rw-r–r–. 1 root root 0 Jul 20 09:28 cd
-rw-r–r–. 1 root root 0 Oct 8 15:00 cro_test
drwxr-xr-x. 2 root root 6 Jul 16 09:28 Desktop
drwxr-xr-x. 2 root root 6 Jul 16 09:28 Documents
drwxr-xr-x. 2 root root 6 Jul 16 09:28 Downloads
# 请大家思考下 上示 内容是通过那个命令显示出来的? 代表的意义又是什么?
====>>> *ls -l* 命令
# 我们带着 上述问题 开启 对 Linux 文件权限 知识的带入 :
之前的文章我们简单的 介绍过 文件权限的部分内容,现在我们开始整块儿知识地学习!
# 之前在学习 文件权限的时候 也对 ls -l 展示的内容做过解释,现在再复盘下 :

第一列 : 文件类型
第二列 : 访问权限 ( 实际上一共有 10 位)
第三列 :
***** 如果是文件的话就是 1
***** 如果是目录的话 : 数字就代表目录里的文件个数 !
第四列 : 所属用户
第五列 : 所属用户组
注 : 所属用户及所属用户组 都不完全代表 该文件就是所属用户或用户组创建
的( 因为 所属用户即用户组 是可以后期改变的!)
第六列 : 文件大小
第七列 : 时间日期
第八列 : 文件名 ( 如果是链接文件的话则会 显示 指向 )
# 关于文件类型在此再做以下解释 : 
这九位分为 三组 :
===>>>>
第一部分(2-4位) : 代表用户的权限
第二部分(5-7位) : 代表用户组的权限
第三部分(8-10位) : 代表其他人的权限
对于文件权限主要是由 以下 四个字符表示 :
r : 代表 读的权限
w : 代表 写的权限
x : 代表 执行的权限
- : 代表 没有赋予任何权限
# r w x 权限的数字表示方法

其实上图就直接完全总结了!!
会发现 r w x 三种权限 可以用 两种数字进制去表示
我们直接举例( 直接看例子最好理解 )
二进制表示 :
1 | rwxrwxrwx : 111111111 |
注 : 二进制其实就是说白了, r w x 那个有权限那个就是 1 没有权限就是 0
十进制(八进制)表示 : 我们仍以上示例子举例
1 | rwxrwxrwx : 111 111 111 |
注 : 你会很显然的发现 其实 所谓 十进制 就是把二进制转成了 十进制
( 没有什么神奇的!! )
但需要注意的是 我们仍是 以 三位三位一组!!!
# 九位权限的简写表示 :
1 | rwx rwx rwx |
***** 还有一个 a ( all ) : 代表所有即 user group other
u 、g、 o、 就是缩写表示 !!!
# 针对于 文件的 rwx 和 目录 的 rwx 是有区别的( 意义不一样 ~ )!!

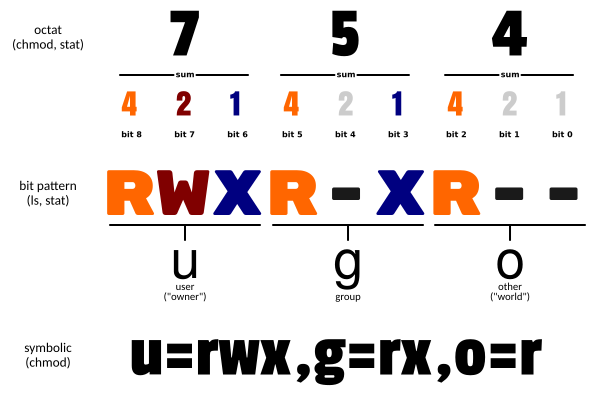
Linux chmod(英文全拼:change mode)命令是控制用户对文件的权限的命令
Linux/Unix 的文件调用权限分为三级 : 文件所有者(Owner)、用户组(Group)、其它用户(Other Users)。
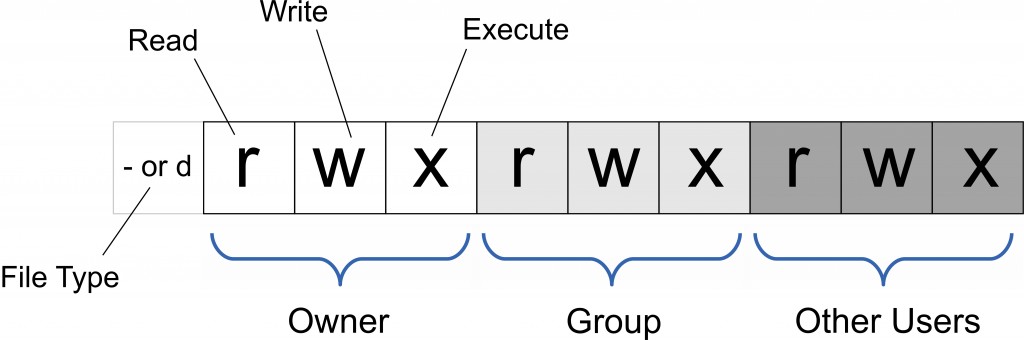
只有文件所有者和超级用户可以修改文件或目录的权限。可以使用绝对模式(八进制数字模式),符号模式指定文件的权限。
使用权限 : 所有使用者
语法
1 | chmod [-cfvR] [--help] [--version] mode file... |
参数说明
mode : 权限设定字串,格式如下 :
1 | [ugoa...][[+-=][rwxX]...][,...] |
其中:
- u 表示该文件的拥有者,g 表示与该文件的拥有者属于同一个群体(group)者,o 表示其他以外的人,a 表示这三者皆是。
- + 表示增加权限、- 表示取消权限、= 表示唯一设定权限。
- r 表示可读取,w 表示可写入,x 表示可执行,X 表示只有当该文件是个子目录或者该文件已经被设定过为可执行。
其他参数说明:
- -c : 若该文件权限确实已经更改,才显示其更改动作
- -f : 若该文件权限无法被更改也不要显示错误讯息
- -v : 显示权限变更的详细资料
- -R : 对目前目录下的所有文件与子目录进行相同的权限变更(即以递归的方式逐个变更)
- –help : 显示辅助说明
- –version : 显示版本
使用符号模式可以设置多个项目:who(用户类型),operator(操作符)和 permission(权限),每个项目的设置可以用逗号隔开。 命令 chmod 将修改 who 指定的用户类型对文件的访问权限,用户类型由一个或者多个字母在 who 的位置来说明,如 who 的符号模式表所示:
| who | 用户类型 | 说明 |
|---|---|---|
u |
user | 文件所有者 |
g |
group | 文件所有者所在组 |
o |
others | 所有其他用户 |
a |
all | 所有用户, 相当于 ugo |
operator 的符号模式表:
| Operator | 说明 |
|---|---|
+ |
为指定的用户类型增加权限 |
- |
去除指定用户类型的权限 |
= |
设置指定用户权限的设置,即将用户类型的所有权限重新设置 |
permission 的符号模式表:
| 模式 | 名字 | 说明 |
|---|---|---|
r |
读 | 设置为可读权限 |
w |
写 | 设置为可写权限 |
x |
执行权限 | 设置为可执行权限 |
X |
特殊执行权限 | 只有当文件为目录文件,或者其他类型的用户有可执行权限时,才将文件权限设置可执行 |
s |
setuid/gid | 当文件被执行时,根据who参数指定的用户类型设置文件的setuid或者setgid权限 |
t |
粘贴位 | 设置粘贴位,只有超级用户可以设置该位,只有文件所有者u可以使用该位 |
chmod指令(增减权限)
八进制语法
chmod命令可以使用八进制数来指定权限。文件或目录的权限位是由9个权限位来控制,每三位为一组,它们分别是文件所有者(User)的读、写、执行,用户组(Group)的读、写、执行以及其它用户(Other)的读、写、执行。历史上,文件权限被放在一个比特掩码中,掩码中指定的比特位设为1,用来说明一个类具有相应的优先级。
| # | 权限 | rwx | 二进制 |
|---|---|---|---|
| 7 | 读 + 写 + 执行 | rwx | 111 |
| 6 | 读 + 写 | rw- | 110 |
| 5 | 读 + 执行 | r-x | 101 |
| 4 | 只读 | r– | 100 |
| 3 | 写 + 执行 | -wx | 011 |
| 2 | 只写 | -w- | 010 |
| 1 | 只执行 | –x | 001 |
| 0 | 无 | — | 000 |
例如, 765 将这样解释:
- 所有者的权限用数字表达:属主的那三个权限位的数字加起来的总和。如 rwx ,也就是 4+2+1 ,应该是 7。
- 用户组的权限用数字表达:属组的那个权限位数字的相加的总和。如 rw- ,也就是 4+2+0 ,应该是 6。
- 其它用户的权限数字表达:其它用户权限位的数字相加的总和。如 r-x ,也就是 4+0+1 ,应该是 5。
实例
将文件 file1.txt 设为所有人皆可读取 :
1 | chmod ugo+r file1.txt |
将文件 file1.txt 设为所有人皆可读取 :
1 | chmod a+r file1.txt |
将文件 file1.txt 与 file2.txt 设为该文件拥有者,与其所属同一个群体者可写入,但其他以外的人则不可写入 :
1 | chmod ug+w,o-w file1.txt file2.txt |
为 ex1.py 文件拥有者增加可执行权限:
1 | chmod u+x ex1.py |
将目前目录下的所有文件与子目录皆设为任何人可读取 :
1 | chmod -R a+r * |
此外chmod也可以用数字来表示权限如 :
1 | chmod 777 file |
语法为:
1 | chmod abc file |
其中a,b,c各为一个数字,分别表示User、Group、及Other的权限。
r=4,w=2,x=1
- 若要 rwx 属性则 4+2+1=7;
- 若要 rw- 属性则 4+2=6;
- 若要 r-x 属性则 4+1=5。
1 | chmod a=rwx file |
和
1 | chmod 777 file |
效果相同
1 | chmod ug=rwx,o=x file |
和
1 | chmod 771 file |
效果相同
若用 chmod 4755 filename 可使此程序具有 root 的权限。
更多说明
命令 |
说明 |
|---|---|
chmod a+r *file* |
给file的所有用户增加读权限 |
chmod a-x *file* |
删除file的所有用户的执行权限 |
chmod a+rw *file* |
给file的所有用户增加读写权限 |
chmod +rwx *file* |
给file的所有用户增加读写执行权限 |
chmod u=rw,go= *file* |
对file的所有者设置读写权限,清空该用户组和其他用户对file的所有权限(空格代表无权限) |
chmod -R u+r,go-r *docs* |
对目录docs和其子目录层次结构中的所有文件给用户增加读权限,而对用户组和其他用户删除读权限 |
chmod 664 *file* |
对file的所有者和用户组设置读写权限, 为其其他用户设置读权限 |
chmod 0755 *file* |
相当于u=rwx (4+2+1),go=rx (4+1 & 4+1)。0 没有特殊模式。 |
chmod 4755 *file* |
4设置了设置用户ID位,剩下的相当于 u=rwx (4+2+1),go=rx (4+1 & 4+1)。 |
find path/ -type d -exec chmod a-x {} \; |
删除可执行权限对path/以及其所有的目录(不包括文件)的所有用户,使用’-type f’匹配文件 |
find path/ -type d -exec chmod a+x {} \; |
允许所有用户浏览或通过目录path/ |
对于目录 :
X 权限 !

注 : 使用 ls -ld 查看 /home/natash 这个目录的权限

注 : 让 harry 用户 访问 /home/natash 发现 没有权限 ( 废话,你要是理解
/home/natash 的权限你就知道为什么了)

注 : 显然,我们是用 root 用户添加权限的!!( 你用普通用户添加权限试试??)
会发现我们权限添加是 o + *x*
( x 权限 针对目录 就不再是 执行的意思了,是 访问的意思! )

注 : 显然, harry 可以访问 /home/natash 了!!
r 权限

*注* : 当我们在 harry 用户下,在 访问 natash 的家目录成功后,想要查看 家目录下的内
容时,发现 没有权限!!
( 因为刚才只是添加了 o+x, 并没有 r 的权限!)
注 : 还是在 root 下( 当然了也只能在 root 下)
添加 o + r ( 加 r 权限 )

w 权限

注 : 发现无法在 natash 家目录下 创建文件 !!
( 都没有 w 权限当然不行了!!)
 root 用户下 添加 w 权限
root 用户下 添加 w 权限

创建成功,并展示出来!!
这就是 w 权限的作用!!
最佳实践-警察和土匪游戏
1 | 有两个组:police组,bandit组 |
1 | groupadd sx |
1 | monkey.txt文件在wk目录下 |
1 | 唐僧和沙僧是其他组,进不去wk目录 |
1 | usermod -g yg ss |
1 | rwx权限对于 文件夹(目录) 的细节讨论和测试!!! |
1 | ``` |
init 3
1 |
|
我们在 /etc/inittab 目录下就可以查看


如何找回 root 密码
root 作为系统最高权限管理者,它的密码自然是至关重要的,那么 root 账户的密码应该怎么找回呢?步骤如下:
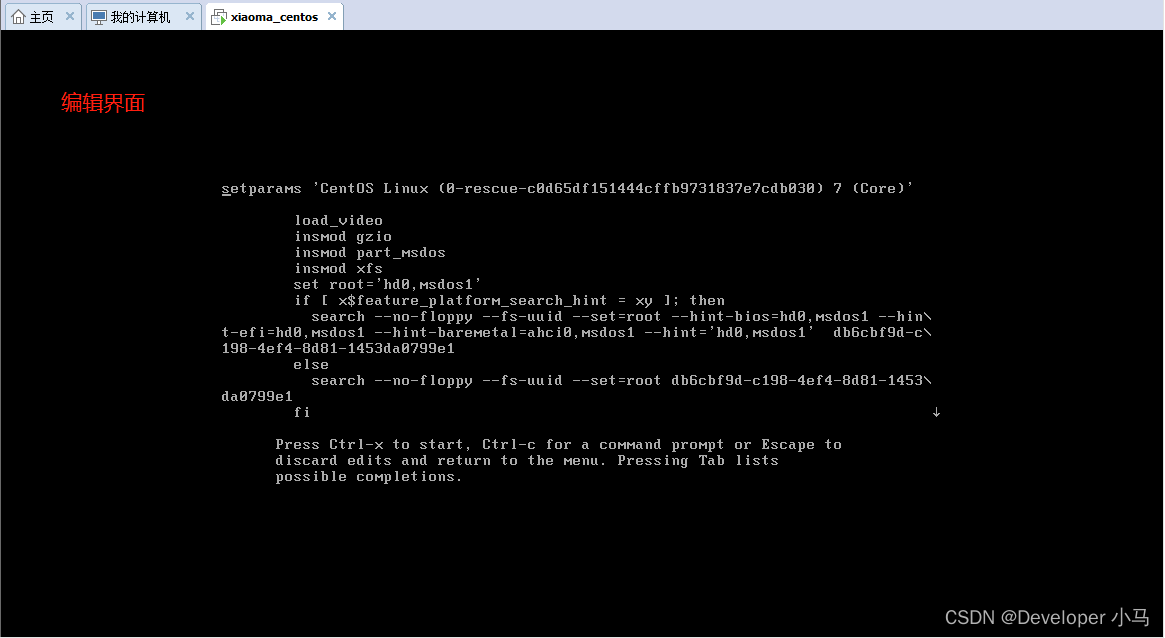
\1. 启动 Linux 系统,待进入开机界面后按 “e” 进入编辑界面,注意此处要快,在系统进入登录页面之前进行操作;
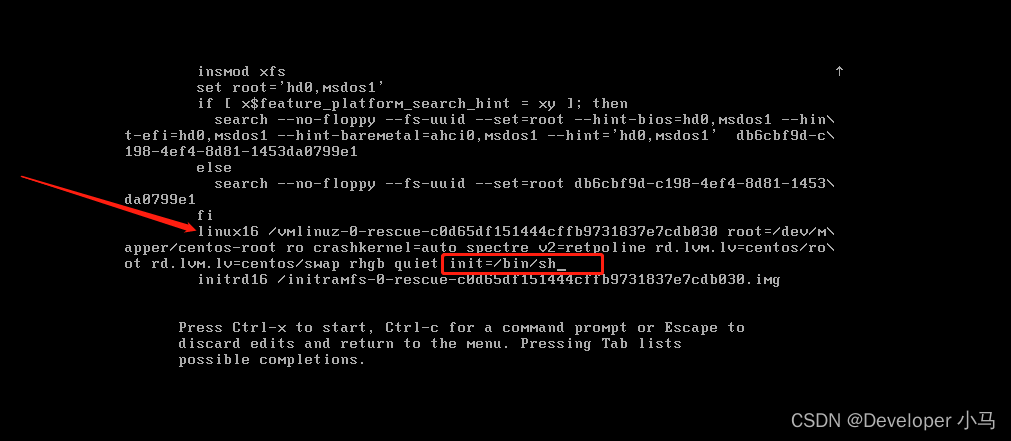
\2. 进入编辑界面后,找到以“Linux 16 ”开头的内容所在行,并在行最后输入 init=/bin/sh;
\3. 输入完成后,按下 Ctrl+X 进入单用户模式,如下界面即为单用户模式;
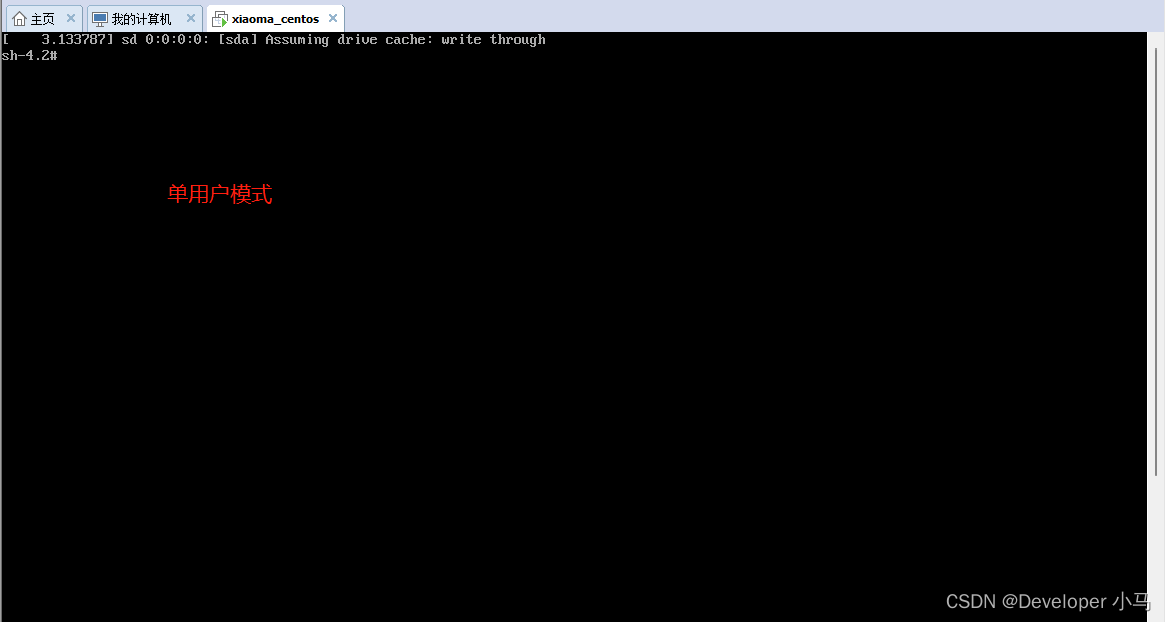
\4. 在光标闪烁的位置输入 mount -o remount,rw /,输入完成后回车;
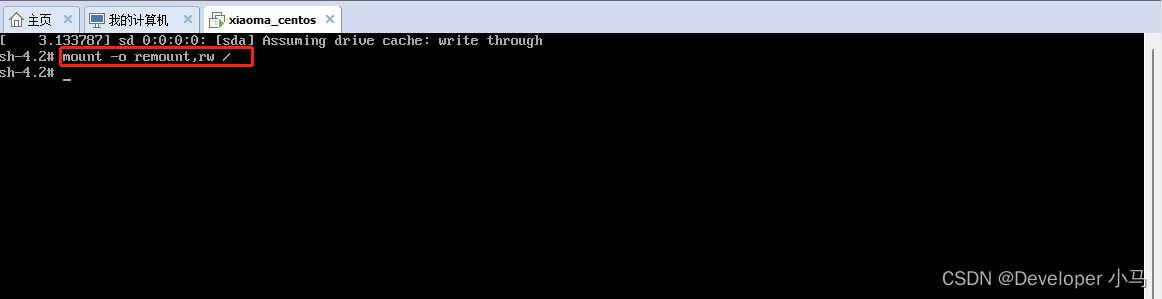
\5. 在新的行末输入 passwd 并回车,接下来输入密码、确认密码即可,修改密码成功后显示 passwd… 字样;

\6. 接下来在新的行末输入 touch /.autorelabel,输入完成回车;
\7. 新的行末继续输入 exec /sbin/init,完成后回车等待系统修改密码;
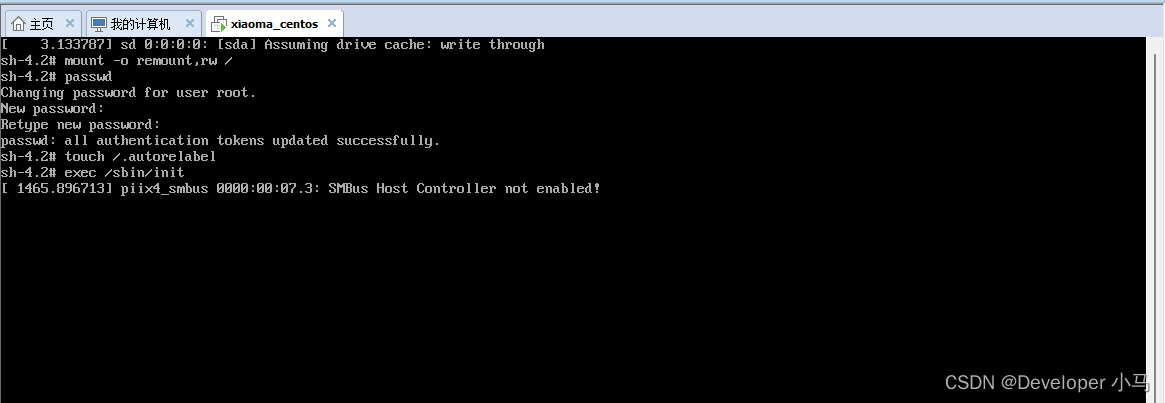
\8. 耐心等待,系统自动重启后新的 root 密码即可生效。
Linux中的帮助命令
一、Linux帮助命令简介
Linux 系统的命令数量有上千个,每个命令又有若干个甚至数十个参数指出不同情景下的使用。
有一些命令是我们日常工作需要经常使用的,即便不是特意背命令,也会因熟能生巧而印象深刻。但是对于那些不熟悉的命令,或者是熟悉命令的不熟悉的参数呢?
当然,我们不需要耗费大量精力去记忆这些命令和参数,只需要正确使用Linux 的帮助命令,就能够快速地定位到自己想要的命令和参数。
Linux 的帮助命令主要包含三个:
- help 命令与 --help 参数
- man 命令
- info 命令
接下来,将介绍这三个命令的使用方法及区别。
二、help 命令与 --help 参数
2.1 help 命令
help 命令能够在控制台上打印出我们需要的命令的帮助信息,使用方式为:
1 | help <command> |
例如,我们要查看 cd 命令和 mv 命令的帮助命令,使用上述形式的 help 命令时能够得到如下输出:
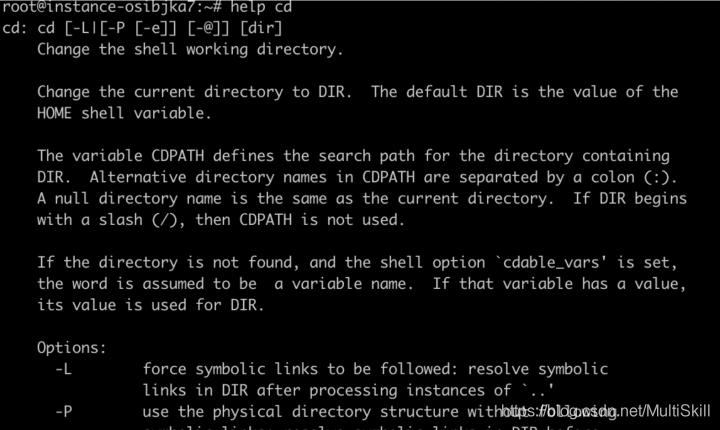

为什么会出现上述差异?为什么不能查看 mv 命令的帮助信息?这里需要引入一个“内建命令”和“外部命令”的概念
2.2 内建命令与外部命令
Linux 的内建命令是 shell 程序的一部分,Linux 系统加载运行时就被加载并驻留在系统内存里的,因此执行速度较快。
Linux 的外部命令是通过额外安装获得的命令,不随系统一起被加载到内容中,运行速度慢但功能强大。
使用 type 命令可以查看该命令是内建命令还是外部命令
1 | type <command> |
例如上文中,提及的 cd 命令和 mv 命令,我们看一下它们分别属于什么类型的命令


从上述信息中,我们发现 cd 命令是一个内建命令,mv 命令是一个外部命令。多次尝试后,可以发现,上述形式的 help 命令只能用于内建命令的帮助信息查询。
我们可以尝试查看 help 命令本身的帮助文档
1 | help help |
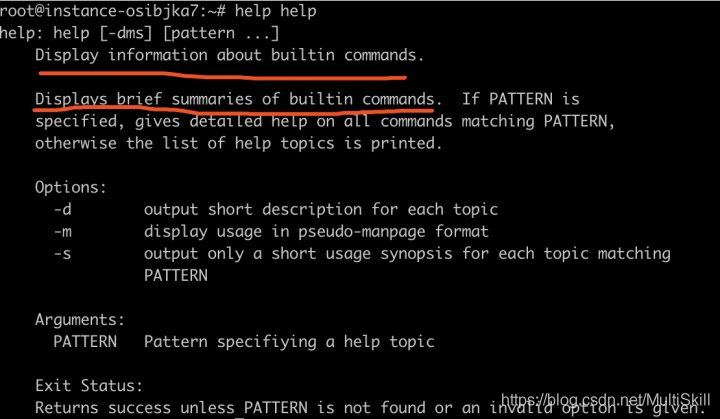
不难看出,只有内建命令能够使用下述形式的 help 命令查询帮助文档。
1 | help [option] <command> |
2.3 – help 参数
若是想用 help 来查询外部命令的帮助文档,上述形式是行不通的,但是可以用下述形式查询外部命令的帮助文档
1 | <command> --help |
**需要注意的是,这两个形式的 help 并不能完全等同。**前一种通过执行内建的 help 命令查看帮助文档,后一种是通过命令后携带参数 help 的方式来展示所查询命令的帮助文档。我们不妨尝试查询外部命令 mv 的帮助文档:
1 | mv --help |
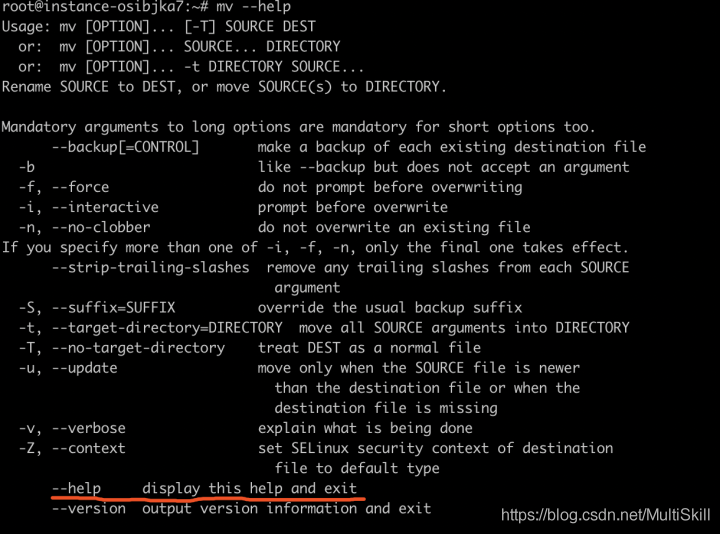
不难发现,mv 命令支持了 --help 的参数,才能展示这个命令的帮助信息并退出。
三、man 命令
3.1 man 提供的帮助信息
man 是 manual 的简写,与 help 命令和 --help 参数不同,使用 man 命令查询帮助手册时会进入 man page 界面,而非直接打印在控制台上。同时,相比与 help,man 命令的信息更全,help 则显示的信息简洁
1 | man [option] <command> |
例如,我们要查看 mv 命令的帮助信息
1 | man mv |
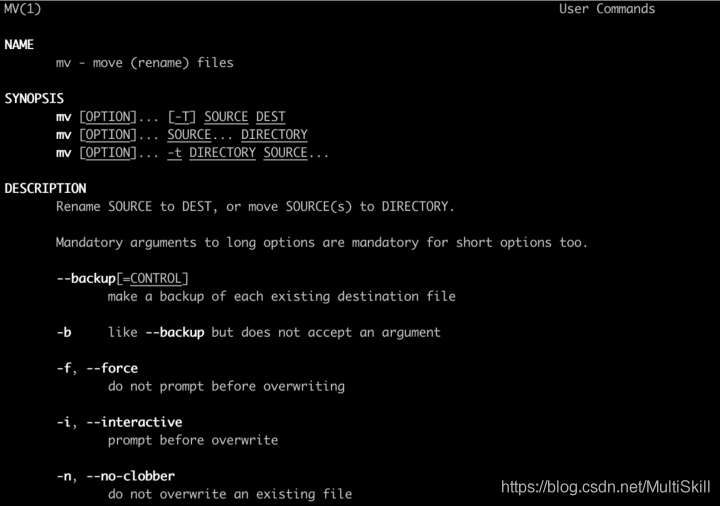
man page 中提供了关于 mv 命令的 “名字” 、 “概要” 、 “介绍” 等信息,还有诸如 “作者信息” 、 “更多” 等其他信息未在图中展示。具体包括:
| 名称 | 含义 |
|---|---|
| NAME | 命令名称及简要说明 |
| SYNOPSIS | 命令执行语法概要 |
| DESCRIPTION | 完整的命令说明 |
| OPTIONS | 列举所有可用的参数项 |
| COMMANDS | 当命令在执行的时候,可以在程序中执行的命令 |
| FILES | 这个命令所参考或链接的某些文件 |
| SEE ALSO | 有关这个命令的其他说明 |
| EXAMPLE | 一些可以参考的范例 |
| BUGS | 是否有相关的错误 |
我们注意到,在第一行有 “MV(1)” 的字样,括号内的数字代表什么含义呢?它其实是对所查询信息的一个分类。
| 数字 | 代表含义 |
|---|---|
| 1 | 用户在shell环境中可操作的标准命令或可执行文件 |
| 2 | 系统内核调用的函数及工具 |
| 3 | 常用的库函数 |
| 4 | 设备文件与设备说明等 |
| 5 | 配置文件或文件格式 |
| 6 | 游戏等娱乐 |
| 7 | 协议信息等 |
| 8 | 系统管理员可用的管理命令 |
| 9 | 与 Linux 内核相关的文件文档 |
3.2 man page 中的按键操作
man 命令相比于 help 命令最大的优势在于用户可以在 man page 中,通过按键交互进行翻页、查找等操作。常见的按键操作如下所示。
| 按键 | 功能 |
|---|---|
| 空格键 | 翻页 |
| /str | 向后查找str字符串 |
| ?str | 向前查找str字符串 |
| n, N | n 为搜索到的下一个字符串,N 为搜索到的上一个字符串 |
| q | 退出 man page |
四、 info 命令
4.1 info 提供的帮助信息
1 | info [option] <command> |
info 命令的功能基本与 man 命令相似,能够显示出命令的相关资料和信息。
而与 man 命令稍有区别的是,一方面,info 命令可以获取所查询命令相关的更丰富的帮助信息;另一方面,info page 将文件数据进行段落拆分,并以 “节点” 的形式支撑整个页面框架,并将拆分的段落与节点对应,使得用户可以在节点间跳转而方便阅读每一个段落的内容。
以 info info 为例,我们进入了关于命令 info 的 info page
第一层:顶层节点,展示了关于 info 命令的基本信息及目录信息
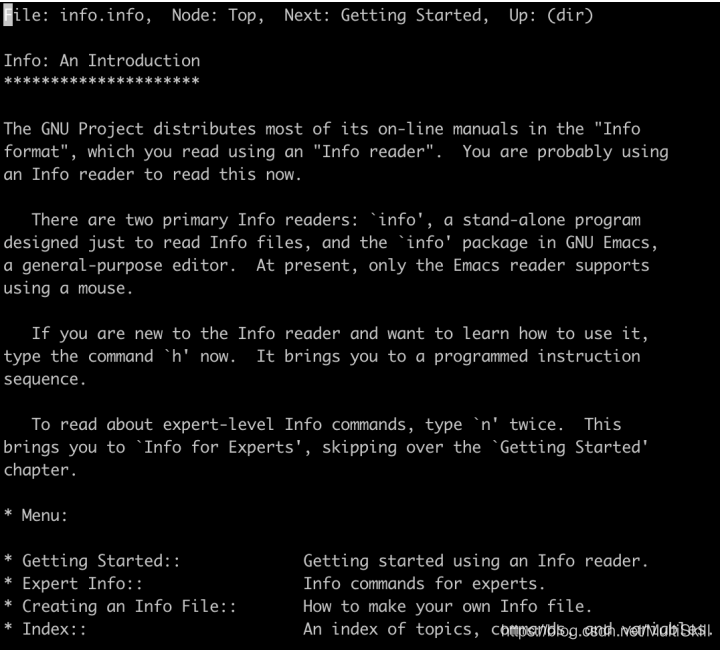
第二层:一级目录节点,展示了一级目录中的详细内容,其中可能包含了二级目录列表
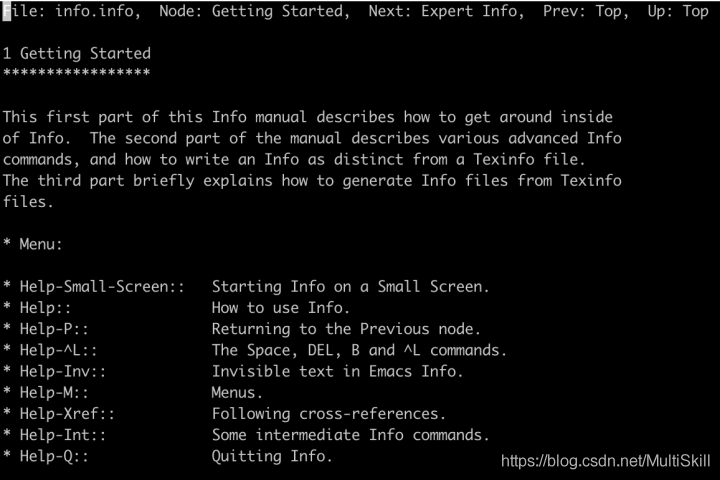
第三层:二级目录节点:展示了二级目录中的详细内容
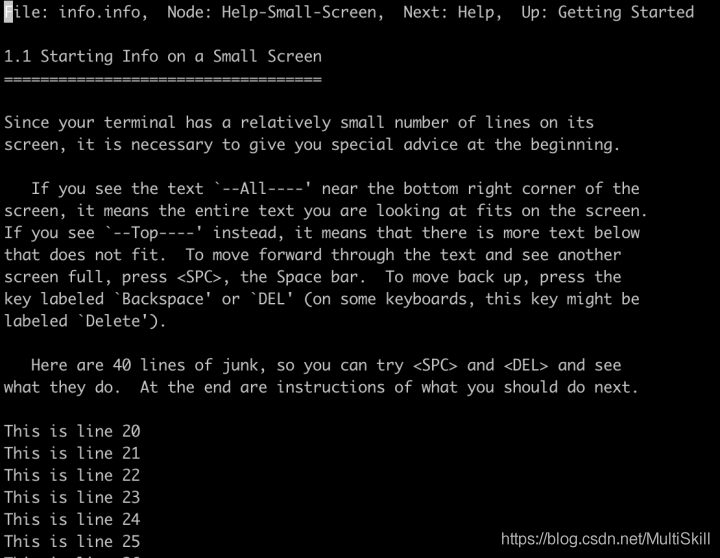
以此类推。
4.2 info page 中的按键操作
info page 提供了翻页、节点跳转、搜索等交互操作。
| 按键 | 功能 |
|---|---|
| 空格键 | 向下翻一页 |
| 回车键 | 跳到下一个节点 |
| P | 跳到上一个节点 |
| U | 回到上一层节点 |
| 回车键 | 光标移动到下一层节点处,以回车键进入 |
| B | 跳到当前 info page 的第一个节点处 |
| E | 跳到当前 info page 的最后一个节点处 |
| / | 在 info page 中进行搜索 |
| Q | 退出 info page |
Linux文件目录指定
一、新建操作
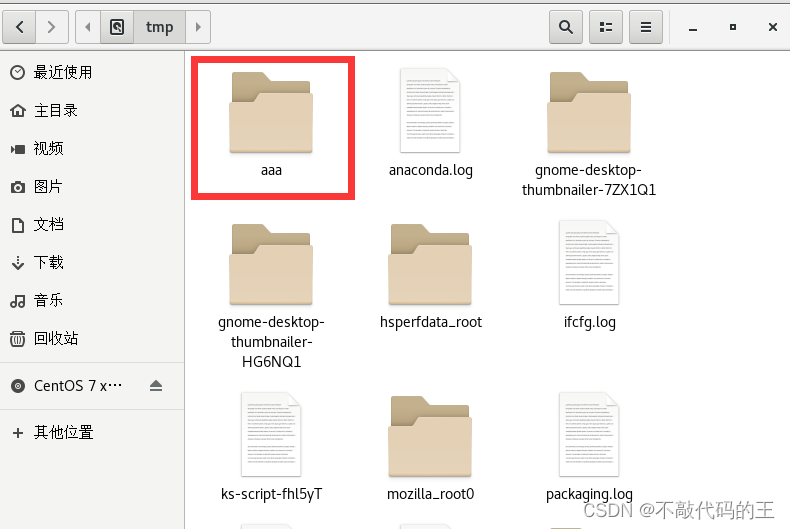
1、mkdir /路径/文件夹名字 :新建一个文件夹
2、mkdir -p /路径/文件夹名/文件夹名/文件夹名 :当创建没有上一级时将自动创建
1 | [root@localhost ~]# mkdir /tmp/aaa #在根目录下的tmp文件夹下面创建一个名为aaa的文件夹 |
3、touch /路径/文件名 :在指定路径下创建一个文件
1 | [] |

二、查看操作
1、查看目录(代码中的数字是我自己加的,为了方便对应阅读)
1、ls /路径 :显示指定路径下的文件。
2、ls -l /路径 :以列表的形式展示指定路径下的文件。
3、cd /路径 :切换路径。
4、pwd :显示路径。
1.路径、目录命令
(1)pwd:显示当前所在位置的绝对路径

(2)cd系列
cd 路径:切换当前工作位置
cd:切换目录:cd 要切换的位置(绝对路径/相对路径)
cd . :退回到当前位置
cd … :退回到上一层
cd ~:直接进入到当前用户的家目录
cd -:切换到上一次所在位置,在两个位置之间来回切换;
(3)ls:
默认显示当前位置当前目录下的内容

(4)清屏
clear:清屏(相当于翻页)
2、查看文件内容(代码中的数字是我自己加的,为了方便对应阅读)
1、cat /路径/文件名 :查看文件的内容。
2、head -5 /路径/文件名 :查看文件前五行内容。
3、tail -num 文件名 :从距文件尾num行开始显示。
more 文件名
less文件名(最常用)
1 | 1、[root@localhost tmp]# cat /wang #查看根目录下wang文件的内容 |
more命令
Linux中 more命令功能类似 cat ,cat命令是整个文件的内容从上到下显示在屏幕上。 more 是一个基于VI编辑器的文本过滤器,会以全屏幕的方式按页显示文本文件的内容,而最基本的指令就是按空白键(space)就往下一页显示,按 b 键就会往回(back)一页显示,而且还有搜寻字串的功能 。more命令从前向后读取文件,因此在启动时就加载整个文件。
1.语法:
1 | more [选项] 要查看的文件 |
2.功能:
more命令和cat的功能一样都是查看文件里的内容,但有所不同的是more可以按页来查看文件的内容,还支持直接跳转行等功能。
3.参数:
1 | +n 从笫n行开始显示。 |
4.常用操作命令:
| 操作 | 功能说明 |
|---|---|
| 空格键 (space) | 代表向下翻一页。 |
| Enter | 代表向下翻n行,需要定义,默认为1行。 |
| q | 代表立刻离开 more ,不再显示该文件内容。 |
| Ctrl+F | 向下滚动一屏。 |
| Ctrl+B | 返回上一屏。 |
| = | 输出当前行的行号。 |
| :f | 输出文件名和当前行的行号。 |
| !命令 | 调用Shell,并执行命令。 |
| V | 调用vi编辑器 |
less命令也是对文件或其它输出进行分页显示的工具,功能极其强大。less 的用法比起 more 更加有弹性。前面more介绍中,按b可以向前翻页, 按空格向后翻页, less 可以使用 [pageup] [pagedown] 等按键的功能来往前往后翻看文件,更容易用来查看一个文件的内容!除此之外,在 less 里头可以拥有更多的搜索功能,不止可以向下搜,也可以向上搜。最主要的区别:less 在查看之前不会加载整个文件。
less
1 | less [参数] 文件 |
1.命令功能
less 与 more 类似,但使用 less 可以随意浏览文件,而且 less 在查看之前不会加载整个文件。显示方面,显示内容方式不是输出到窗口,而是类似vi打开的文件一样,退出按q。
2.命令参数
- -b <缓冲区大小> 设置缓冲区的大小
- -e 当文件显示结束后,自动离开
- -f 强迫打开特殊文件,例如外围设备代号、目录和二进制文件
- -g 只标志最后搜索的关键词
- -i 忽略搜索时的大小写
- -m 显示类似more命令的百分比
- -N 显示每行的行号
- -o <文件名> 将less 输出的内容在指定文件中保存起来
- -Q 不使用警告音
- -s 显示连续空行为一行
- -S 行过长时间将超出部分舍弃
- -x <数字> 将“tab”键显示为规定的数字空格
3.按键操作
- /字符串:向下搜索“字符串”的功能
- ?字符串:向上搜索“字符串”的功能
- n:重复前一个搜索(与 / 或 ? 有关)
- N:反向重复前一个搜索(与 / 或 ? 有关)
- b 向后翻一页
- d 向后翻半页
- h 显示帮助界面
- Q 退出less 命令
- u 向前滚动半页
- y 向前滚动一行
- 空格键 滚动一行
- 回车键 滚动一页
- [pagedown]: 向下翻动一页
- [pageup]: 向上翻动一页
4.实例
命令:
1 | less test1.txt |
输出:
1 | ubuntu@VM-4-14-ubuntu:~/less$ less test1.txt |
如果显示END了 按 q退出,没有的情况下可以按page up page down 上下翻页,也可用上下键一行行上下翻动。less命令也是对文件或其它输出进行分页显示的工具,功能极其强大。less 的用法比起 more 更加有弹性。前面more介绍中,按b可以向前翻页, 按空格向后翻页, less 可以使用 [pageup] [pagedown] 等按键的功能来往前往后翻看文件,更容易用来查看一个文件的内容!除此之外,在 less 里头可以拥有更多的搜索功能,不止可以向下搜,也可以向上搜。最主要的区别:less 在查看之前不会加载整个文件。
tail命令(可用于追踪抓包)
ail命令,主要是查看文件内容。结合一些参数,更方便于查看动态的文件内容,比如日志信息等。
【tail -f filename】显示文件的尾部最后10行的信息,并且循环刷新,只要文件有更新,就会将更新信息显示到屏幕上,CTRL+C进行停止。
【tail -n num】显示文件尾部的n行内容。如【tail -n +10】显示第十行及之后一直到文件尾部的内容。【tail -n 10】则显示文件最后十行的内容。
【tail -c num】显示文件尾部的字节数。如【tail -c 100】显示文件的最后100个字节。【tail -c +1000】从第1000个字节开始展示,到文件的末尾。
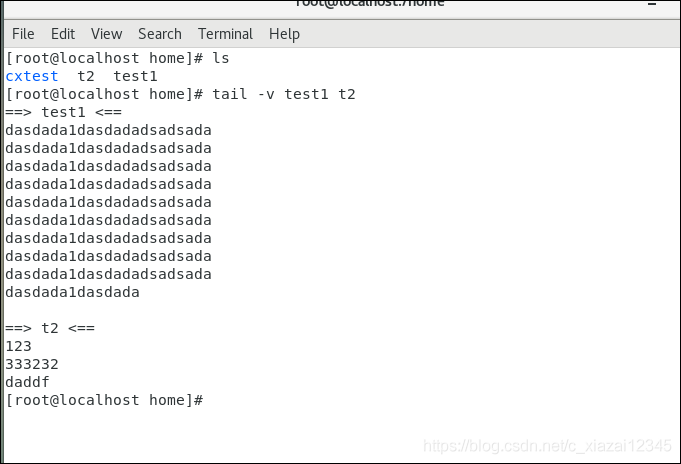
【tail -v filename】显示文件名及文件详细处理信息。还可以同时指定多个文件输出【tail -v filename1 filename2】
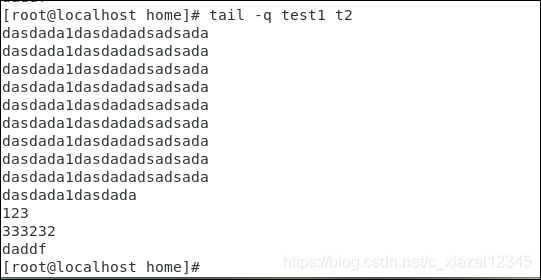
【tail -q filename】不显示详细的处理信息。【tail -q filename1 filename2】指定多个文件,但不展示文件名称:
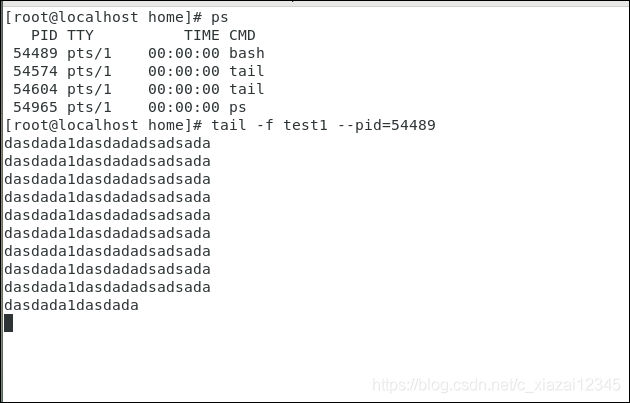
【tail -f filename --pid=PID】当进程号对应的进程停止时,则自动退出tail命令。
3、查看状态或者文件类型
1、stat /路径/文件名 :查看文件的详细信息。
2、file /路径/文件名 :查看文件的类型。
3、du -h /路径/文件名 :以合适的单位显示文件的大小(会根据文件的大小自动选择单位)。
1 | 1、[root@localhost /]# stat /wang #查看根目录下wang文件详细信息 |
三、删除操作
1、rm -rf /路径/文件夹名 :强制删除文件夹和文件夹内的多有内容,注意请不要输入“rm -rf / ” 因为这个命令是前置删除根目录如果这样操作计算机将无法打开了
2、rm -f /路径/文件名 :强制删除文件,无法删除文件夹
1 | 1、[root@localhost /]# rm -rf /aaa #强制删除根目录下aaa文件夹和文件夹下的所有内容 |
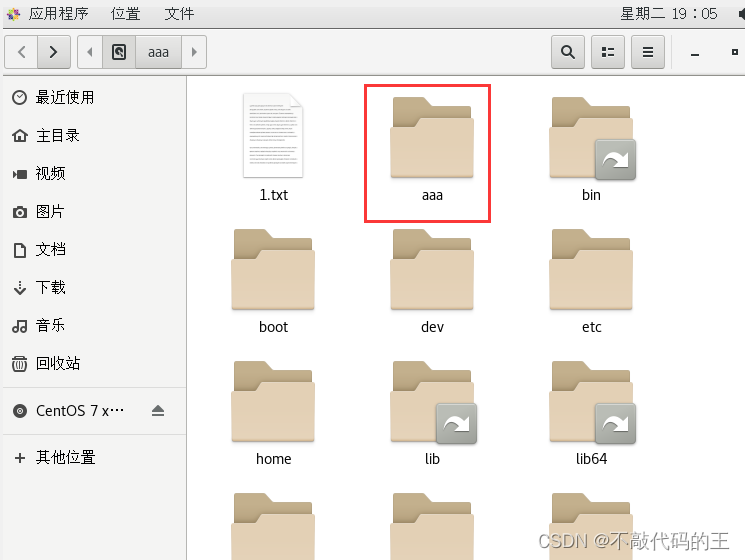
四、移动操作
1、 mv 原文件路径 目标文件路径 :将源文件移动到目标文件
2、mv 原文件路径 目标路径/名字 :将源文件移动到目标文件并且将原文件的名字进行重命名
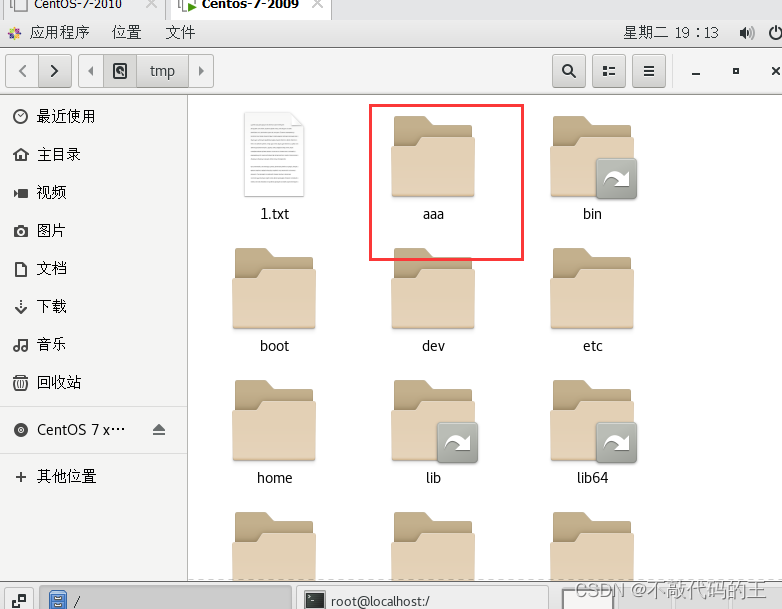
1 | 1、[root@localhost /]# mv /tmp/aaa /aaa #将/tmp的aaa文件夹移动到根目录下结果如图一 |
图一:
图二

五、复制操作
1、cp 源文件 目标文件 :将源文件复制到目标目录下 不可以复制文件夹
2、cp -r 源文件 目标文件:若给出的源文件是一个目录文件,此时将复制该目录下所有的子目录和文件。
2
3
4
5
6
7
8
9
[root@localhost /]# cp /bbb /tmp #因为bbb是一个文件夹所以系统直接略过不可以复制
cp: 略过目录"/bbb"
2、cp -r /bbb /tmp #(bbb是一个文件夹)将根目录下的bbb文件夹复制到/tmp路径下
echo指令
Shell中的echo命令类似于php中的echo命令,都是用于输出。Shell中另有一个输出命令为printf命令,我没有另写文章介绍该命令,大家可以在Shell printf 命令中查阅学习。
本文中的一系列实例用到的命令我都是在终端直接写的,输出也是输出在终端,这样方便学习和记录吧!其实也都可以放到脚本文件中执行。
一、语法
1 | echo [-neE] [arg ...] |
(1)含义
-n:表示输出字符串不换行
-e:表示对于转义字符按对应的方式进行处理(若不加-e ,那么在输出时转义字符会按照普通字符进行处理,并不会达到自己想要达到的目的。)
-E:禁用转义解释
| 转义字符 | 含义 |
|---|---|
| \b | 删除前一个字符 |
| \n | 换行 |
| \t | 水平制表符(tab) |
| \v | 垂直制表符(tab) |
| \c | \c后面的字符将不会输出,输出完毕后也不会换行 |
| \r | 光标移动到首行,不换行 |
| \f | 换行,光标停在原处 |
| \e | 删除后一个字符 |
| \ | 输出\ |
| \0nnn | 输出八进制nnn代表的ASCII字符 |
| \xHH | 输出十六进制数HH代表的ASCII字符 |
| \a | 输出一个警告的声音 |
(2)实例
1 | [root@localhost my_shell]# echo "hello " |
(3)具体用法
上面介绍的主要是一些输出字符串相关的具体用法,下面详细例举一些echo命令的其他用法。
1、显示普通字符串
1 | [root@localhost ~]# echo "hello world" |
2、显示变量
这里用到read命令(从标准输入中读取一行,并把输入行的每个字段的值指定给 shell 变量)。
1 | [root@localhost ~]# read name |
3、显示换行
1 | [root@localhost ~]# echo -e "hello \nworld" |
4、显示不换行
1 |
|
5、显示转义字符
1 | [root@localhost ~]# echo "\"hello world\"" |
6、重定向
结果输出到文件
1 | echo "hello world" > my_file |
7、原样输出
用单引号可原样输出。
1 | [root@localhost ~]# echo '$name\"' |
8、显示命令执行结果
1 | #显示当前日期 |
这里使用的是反引号`, 而不是单引号’。
实际上输出一些执行命令的结果就是这样用反引号。
二、echo的重定向(其它指令也可以像echo一样重定向)
重定向是Shell中的一个重要内容,可以查看我的文章Linux中的重定向。
echo命令的重定向功能经常被用于清空文件内容(删除文件)时使用,具体在我的另一篇文章中介绍:Linux中清空文件的方式
(1)echo "content" > filename
将content覆盖到filename文件当中去,filename文件当中之前的内容不复存在了,实际上是修改了原文件的内容。
(2)echo "content" >> filename
将content追加到filename文件后,对filename文件之前的内容不修改,只进行增添,也叫追加重定向。
(3)实例
1 | [root@localhost my_shell]# touch test |
ln指令
介绍
ln是linux的一个重要命令,它的功能是为某一个文件在另外一个位置建立一个同步的链接。当我们需要在不同的目录,用到相同的文件时,我们不需要在每一个需要的目录下都放一个必须相同的文件,我们只要在某个固定的目录,放上该文件,然后在其它的目录下用ln命令链接(link)它就可以,不必重复的占用磁盘空间。平时使用感觉就像桌面应用上的快捷图标一样,比如你安装的nginx文件在usr/local/nginx/sbin/nignx,可以在usr/local/bin中建立一个nginx的软连接,这样每次就可以全局访问了。
1 | // 给nginx建立一个可以全局访问的软连接 |
命令
命令格式
1 | ln [参数][源文件或目录][目标文件或目录] |
命令功能
Linux文件系统中,有所谓的链接(link),我们可以将其视为档案的别名,而链接又可分为两种 : 硬链接(hard link)与软链接(symbolic link),硬链接的意思是一个档案可以有多个名称,而软链接的方式则是产生一个特殊的档案,该档案的内容是指向另一个档案的位置。硬链接是存在同一个文件系统中,而软链接却可以跨越不同的文件系统。
软链接:
- 软链接,以路径的形式存在。类似于Windows操作系统中的快捷方式
- 软链接可以 跨文件系统 ,硬链接不可以
- 软链接可以对一个不存在的文件名进行链接
- 软链接可以对目录进行链接
硬链接:
- 硬链接,以文件副本的形式存在。但不占用实际空间。
- 不允许给目录创建硬链接
- 硬链接只有在同一个文件系统中才能创建
这里有两点要注意:
第一,ln命令会保持每一处链接文件的同步性,也就是说,不论你改动了哪一处,其它的文件都会发生相同的变化;
第二,ln的链接又分软链接和硬链接两种,软链接就是ln –s 源文件 目标文件,它只会在你选定的位置上生成一个文件的镜像,不会占用磁盘空间,硬链接 ln 源文件 目标文件,没有参数-s, 它会在你选定的位置上生成一个和源文件大小相同的文件,无论是软链接还是硬链接,文件都保持同步变化。
ln指令用在链接文件或目录,如同时指定两个以上的文件或目录,且最后的目的地是一个已经存在的目录,则会把前面指定的所有文件或目录复制到该目录中。若同时指定多个文件或目录,且最后的目的地并非是一个已存在的目录,则会出现错误信息。
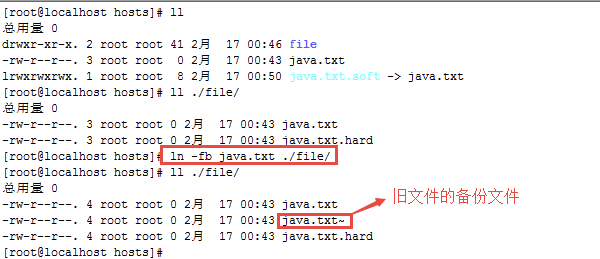
事例
创建一个硬链接文件
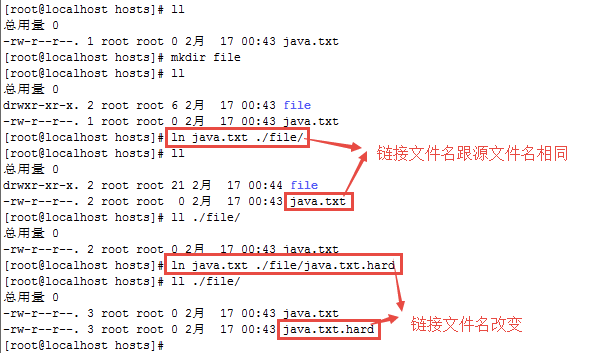
创建一个软链接文件
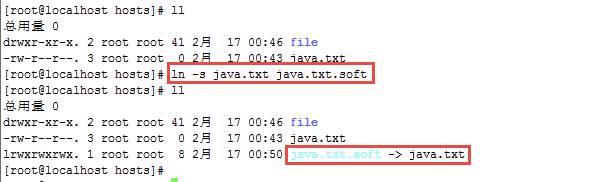
创建一个硬链接文件,如果目标目录中已经有同名文件,覆盖前先进行备份
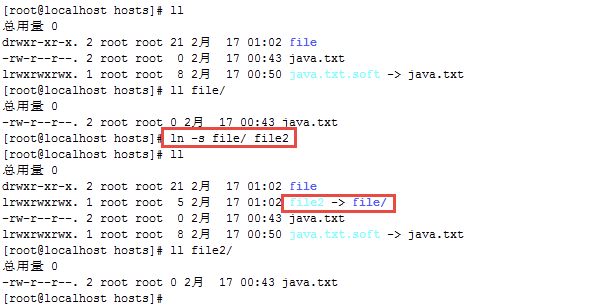
给目录创建一个软链接
“ln -n” 命令实例说明

创建软链接失败实例说明
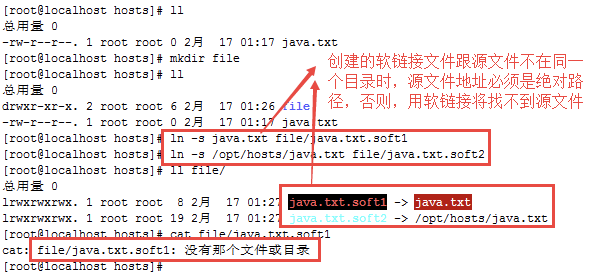
特别说明
- 创建软链接时,如果软链接文件跟源文件不在同一个目录,那么源文件地址必须为绝对路径,否则创建出来的软链接
无法使用。 - 不能针对文件创建硬链接。“linux系统中的硬连接有两个限制:不能跨越文件系统和不允许普通用户对目录作硬连接。
至于第一个限制,很好理解,而第二个就不那么好理解了。 我们对任何一个目录用ls -l命令都可以看到其连接数至少
是2,这也说明了系统中是存在硬连接的,而且命令ln -d也可以让超级用户对目录作硬连接,这些都说明了系统限制对
目录进行硬连接只是一个硬性规定,并不是逻辑上不允许或技术上的不可行。那么操作系统为什么要进行限制呢?如果引
入了对目录的硬连接就有可能在目录中引入循环,那么在目录遍历的时候系统就会陷入无限循环当中。也许你会说,符号
连接不也可以引入循环吗,那么为什么不限制目录的符号连接呢?原因就在于在linux系统中,每个文件(目录也是文件)
都对应着一个inode结构,其中inode数据结构中包含了文件类型(目录,普通文件,符号连接文件等等)的信息,也就是
说操作系统在遍历目录时可以判断出符号连接,既然可以判断出符号连接当然就可以采取一些措施来防范进入过大的循环
了,系统在连续遇到8个符号连接后就停止遍历,这就是为什么对目录符号连接不会进入死循环的原因了。但是对于硬连接
,由于操作系统中采用的数据结构和算法限制,目前是不能防这种死循环的。”
history指令
1.history 显示历史命令
- 作用:用于显示历史记录和执行过的指令命令
- 当登录shell或者是退出的时候会自动进行读取和存储
1.常用参数
1 | 语法: |
2.常用范例
1.获取历史记录的最新2两条
1 | [root@localhost ~]# history 2 |
2.执行最后一次命令
1 | [root@localhost ~]# !! |
3.清空当前历史记录(只是清空缓存中的历史记录,伪删除)
-c 参数是清空所有历史记录
1 | [root@localhost ~] |
这种方式类似于clear,并不会文件中的历史记录删除,如果要真正的历史记录,需要用文本中第3条关于history的配置文件.
4.将当前缓存中的历史记录写入文件(缓存中的记录是空的-用空的数据写入文件,将文件内部删除)
1 | [root@localhost ~] |
5.删除某行历史记录(这样可以有针对性的保留历史记录)
1 | 删除第25行历史记录 |
6.!+数字 代表执行历史中第n条命令
1 | [root@localhost ~]# !30 |
7.!+字符串 代表搜索历史命令最近一个以xxxx字符开头的命令
1 | [root@localhost ~]# cd /etc/sysconfig/network-scripts/ |
8.crtl+r 输入某条命令的关键字,找出对应的命令,按右光标键
在终端中按捉 [Ctrl] 键的同时 [r] 键,出现提示:(reverse-i-search),
此时你尝试一下输入你以前输入过的命令,当你每输入一个字符的时候,终端都会滚动显示你的历史命令。
当显示到你想找的合适的历史命令的时候,直接 [Enter],就执行了历史命令。
3.关于history的配置文件
- 所有我们用history命令看到的历史记录,都默认保存在:~/.bash_history;
- 如果是root用户就是在/root/.bash_history文件里;
- 直接删除这个文件会清除历史记录,再登陆系统会自动重新生成这个文件
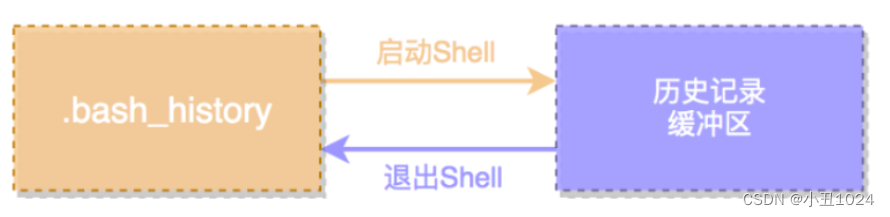
- Linux命令的历史记录,会持久化存储,默认位置是当前用户家目录的 .bash_history 文件中,读取历史记录,存储在相应内存的缓冲区中
- 我们平时操纵的Linux命令,都会记录在缓冲区中,包括history命令所执行的历史命令管理,都是在操纵缓冲区,而不是直接操纵.bash_history文件
- 当我们退出shell时,比如按下 Ctrl+D 时,shell进程会把历史记录缓冲区的内容,写回到.bash_history 文件中
时间与日期日历指令-date 与 cal
一、date指令
date指令用处较多,下面一个一个来介绍
1.显示当前系统日期时间
举个例子,显示当前系统日期,直接写
1 | date |
给大家看一下它的一个格式

当然,我们也可以让它只显示你想显示的日期格式
比如
显示当前年份
1 | date +%Y |
显示当前月份
1 | date +%m |
显示当前是哪一天
1 | date +%d |
显示当前的年月日
1 | date "+%Y-%m-%d" |
显示当前时间的年月日时分秒
1 | date "+%Y-%m-%d %H:%M:%S" |
2.设置系统日期
1 | date -s "日期字符串" |
比如把系统时间设置成2022年6月20日9点33分50秒
1 | date -s "2022-6-20 9:33:50" |
二、cal指令
cal指令用于查看日历
比如,查看当前日历
1 | cal |
如果我想查看2020年的日历
1 | cal 2020 |
如果我想查看2020年6月份的日历
1 | cal 6 2020 |
查找指令
在使用 Linux 系统的时候,我们经常会需要查找某些文件,但是大多数情况下我们并不能确定这些文件的具体位置,这样的话就非常浪费我们的时间。Linux 为我们提供了很多的用于文件搜索的命令,如果需求比较简单可以使用 locate,which,whereis 来完成搜索,如果需求复杂可以使用 find, grep 进行搜索。其中 which 在前边已经介绍过了, 使用方法和功能就直接略过了,whereis 局限性太大,不常用这里也就不介绍了。
1. find(查文件)
find 是 Linux 中一个搜索功能非常强大的工具,它的主要功能是根据文件的属性,查找对应的磁盘文件,比如说我们常用的一些属性 文件名 , 文件类型 , 文件大小 , 文件的目录深度 等,下面基于这些常用数据来讲解一些具体的使用方法。
如果想用通过属性对文件进行搜索, 只需要指定出属性对应的参数就可以了, 下面将依次进行介绍。
1.1 文件名 (-name)
根据文件名进行搜索有两种方式: 精确查询和模糊查询。关于模糊查询必须要使用对应的通配符,最常用的有两个, 分别为 * 和 ?。其中 * 可以匹配零个或者多个字符, ?用于匹配单个字符。
如果我们进行模糊查询,建议(非必须)将带有通配符的文件名写到引号中(单引号或者双引号都可以),这样可以避免搜索命令执行失败(如果不加引号,某些情况下会这样)。
如果需要根据文件名进行搜索,需要使用参数 -name。
1 | # 语法格式: 根据文件名搜索 |
根据文件名搜索举例:
1 | # 模式搜索 |
1.2 文件类型 (-type)
在前边文章中已经介绍过 Linux 中有 7 中文件类型 , 如果有去求我们可以通过 find 对指定类型的文件进行搜索,该属性对应的参数为 -type。其中每种类型都有对应的关键字,如下表:
| 文件类型 | 类型的字符描述 |
|---|---|
| 普通文件类型 | f |
| 目录类型 | d |
| 软连接类型 | l |
| 字符设备类型 | c |
| 块设备类型 | b |
| 管道类型 | p |
| 本地套接字类型 | s |
1 | # 语法格式: |
根据文件类型搜索举例:
1 | # 搜索 root 用户家目录下, 软连接类型的文件 |
1.3 文件大小 (-size)
如果需要根据文件大小进行搜索,需要使用参数 -size。关于文件大小的单位有很多,可以根据实际需求选择,常用的分别有 k(小写), M(大写), G(大写)。
在进行文件大小判断的时候,需要指定相应的范围,涉及的符号有两个分别为:加号 (+) 和 减号 (-),下面具体说明其使用方法:
1 | # 语法格式: |
关于文件大小的区间划分非常重要,请仔细阅读,并思考,可以自己画个图,这里以 4k 来举例:
- -size 4k 表示的区间为 (4-1k,4k], 表示一个区间,大于 3k, 小于等于 4k
- -size -4k: [0k, 4-1k], 表示一个区间,大于等于 0 并且 小于等于 3k
- -size +4k: (4k, 正无穷), 表示搜索大于 4k 的文件
根据文件大小搜索举例:
1 | # 搜索当前目录下 大于1M的所有文件 (file>3M) |
1.4 目录层级
因为 Linux 的目录是树状结构,所有目录可能有很多层,在搜索某些属性的时候可以指定只搜索某几层目录,相关的参数有两个,分别为: -maxdepth 和 -mindepth。
这两个参数不能单独使用, 必须和其他属性一起使用,也就是搜索某几层目录中满足条件的文件。
- -maxdepth: 最多搜索到第多少层目录,
- -mindepth: 至少从第多少层开始搜索
下面通过 find 搜索某几层目录中文件名满足条件的文件:
1 | # 查找文件, 从根目录开始, 最多搜索5层, 这个文件叫做 *.txt (1 <= 层数 <= 5) |
1.5 同时执行多个操作
在搜索文件的时候如果想在一个 find 执行多个操作,通过使用管道 (|) 的方式是行不通的,比如下面的操作:
1 | # 比如: 通过find搜索最多两层目录中后缀为 .txt 的文件, 然后再查看这些满足条件的文件的详细信息 |
如果想要实现上面的需求,需要在 find 中使用 exec, ok, xargs, 这样就可以在 find 命令执行完毕之后,再执行其他的子命令了。
1.5.1 exec
-exec 是 find 的参数,可以在exec参数后添加其他需要被执行的shell命令。
find 添加了 exec 参数之后,命令的尾部需要加一个后缀 {} ;, 注意 {} 和 \ 之间需要有一个空格。
在参数 -exec 后添加的 shell 命令处理的是 find 搜索之后的结果,find 的结果会作为 新添加的 shell 命令 的输入,最后在终端上输出最终的处理结果。
1 | # 语法: |
命令的使用效果演示:
1 | # 搜索最多两层目录, 文件名后缀为 .txt的文件 |
1.5.2 ok
-ok 和 -exec 都是 find 命令的参数,使用方式类似,但是这个参数是交互式的,在处理 find 的结果的时候,会向用户发起询问,比如在删除搜索结果的时候,为了保险起见,就需要询问机制了。
语法格式如下:
1 | # 语法: 其实就是将 -exec 替换为 -ok, 其他都不变 |
命令效果演示:
1 | # 搜索到了2个满足条件的文件 |
1.5.3 xargs
在使用 find 的 -exec 参数的时候,需要在指定的子命令尾部添加几个特殊字符 {} ;,一不小心就容易写错,有一种看起来更加直观、书写更加简便的方式,我们可以使用 xargs 替换掉 -exec 参数,而且在处理数据的时候 xargs更高效。有了 xargs 的加持我们就可以在 find 命令中直接使用管道完成前后命令的数据传递,使用方法如下:
1 | # 在find 中 使用 xargs 关键字我们就可以使用管道了, 否则使用管道也不会起作用 |
命令效果演示:
1 | # 查找文件 |
2. grep(查文件里具体内容)
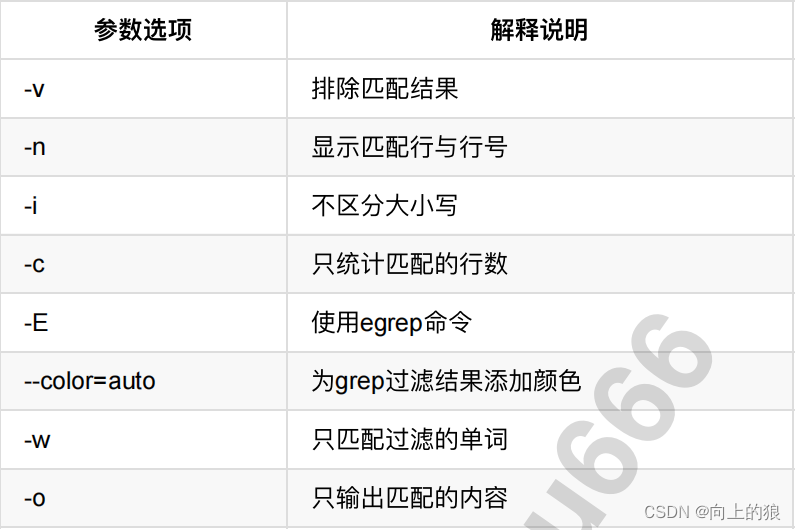
一、grep基本介绍
全拼:Global search REgular expression and Print out the line.
作用:文本搜索工具,根据用户指定的“模式(过滤条件)”对目标文本逐行进行匹配检查,打印匹配到的行.
模式:由正则表达式的元字符及文本字符所编写出的过滤条件﹔

grep命令是Linux系统中最重要的命令之一,功能是从文本文件或管道数据流中筛选匹配的行和数据,如果再配合正则表达式,功能十分强大,是Linux运维人员必备的命令
grep命令里的匹配模式就是你想要找的东西,可以是普通的文字符号,也可以是正则表达式
二、正则表达式grep实践
首先先看一下这个测试文件的内容吧

2.1、输出以 I 开头的行(不区分大小写)

注: 这里的-i代表不区分大小写, -n代表显示匹配行和行号
2.2、输出以.结尾的行

注: 因为.在这里有着特殊含义, 所以要用\转义一下, 如果不加转义字符的话, grep就会把它当做正则表达式来处理(.代表的含义是匹配任意一个字符)
2.3、$符号
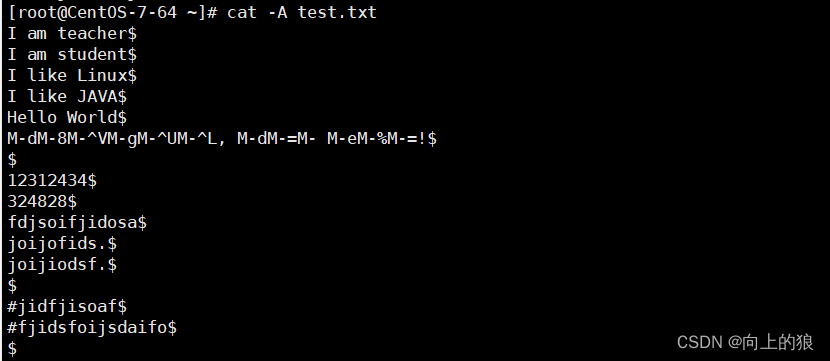
- 注意在Linux平台下, 所有文件的结尾都有一个$符
- 可以利用cat -A 查看文件
2.4、^$(代表空行的意思)组合符
找出文件的空行, 以及行号

2.5、.点符号
"."点表示任意一个字符, 有且只有一个, 不包含空行

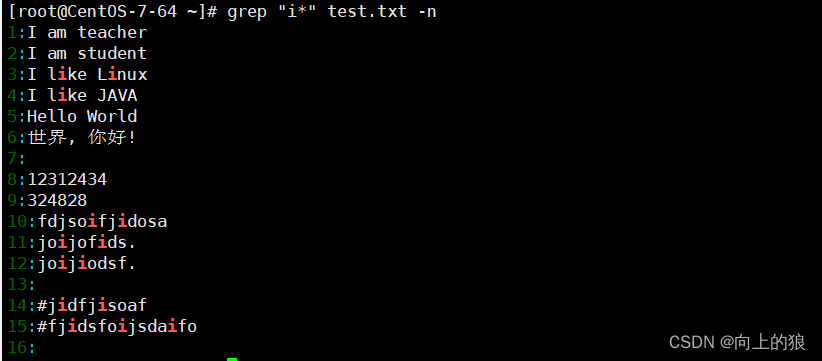
2.6、*符号
"*"表示找出前一个字符0次或一次以上
找出文件中i出现0次或多次的行和行号
2.7、.*组合符
".*"表示所有内容, 包括空行
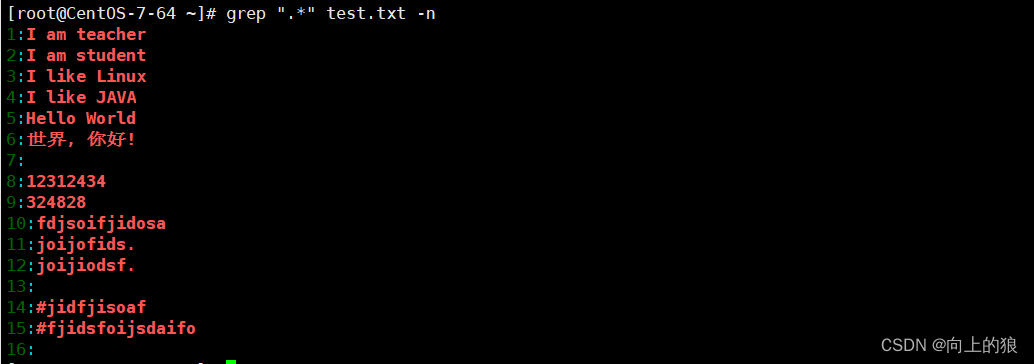
2.8、^.*t符 (含义: 以任意内容开头, 直到t结束)

2.9、[abc]中括号
中括号表达式,[abc]表示匹配中括号中任意一个字符, a或b或c,常见的形式如下;
- [a-z]匹配所有小写单个字母[A-Z]匹配所有单个大写字母
- [a-zA-Z]匹配所有的单个大小写字母
- [0-9]匹配所有单个数字
- [a-zA-ZO-9]匹配所有数字和字母
匹配abc字符中的任意一个,得到它的行数和行号

2.10、grep的参数-o
使用"-o"选项, 可以值显示被匹配到的关键字, 而不是讲整行的内容都输出.
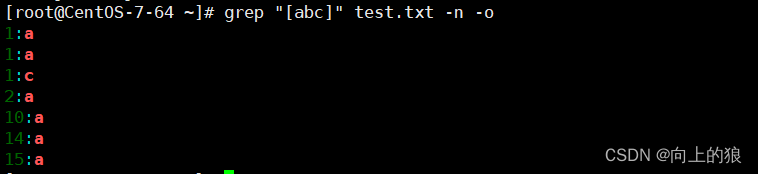
显示出文章中有多少行有a

"-c"只统计匹配的行数
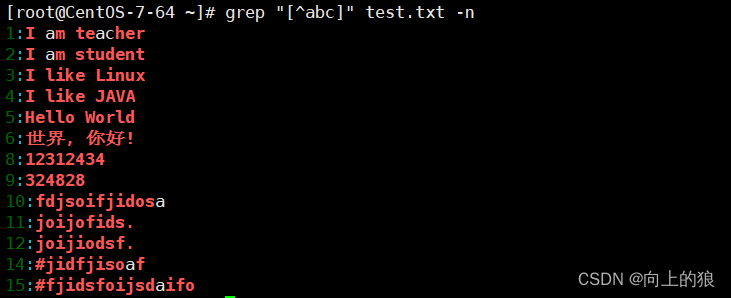
2.11、[^abc]中括号中去反
[^abc]或[^a-c]这样的命令, "^"符号在中括号中第一位表示排除, 就是排除字符a,b,c
注: 出现再中括号里的尖角号表示取反
三、扩展正则表达式grep实践
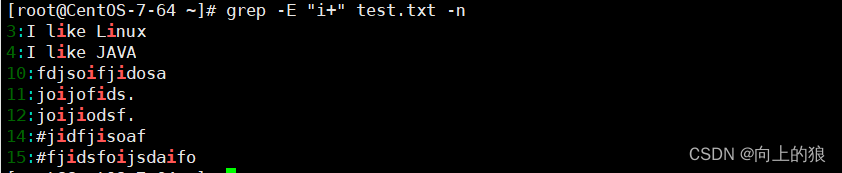
此处使用grep -E进行实践扩展正则, egrep官网已经弃用了
3.1、+号
+号表示匹配前一个字符1一次或多次,必须使用grep-E扩展正则
3.2、?符
匹配前一个字符0次或1次
找出文件中包含gd或者god的行

3.3、|符
竖线|再正则中是或者的意思
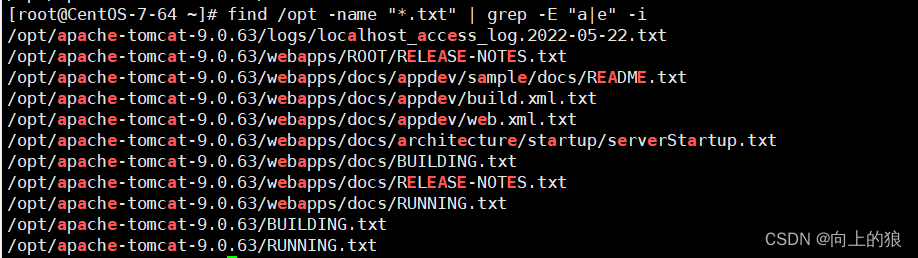
找出opt目录中txt结尾的文件, 其名字中包含a或者e, 不区分大小写(-i)
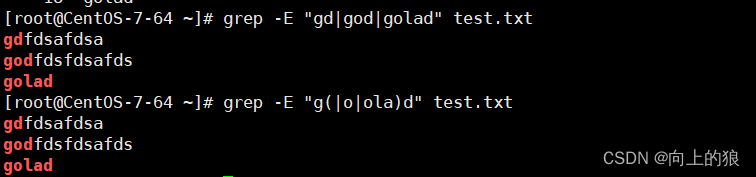
3.4、()小括号
将一个或多个字符捆绑在一起, 当作一个整体进行处理
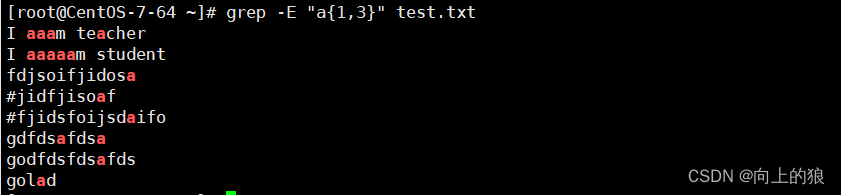
3.5、{n,m}匹配次数
{n,m}:匹配前一个字符至少n次, 最多m次
{n,}: 匹配前一个字符至少n次, 没有上限
{,m}: 匹配前一个字符最多m次,可以没有*
重复前一个字符各种次数, 可以通过-o参数显示明确的匹配过程
3.locate(查文件)
我们可以将 locate 看作是一个简化版的 find, 使用这个命令我们可以根据文件名搜索本地的磁盘文件 , 但是 locate的效率比find要高很多。原因在于它不搜索具体目录,而是搜索一个本地的数据库文件,这个数据库中含有本地所有文件信息。Linux 系统自动创建这个数据库,并且每天自动更新一次,所以使用 locate 命令查不到最新变动过的文件。为了避免这种情况,可以在使用locate之前,先使用updatedb命令,手动更新数据库。
1 | # 使用管理员权限更新本地数据库文件, root用户这样做 |
locate 有一些常用参数,使用之前先来介绍一下:
搜索所有目录下以某个关键字开头的文件
1 | $ locate test # 搜索所有目录下以 test 开头的文件 |
搜索指定目录下以某个关键字开头的文件,指定的目录必须要使用绝对路径
1 | $ locate /home/robin/test # 指定搜索目录为 /home/robin/, 文件以 test 开头 |
搜索文件的时候,忽略文件名的大小写,使用参数 -i
1 | $ locate TEST -i # 文件名以小写的test为前缀的文件也能被搜索到 |
列出前 N 个匹配到的文件名称或路径名称,使用参数 -n
1 | $ locate test -n 5 # 搜索文件前缀为 test 的文件, 并且只显示5条信息 |
基于正则表达式进行文件名匹配,查找符合条件的文件,使用参数 -r
1 | # 使用该参数, 需要有正则表达式基础 |
正则表达式小科普:
- 在正则表达式中 . 可以匹配任意一个 非 \n 的单字符
- 上边的命令中使用转译字符 \ 对特殊字符. 转译,就得到了普通的字符.
- 在正则表达式中 $ 放到字符尾部,表示字符串必须以这个字符结尾,上边的命令中修饰的是字符 p
- 正则表达式中的 字符 c 和后边的字符 p 需要进行字节匹配,没有特殊含义
- 通过上面的解释就能明白 .cpp$ 说的就是以 .cpp 结尾的字符串
4.whereis命令(查找二进制)
在Linux中,可执行文件被称为二进制文件,如果你想定位一个二进制文件,whereis比locate更加有效。
1 | whereis binary |
这个命令将返回二进制文件的位置,以及它的源代码和手册页,如果有的话。
1 | whereis aircrack-ng |

5.which命令(查找二进制)
Linux中的PATH变量存放着操作系统寻找你在命令行中执行的命令的目录。
1 | which binary |
which命令在你的PATH中找到一个二进制文件。如果它在当前PATH中没有找到该二进制文件,它就什么也不返回。
1 | which aircrack-ng |

这些目录通常包括/usr/bin,但也可能包括/usr/sbin和其他一些目录。
打包压缩与解压命令
zip与unzip命令
zip 用于压缩文件,压缩为*.zip文件。 unzip 用于解开被zip压缩过的文件。
(1) zip [选项] 压缩后的名称 文件或目录
选项:
选项较多,不一一详细介绍。
-d :从压缩文件内删除指定的文件;
-r :递归处理,将指定目录下的所有文件和子目录一并处理;
例:
zip aa aa.txt 在当前目录下将aa.txt压缩为aa.zip文件
zip -r myx /tmp/xxx 将xxx目录及其内容压缩为myx.zip文件
(2) unzip [选项] 解压到的目录 *.zip文件
选项:
选项较多,不一一详细介绍。
-d<目录> :指定文件解压缩后所要存储的目录;
例:
unzip aa.zip 在当前目录下将aa.zip文件解压
unzip aa.zip -d /tmp/yyy 或 unzip -d /tmp/yyy aa.zip 将aa.zip解压到/tmp/yyy目录下
gzip与gunzip命令
gzip 用于压缩文件,压缩为*.gz文件。 gunzip 用于解开被gzip压缩过的文件。
(1) gzip [选项] 文件
选项:
选项较多,不一一详细介绍。
-d :解开压缩文件。
例:
gzip aa.txt 将aa.txt压缩为aa.txt.gz文件
gzip aa.txt bb.txt 将两个文件分别压缩为*.gz文件
gzip -d aa.txt.gz 将aa.txt.gz文件解压为aa.txt文件
补充:
当使用gzip命令压缩文件时,不会保留原文件。
(2) gunzip [选项] *.gz文件
选项:
没有什么重要的选项
例:
gunzip aa.txt.gz 将aa.txt.gz文件解压为aa.txt文件
tar命令
打包命令,打包后的文件是 .tar.gz 的文件。
tar [选项] 文件或目录
选项:
选项较多,不一一详细介绍。
-c :产生.tar打包文件
-v :显示详细信息
-f :指定压缩后的文件名
-z :用gzip进行解压或压缩
-x :解包.tar文件
-C <目录>:这个选项用在解压缩,若要在特定目录解压缩,可以使用这个选项。
打包用解压用zxcf
例:
tar -zcvf myfile.tar.gz a.txt b.txt
在当前目录下将a.txt、b.txt这两个文件一块打包成myfile.tar.gz文件
tar -zxvf myfile.tar.gz
将myfile.tar.gz文件解压到当前目录
tar -zcvf myfile.tar.gz /tmp/xxx
在当前目录下将/tmp/xxx目录及其内容一块打包成myfile.tar.gz文件
tar -zxvf myfile.tar.gz -C /tmp/mydir
将myfile.tar.gz文件解压到/tmp/mydir目录下
切割指令
cut命令详解
cut的工作就是“剪”,具体的说就是在文件中负责剪切数据用的。cut 命令从文件的每一行剪切字节、字符和字段并将这些字节、字符和字段输出。注意,cut一行为一个单位切割的,每一行相互独立
一、基本语法
1 | cut [选项参数] filename |
说明:默认分隔符是制表符。
选项与参数:
-d:分隔符,按照指定分隔符分割列。与 -f 一起使用
-f:依据 -d 的分隔字符将一段信息分割成为数段,用 -f 取出第几段的意思(列号,提取第几列)
-c:以字符 (characters) 的单位取出固定字符区间
-b:以字节为单位进行分割
二、实操案例
准备数据
1 | [root@jiangnan data]$ touch cut.txt |
- 切割cut.txt第一列
1 | [root@jiangnan data]# cut -d ' ' -f 1 cut.txt |
注意双引号里面是空格,因为要以空格作为分隔符。
- 切割cut.txt第二、三列
1 | [root@jiangnan data]# cut -d ' ' -f 2,3 cut.txt |
注意后面三个的前面是有一个空格的,因为我们在准备数据的时候就写了两个空格。
- 切割cut.txt的第5-8个字符
1 | [root@jiangnan data]# cut -c 5-8 cut.txt |
- 切割cut.txt的第2,4,6个字节
1 | [root@jiangnan data]# cut -b 2,4,6 cut.txt |
可以看出纯英文状态下字节和字符等效。
- 切割cut.txt的第6个字节以前的内容
1 | [root@jiangnan data]# cut -b -6 cut.txt |
- 切割字符串中的汉字
1 | [root@jiangnan data]# echo "我爱你中国" | cut -c 2,3 |
对于汉字的切割最好使用-c(字符),字节(-b)无法满足要求。
- 在cut.txt文件中切割出guan
1 | [root@jiangnan data]# cat cut.txt | grep "guan" | cut -d " " -f 1 |
- 选取系统PATH变量值,第1个“:”开始后的所有路径:
1 | [root@jiangnan data]# echo $PATH |
三、cut有哪些缺陷和不足
如果文件里面的某些域是由若干个空格来间隔的,那么用cut就有点麻烦了,因为cut只擅长处理“以一个字符间隔”的文本内容。
awk 命令
一个强大的文本分析工具,把文件逐行的读入,以空格为默认分隔符将每行切片,切开的部分再进行分析处理。
1. 基本用法
1 | awk [选项参数] 'pattern1{action1} pattern2{action2}...' filename |
pattern:表示AWK在数据中查找的内容,就是匹配模式。action:在找到匹配内容时所执行的一系列命令。
注意:行匹配语句 awk 只能用单引号。单引号内部可以使用双引号,但是顺序不能错。
2. 工作流程
读入有’\n’换行符分割的一条记录,然后将记录按指定的域分隔符划分域,填充域,$0则表示所有域,$1表示第一个域,$n表示第n个域,$NF表示文本行中的最后一个数据字段。默认域分隔符是"空白键" 或 “[tab]键”。
3. 常用选项参数说明
- -F:指定输入文件折分隔符。
- -v:赋值一个用户定义变量。
- -f:引入awk执行脚本。
4. 实操案例
准备数据
1 | [root@jiangnan awk]# cp /etc/passwd ./ |
- 搜索passwd文件以root关键字开头的所有行,并输出该行的第7列。
1 | [root@jiangnan awk]# awk -F: '/^root/{print $7}' passwd |
-F,指定分隔符为
:。print,打印。$7,第7列(域)。
^在root前,表示以指定字符开头,如果没有,则表示有指定字符的行,位置不限。
- 搜索passwd文件以root关键字开头的所有行,并输出该行的第1列和第7列,中间以","号分割。
1 | [root@jiangnan awk]# awk -F: '/^root/{print $1","$7}' passwd |
注意:只有匹配了pattern的行才会执行action。
- 将passwd文件中的用户id增加数值1并输出
1 | [root@jiangnan awk]# awk -v i=1 -F: '{print $3+i}' passwd |
-v:赋值一个用户定义变量
- 如果awk命令是日常重复工作,而又没有太多变化,可以将程序写入文件,每次使用-f调用程序文件就好,方便、高效。
1 | [root@jiangnan awk]# cat abc |
-f:引入awk执行脚本。
- 只显示passwd的第一列和第七列,以逗号分割,且在行前面添加列名user,shell在最后一行添加"dahaige,/bin/zuishuai"。
1 | [root@jiangnan awk]# awk -F : 'BEGIN{print "user, shell"} {print $1","$7} END{print "dahaige,/bin/zuishuai"}' passwd |
注意:BEGIN 在所有数据读取行之前执行;END 在所有数据执行之后执行。
5. 常用awk的内置变量
| 变量 | 说明 |
|---|---|
| FILENAME | awk浏览的文件名 |
| NR | 已读的记录数 |
| NF | 浏览记录的域的个数 |
- 统计passwd文件名,每行的行号,每行的列数。
1 | [root@jiangnan awk]# awk -F: '{print "filename:" FILENAME ", linenumber:" NR ",columns:" NF}' passwd |
- 查询sed.txt中空行所在的行号
1 | [root@jiangnan awk]# cat sed.txt |
- 输出passwd第3行的所有数据
1 | [root@jiangnan awk]# awk 'NR==3{print $0}' passwd |
- 输出passwd第5行的第6个字段
1 | [root@jiangnan awk]# awk -F: 'NR==5{print $6}' passwd |
- 输出第一个字段为root所在的行
1 | [root@jiangnan awk]# awk -F: '$1=="root"{print $0}' passwd |
以上案例要注意需要指定切割符
:
- 查看已使用的内存
1 | [root@jiangnan awk]# head -2 /proc/meminfo | awk 'NR==1{a=$2}NR==2{b=$2;print (a-b)*100/a "%"}' |
6. awk程序的优先级
BEGIN是优先级最高的代码块,是在执行PROGRAM之前执行的,不需要提供数据源,因为不涉及到任何数据的处理,也不依赖与PROGRAM代码块;PROGRAM是对数据流干什么,是必选代码块,也是默认代码块。所以在执行时必须提供数据源;END是处理完数据流后的操作,如果需要执行END代码块,就必须需要PROGRAM的支持,单个无法执行。
总结起来awk程序运行优先级是:
- 1)BEGIN: 在开始处理数据流之前执行,可选项
- 2)program: 如何处理数据流,必选项
- 3)END: 处理完数据流后执行,可选项
1 | [root@jiangnan awk]# awk 'BEGIN{print "hello ayitula"}{print $0}END{print "bye ayitula"}' sed.txt |
可以看出BEGIN不需要数据源(sed.txt)就可以执行。
1 | [root@jiangnan awk]# awk 'END{print "hello world"}' |
END没有数据源则无法执行。
tcpdump抓包指令
1.精简版:
Linux下使用tcpdump:抓包的实现方法
很多时候我们的系统部署在Liux系统上面,在一些情况下定位问题就需要查看各个系统之间发送数据报文是否正常,下面我就简单讲解一下如何使用tcpdumpi抓包
tcpdump;是Linux下面的一个开源的抓包工具,和Windows"下面的wiresharkj抓包工具一样,支持抓取指定网口、指定目的地址、指定源地址、指定端口、指定协议的数据。
1 | 1、安装tcpdump |
2.复杂版
Tcpdum是Linux上强大的网络数据采集分析工具。
tcpdump选项可划分为四大类型:
1.控制抓包行为
2.控制信息如何显示
3.控制显示什么数据
4.过滤命令
1 | #tcpdump --help |
抓包文件保存:
1 | #tcpdump -i any -s 0 -X -w /tmp/tcpdump.pcap |
抓包文件解析:
1 | #tcpdump -A -r /tmp/tcpdump.pcap|less |
1. 控制抓包行为
这一类命令行选项影响抓包行为,包括数据收集的方式。之前已介绍了两个例子:-r 和 -w。
-w 选项允许用户将输出重定向到一个文件,之后可通过-r选项将捕获数据显示出来。
如果用户知道需要捕获的报文数量或对于数量有一个上限,可使用-c选项。
则当达到该数量时程序自动终止,而无需使用kill命令或Ctrl-C。
如收集到100个报文之后tcpdump终止:
1 | tcpdump -c 100 |
通过 -i 选项指定接口。在不确定的情况下,可使用ifconfig -a来检查哪一个接口可用及对应哪一个网络。
1 | #tcpdump -i enp131s0 icmp |
通过 -p 选项将网卡接口设置为非混杂模式。这一选项理论上将限制为捕获接口上的正常数据流,来自或发往主机,多播数据,以及广播数据。
-s 选项控制数据的截取长度。通常,tcpdump默认为一最大字节数量并只会从单一报文中截取到该数量长度。实际字节数取决于操作系统的设备驱动。通过默认值来截取合适的报文头,而舍弃不必要的报文数据。
如果用户需截取更多数据,通过-s选项来指定字节数。也可以用-s来减少截取字节数。
对于少于或等于200字节的报文,以下命令会截取完整报文:
1 |
2. 控制信息如何显示
1 | #tcpdump -n -tt -i bond_mgmt port 22 |
-a,-n,-N和-f选项决定了地址信息是如何显示的。
-a 选项强制将网络地址显示为名称。
-n 阻止将地址显示为名字。
-N 阻止将域名转换。
-f 选项阻止远端名称解析。
-t 和 -tt 选项控制时间戳的打印。-t选项不显示时间戳而 -tt 选项显示无格式的时间戳。
3. 控制显示什么数据
可以通过 -v 和 -vv 选项来打印更多详细信息。例如,-v选项将会打印TTL字段。
要显示较少信息,使用 -q,或quiet选项。
-e 选项用于显示链路层头信息。上例中-e选项的输出为:
1 | #tcpdump -ne -tt -i bond_mgmt port 22 |
-x 选项将报文以十六进制形式dump出来,排除了链路层报文头。-x 和 -vv 选项报文显示如下:
1 | #tcpdump -ne -v -x -i bond_mgmt port 22 |
4. 过滤命令
要有效地使用tcpdump,掌握过滤器非常必要的。过滤允许用户指定想要抓取的数据流,从而用户可以专注于感兴趣的数据。
如果用户很清楚对何种数据流不感兴趣,可以将这部分数据排除在外。如果用户不确定需要什么数据,可以将源数据收集到文件之后再读取时应用过滤器。
实际应用中,需要经常在两种方式之间转换。
简单的过滤器是加在命令行之后的关键字。但是,复杂的命令是由逻辑和关系运算符构成的。对于这样的情况,通常最好用-F选项将过滤器存储在文件中。
1 | 非 : ! or "not" (without the quotes) |
4.1 地址过滤
过滤器可以按照ip地址选择数据流。例如,考虑如下命令:
1 | #tcpdump -ne -i bond_virt host 192.168.1.1 |
通过机器的以太网mac地址来选择数据流:
1 | #tcpdump -ne -i bond_virt ether host fa:16:3e:ed:88:5a |
数据流可进一步限制为单向,分别用src或dst指定数据流的来源或目的地。
1 | #tcpdump -ne -i bond_virt dst 192.168.1.4 |
广播和多播数据相应可以使用broadcast和multicast。由于多播和广播数据流在链路层和网络层所指定的数据流是不同的,所以这两种过滤器各有两种形式。过滤器ether multicast抓取以太网多播地址的数据流,ip multicast抓取IP多播地址数据流。广播数据流也是类似的使用方法。注意多播过滤器也会抓到广播数据流。
除了抓取特定主机以外,还可以抓取特定网络。例如,以下命令限制抓取来自或发往224.0.0的vrrp报文:
1 | #tcpdump -ne -i bond_virt net 224.0.0 |
抓取目的地址是192.168.1.254或192.168.1.200端口是80的TCP数据
1 |
4.2 协议及端口过滤
制抓取指定协议如IP,UDP或TCP。还可以限制建立在这些协议之上的服务,如DNS或HTTP。这类抓取可以通过三种方式进行:使用tcpdump关键字,通过协议关键字proto,或通过服务使用port关键字。
当我们继续之前,必须了解tcp/ip包头的头部信息
1 | proto[x:y] : 过滤从x字节开始的y字节数。比如ip[2:2]过滤出2、3字节(第三、第四字节)(第一字节从0开始排) |
操作符:
1 | > : greater 大于 |
一些协议名能够被tcpdump识别到因此可通过关键字来指定。以下命令限制抓取UDP数据流:
1 | # tcpdump -ne -i bond_virt udp |
有很多传输层服务没有可以识别的关键字。在这种情况下,可以使用关键字proto或 ip proto 加上 /etc/protocols能够找到的协议名或相应的协议编号。
1 | # tcpdump -ne -i bond_virt proto 112 |
对于更高层级的建立于底层协议之上的服务,必须使用关键字port。
1 | # tcpdump -nnne -i bond_virt port 137 |
4.3 报文特征过滤
过滤器也可以基于报文特征比如报文长度或特定字段的内容,过滤器必须包含关系运算符。要指定长度,使用关键字less或greater。如下例所示:
1 | # tcpdump -nnne -i bond_virt greater 200 |
该命令收集长度大于200字节的报文。
根据报文内容过滤更加复杂,因为用户必须理解报文头的结构。但是尽管如此,或者说正因如此,这一方式能够使用户最大限度的控制抓取的数据。
4.3.1 IP选项设置(20字节,可变部分(0-20)B,最大40字节)
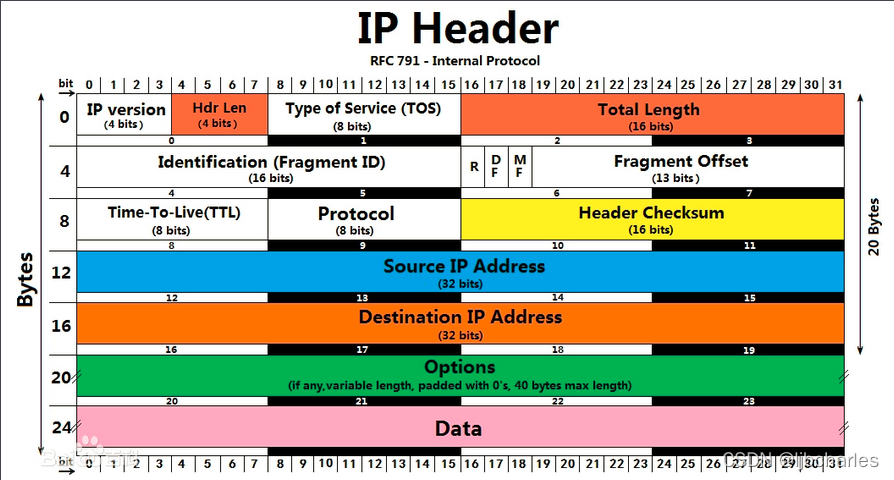
4.3.1.1 IP version & Hdr Len
一般”的IP头是20字节,但IP头有选项设置,不能直接从偏移21字节处读取数据。IP头有个长度字段可以知道头长度是否大于20字节。
通常第一个字节的二进制值是:01000101,分成两个部分:
0100 = 4 表示IP版本 0101 = 5 表示 IP头32 bit的块数,5 x 32 bits = 160 bits or 20 bytes
如果第一字节第二部分的值大于5,那么表示头有IP选项。
- 比较第一字节的值是否大于01000101(十进制等于69),这可以判断IPv4带IP选项的数据和IPv6的数据。
1 |
- 位操作(IPv6的数据也可以匹配)
0100 0101 : 第一字节的二进制
0000 1111 : 与操作
0000 0101 : 结果
1 |
或者
1 |
4.3.1.2 DF分片标记
- Is DF bit (don’t fragment) set?
当发送端的MTU大于到目的路径链路上的MTU时就会被分片
分片信息在IP头的第七和第八字节:
Bit 0: 保留,必须是0
Bit 1: (DF) 0 = 可能分片, 1 = 不分片
Bit 2: (MF) 0 = 最后的分片, 1 = 还有分片
Fragment Offset字段只有在分片的时候才使用。
- :要抓带DF位标记的不分片的包,第七字节的值应该是:01000000 = 64
1 | #tcpdump 'ip[6] = 64' |
- :抓分片包
a:匹配MF,分片包(测试方法:ping -M want -s 3000 114.114.114.114)
1 | # tcpdump -nnne -c 5 -i bond_mgmt 'ip[6] = 32' |
b:匹配分片和最后分片
1 | # tcpdump -nnne -c 10 -i bond_mgmt '((ip[6:2] > 0) and (not ip[6] = 64))' |
4.3.1.3 匹配小于ttl的数据报
TTL字段在第九字节,并且正好是完整的一个字节,TTL最大值是255,二进制为11111111。
可以来验证下,我们试着制定一个特需的ttl长度为 256 (ping -M want -s 3000 -t 256 192.168.1.200 ping: ttl 256 out of range)
1 | # tcpdump -nnne -c 10 -i bond_mgmt 'ip[8] < 80' |
4.3.1.4匹配协议头
一般使用语法 proto [ expr : size ]。字段proto指定要查看的报文头,ip则查看IP头,tcp则查看TCP头,以此类推。
expr字段给出从报文头索引0开始的位移。
即:报文头的第一个字节为0,第二字节为1,以此类推。
size字段是可选的,指定需要使用的字节数,1,2或4。
1 | # tcpdump -nnne -vv -i bond_virt "ip[9] = 6" |
查看第十字节的IP头,协议值为6。注意这里必须使用引号。撇号或引号都可以,但反引号将无法正常工作。
1 | # tcpdump -nnne -vv -i bond_virt "ip[9] = 1" (ICMP的协议值为1) |
这一方式常常作为掩码来选择特定比特位。值可以是十六进制。可通过语法&加上比特掩码来指定。
4.3.2 TCP选项设置(基础长度20字节,最长可达60字节)

4.3.2.1.抓取源端口TCP数据包
- 源端口大于1024的TCP数据包
1 |
or
1 |
4.3.2.2.匹配TCP数据包的特殊标记
TCP标记定义在TCP头的第十四个字节
++++++++++++++
|C|E|U|A|P|R|S|F|
|W|C|R|C|S|S|Y|I|
|R|E|G|K|H|T|N|N|
++++++++++++++
在TCP 3次握手中,两个主机是如何交换数据
1、源端发送 SYN
2、目标端口应答 SYN,ACK
3、源端发送 ACK
只抓取SYN包,第十四字节是二进制的00000010,也就是十进制的2
- 只抓取SYN包,第十四字节是二进制的00000010,也就是十进制的2
1 |
- 抓取 SYN,ACK (00010010 or 18)
1 |
- 抓取SYN 或者 SYN-ACK
1 |
- 抓取PSH-ACK
1 |
- 抓所有包含FIN标记的包(FIN通常和ACK一起)
1 |
- 抓取RST
1 |
- 抓取TCP连接建立及关闭报文。该过滤器跳过TCP头的13个字节,提取flag字节。掩码0x03选择第一和第二比特位,即FIN和SYN位。如果其中一位不为0则报文被抓取。
1 | # tcpdump -nnne -vv -i bond_mgmt "tcp[13] & 0x03 != 0" |
- 如果需要查找端口号大于23的所有TCP数据流,必须从报文头提取端口字段,使用表达式:
1 | # tcpdump -nnne -vv -i bond_mgmt "tcp[0:2] & 0xffff > 0x0017" |
4.3.3.匹配TCP标志位
4.3.3.1 TCP标记值:
tcp-fin, tcp-syn, tcp-rst, tcp-push, tcp-push, tcp-ack, tcp-urg
- 实际上有一个很简单的方法过滤 flags(man pcap-filter and look for tcpflags)
1 |
- 抓取所有的包,用TCP-SYN 或者 TCP-FIN 设置
1 |
下图表示了TCP各状态转换的标记:
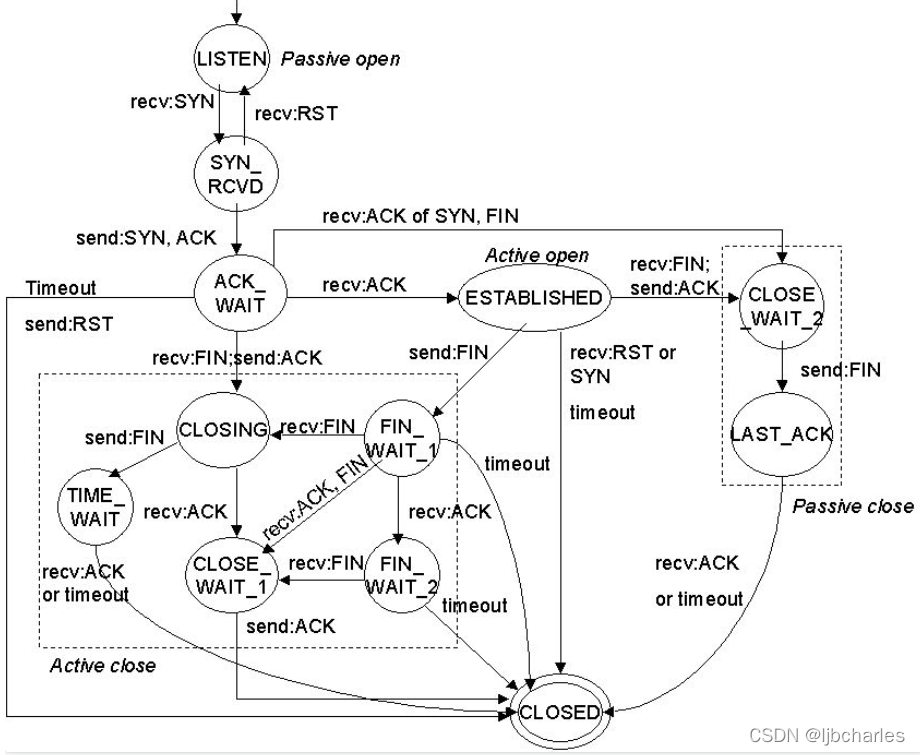
1 | tcpdump 提供了常用的字段偏移名字: |
4.3.3.2 HTTP数据过滤
十六进制转换方法:python -c ‘print “MAIL”.encode(“hex”)’ --> 4d41494c
- 抓取http请求开始头格式为GET / HTTP/1.1\r\n (16 bytes counting the carriage return but not the backslashes !) “GET ” 十六进制是 47455420
1 |
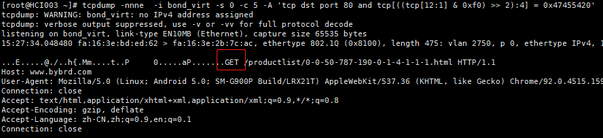
- 查看HTTP GET请求(GET = 0x47, 0x45, 0x54, 0x20),(tcp[12:1] & 0xf0) >> 2 等价于 (tcp[12:1] & 0xf0) /4 ,因为头部的长度为32bit 一个字,偏移量除4获取到data的数组位置。
1 | $offset = ((tcp[12:1] & 0xf0) >> 2) |
- 查看HTTP POST请求(POST = 0x50, 0x4f, 0x53, 0x54))
查看HTTP请求响应头以及数据
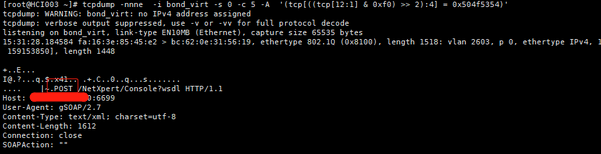
1 |
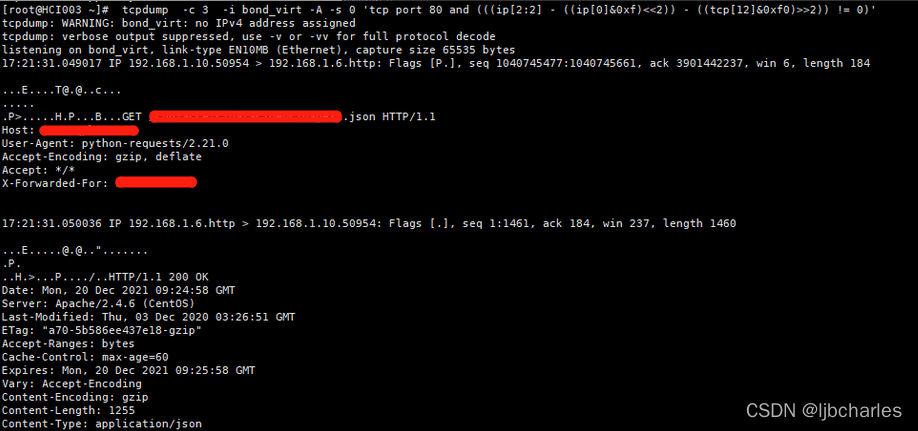
1 | #tcpdump -X -s 0 'tcp port 80 and (((ip[2:2] - ((ip[0]&0xf)<<2)) - ((tcp[12]&0xf0)>>2)) != 0)' |
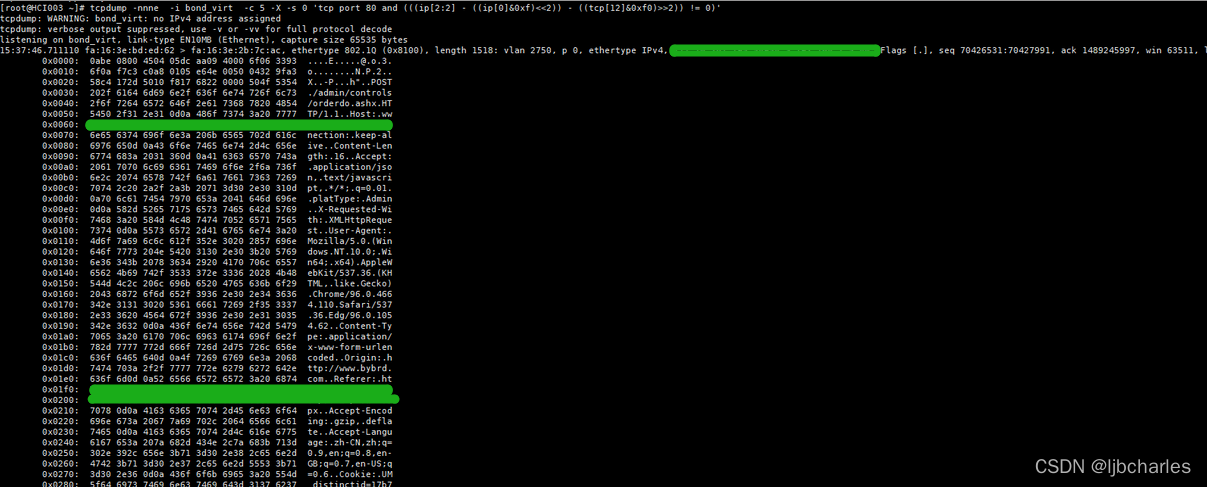
4.3.3.3 wireshark分析http包过滤:
1 | 按请求头、请求体 |
4.3.3.4 使用tcpdump方式抓取uri包:
- 抓取请求:GET /me-a-milkshake-please/ HTTP/1.1
过滤表达式:
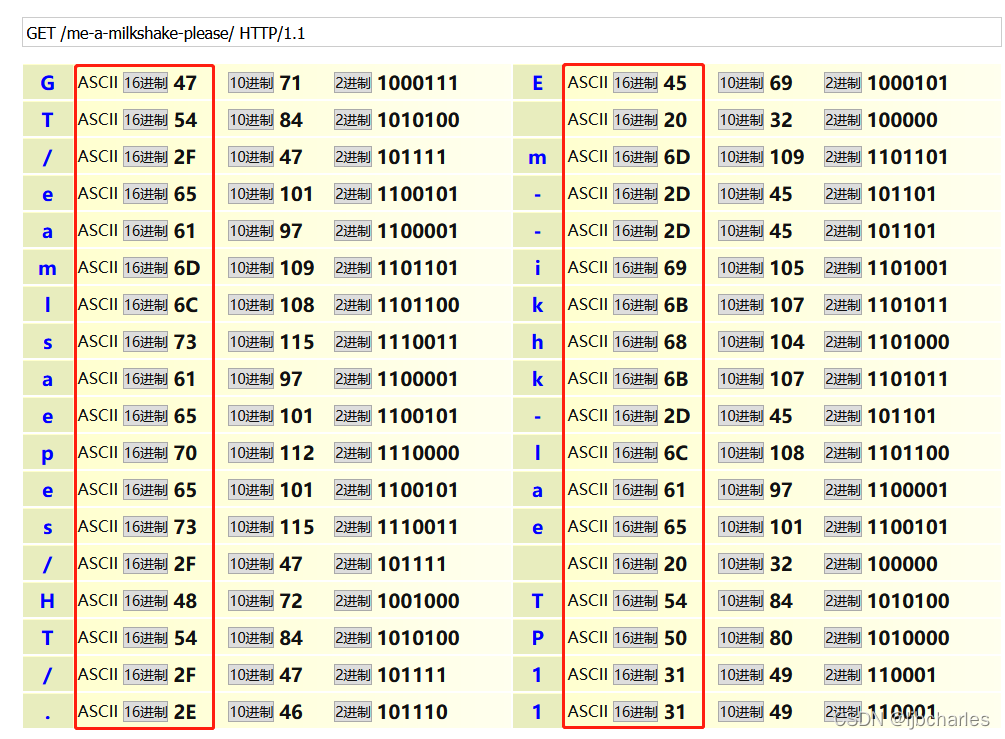
1 | tcp[((tcp[12:1] & 0xf0) >> 2):4] = 0x47455420 && tcp[((tcp[12:1] & 0xf0) >> 2) + 4:4] = 0x2f6d652d && tcp[((tcp[12:1] & 0xf0) >> 2) + 8:4] = 0x612d6d69 && tcp[((tcp[12:1] & 0xf0) >> 2) + 12:4] = 0x6c6b7368 && tcp[((tcp[12:1] & 0xf0) >> 2) + 16:4] = 0x616b652d && tcp[((tcp[12:1] & 0xf0) >> 2) + 20:4] = 0x706c6561 && tcp[((tcp[12:1] & 0xf0) >> 2) + 24:4] = 0x73652f20 && tcp[((tcp[12:1] & 0xf0) >> 2) + 28:4] = 0x48545450 && tcp[((tcp[12:1] & 0xf0) >> 2) + 32:4] = 0x2f312e31 |
- 请求头 GET /productlist…
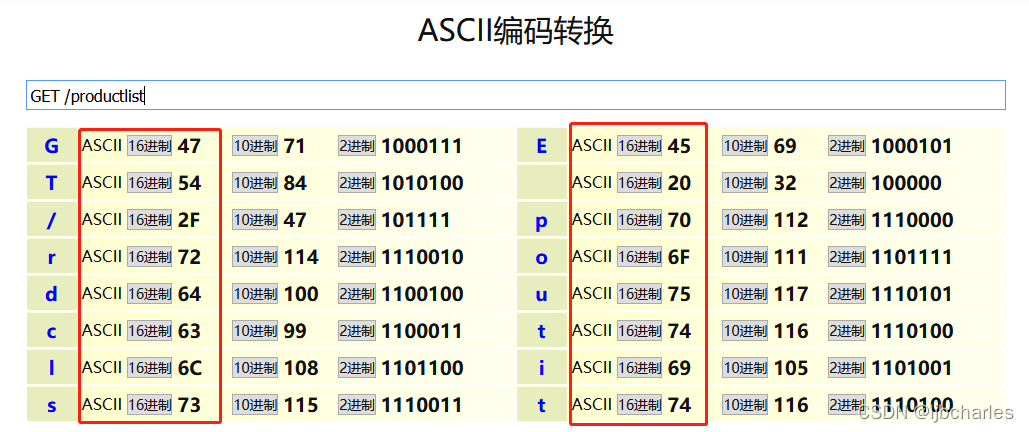
1 | tcp[((tcp[12:1] & 0xf0) >> 2):4] = 0x47455420 && tcp[((tcp[12:1] & 0xf0) >> 2) + 4:4] = 0x2f70726f && tcp[((tcp[12:1] & 0xf0) >> 2) + 8:4] = 0x64756374 && tcp[((tcp[12:1] & 0xf0) >> 2) + 12:4] = 6c697374' |
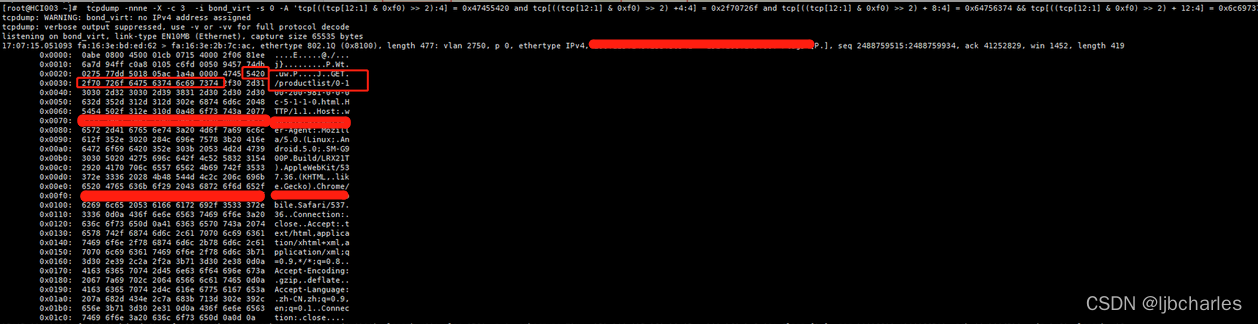
4.3.4 链路层数据头选项设置匹配(18字节)
Ethernet II 帧头:6+6+2+4=18Bytes
目标MAC|源MAC|类型|数据|FCS
最小帧长6+6+2+46+4 = 64字节,最大6+6+2+1500+4 = 1518字节。(注:ISL封装后可达1548字节(ISL标记的长度为30字节,思科私有),802.1Q封装后可达1522字节(+4字节vlan信息))

- 下例提取从以太网头第一字节开始(即目的地址第一字节),提取低阶比特位,并确保该位不为0,该条件会选取广播和多播报文。
1 | # tcpdump -nnne -vv -i bond_mgmt "ether[0] & 1 != 0" |
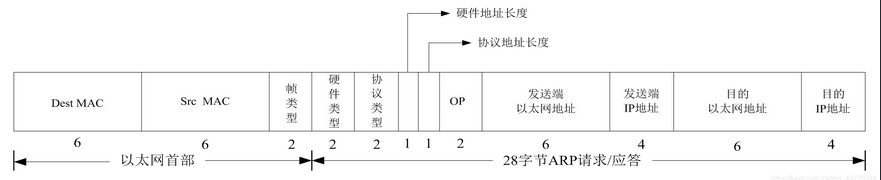
Dest MAC: 目的MAC地址
Src MAC: 源MAC地址
帧类型: 0x0806
硬件类型: 1( 以太网)
协议类型: 0x0800( IP地址)
硬件地址长度: 6
协议地址长度: 4
OP: 1( ARP请求) , 2( ARP应答) , 3( RARP请求) , 4( RARP应答)
- 抓取vlan号:
1 | #tcpdump -nnne -c 3 -i bond_virt vlan 1012 |
- 老版本内核已不支持tag信息流经libcap,所以下面命令无返回结果(使用vlan vlanid抓包):
1 | #tcpdump -nnne -c 3 -i bond_virt 'ether[12:2] = 0x8100' |
文件加密防误操作-chattr
1 | chattr +i 文件名 //+i对文件进行加密,-i解锁 |
常见命令参数
A:即Atime,告诉系统不要修改对这个文件的最后访问时间。
S:即Sync,一旦应用程序对这个文件执行了写操作,使系统立刻把修改的结果写到磁盘。
a:即Append Only,系统只允许在这个文件之后追加数据,不允许任何进程覆盖或截断这个文件。如果目录具有这个属性,系统将只允许在这个目录下建立和修改文件,而不允许删除任何文件。
b:不更新文件或目录的最后存取时间。
c:将文件或目录压缩后存放。
d:当dump程序执行时,该文件或目录不会被dump备份。
D:检查压缩文件中的错误。
i:即Immutable,系统不允许对这个文件进行任何的修改。如果目录具有这个属性,那么任何的进程只能修改目录之下的文件,不允许建立和删除文件。
s:彻底删除文件,不可恢复,因为是从磁盘上删除,然后用0填充文件所在区域。
u:当一个应用程序请求删除这个文件,系统会保留其数据块以便以后能够恢复删除这个文件,用来防止意外删除文件或目录。
t:文件系统支持尾部合并(tail-merging)。
X:可以直接访问压缩文件的内容。
常用的命令展示
chatter: 锁定文件,不能删除,不能更改
+a: 只能给文件添加内容,但是删除不了,
chattr +a /etc/passwd
-d: 不可删除
加锁:chattr +i /etc/passwd 文件不能删除,不能更改,不能移动
查看加锁:lsattr /etc/passwd 文件加了一个参数 i 表示锁定
解锁:chattr -i /home/jiaxu/test.txt - 表示解除
隐藏chattr命令:
1 | which chattr |
恢复隐藏命令:
1 | mv h /usr/bin/chattr |
任务调度
crond
1 | 1.概述 |
1 | 2.基本语法 |

1 | 4.快速入门 |
分 时 天 月 星期几
1 | 特定时间执行任务案例: |
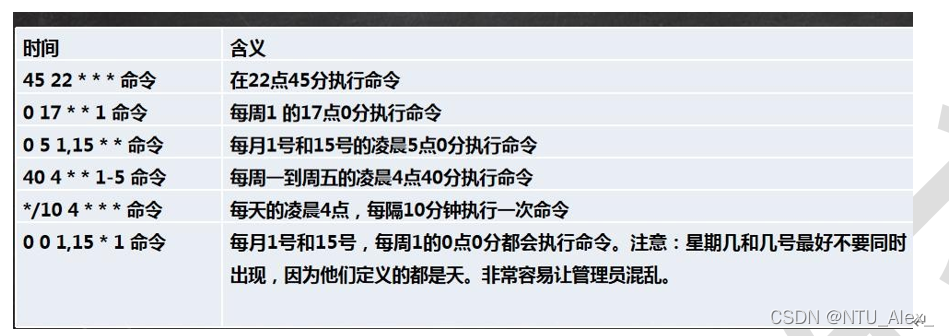
1 | 5.应用实例 |
at定时任务
1 | 1.基本介绍 |
1 | 2. at 命令格式 |
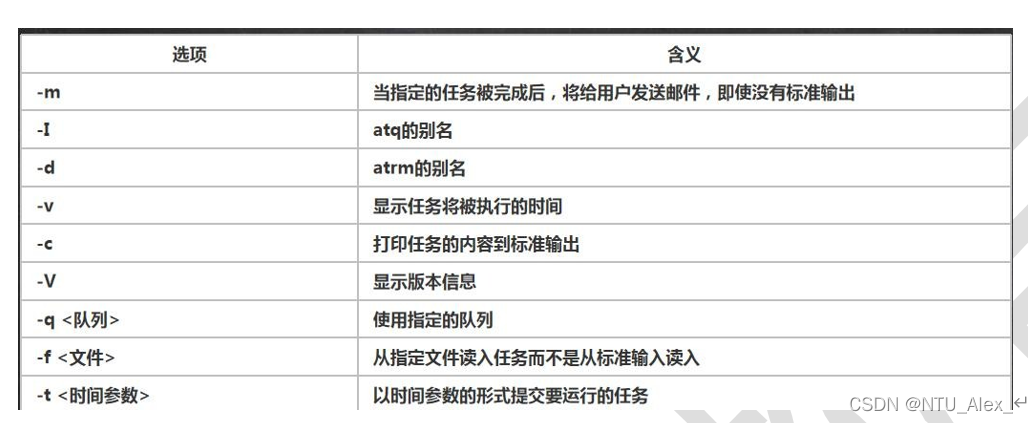
1 | 4. at 指定时间的方法: |
Linux 实操篇-Linux 磁盘分区、挂载
12.1. Linux 分区
12.1.1.原理介绍
1 | (1) Linux 无论有几个分区,分给哪一目录使用,它归根结底就只有一个根目录,一个独立且唯一的文件结构 |
12.1.2.硬盘说明
1 | (1) Linux 硬盘主要分为: |
12.1.3.查看所有设备挂载情况
1 | 命令 :lsblk 或者 lsblk -f |
12.2.挂载的经典案例
12.2.1.说明
1 | 下面我们以增加一块硬盘为例来熟悉一下磁盘的相关指令和深入理解磁盘分区、挂载、卸载的概念。 |
12.2.2.如何增加一块硬盘
1 | 1) 虚拟机添加硬盘 |
12.2.3.虚拟机增加硬盘步骤 1-虚拟机添加硬盘
1 | 在【虚拟机】菜单中选择【设置】 |
12.2.4 虚拟机增加硬盘步骤 2-分区
1 | 对sdb进行分区: |
12.2.5 虚拟机增加硬盘步骤 3-格式化
1 | 格式化磁盘 |
12.2.6.虚拟机增加硬盘步骤 4-挂载
1 | 挂载: 将一个分区与一个目录联系起来, |
12.2.7.虚拟机增加硬盘步骤 5-设置可以自动挂载
1 | 解决 用命令行挂载,重启后会失效 问题 |
12.3.磁盘情况查询
12.3.1.查询系统整体磁盘使用情况
1 | 基本语法: |
12.3.2.查询指定目录的磁盘占用情况
1 | 基本语法: |
12.4.磁盘情况-工作实用指令
1 | 1. 统计/opt 文件夹下文件的个数 |
Linux 实操篇-网络配置
13.1. Linux 网络配置原理图
1 | 1.通过ifconfig指令查看Linux虚拟机的ip地址 |
13.2.查看网络IP和网关
1 | vmware--->编辑--->虚拟网络编辑器 |
13.3. linux 网络环境配置
13.3.1.第一种方法(自动获取ip):
1 | 登陆后,通过界面设置自动获取ip |
13.3.2.第二种方法(手动设置ip)
1 | 手动指定linux的ip地址,使其不变化。 |
13.4.设置Linux系统的主机名和 hosts 映射
13.4.1.设置主机名
1 | Linux系统的主机名相当于其ip地址,起一个主机名是因为ip地址不好记忆,不方便。 |
13.4.2.设置 hosts 映射
1 | 在Windows中,如何通过 主机名 找到(比如 ping) 某个 linux 系统? |
13.5.主机名解析过程分析(hosts、DNS)
13.5.1. hosts
1 | hosts是一个文本文件,用来记录 IP 和 Hostname(主机名)的映射关系 |
13.5.2. DNS
1 | DNS Domain Name System 域名系统 |
13.5.3.应用实例
1 | 用户在浏览器输入了www.baidu.com |
linux中的进程(ps与kill指令)
1. ps命令详解
- [一、常用操作](https://blog.csdn.net/wangyuxiang946/article/details/128262390?ops_request_misc={"request_id"%3A"168612806516800226598520"%2C"scm"%3A"20140713.130102334.."}&request_id=168612806516800226598520&biz_id=0&utm_medium=distribute.pc_search_result.none-task-blog-2~all~top_positive~default-1-128262390-null-null.142^v88^insert_down38v5,239^v2^insert_chatgpt&utm_term=linux ps&spm=1018.2226.3001.4187#_17)
-
- [1、查看所有进程(连带命令行)](https://blog.csdn.net/wangyuxiang946/article/details/128262390?ops_request_misc={"request_id"%3A"168612806516800226598520"%2C"scm"%3A"20140713.130102334.."}&request_id=168612806516800226598520&biz_id=0&utm_medium=distribute.pc_search_result.none-task-blog-2~all~top_positive~default-1-128262390-null-null.142^v88^insert_down38v5,239^v2^insert_chatgpt&utm_term=linux ps&spm=1018.2226.3001.4187#1_26)
- [2、显示所有包含其他使用者的进程](https://blog.csdn.net/wangyuxiang946/article/details/128262390?ops_request_misc={"request_id"%3A"168612806516800226598520"%2C"scm"%3A"20140713.130102334.."}&request_id=168612806516800226598520&biz_id=0&utm_medium=distribute.pc_search_result.none-task-blog-2~all~top_positive~default-1-128262390-null-null.142^v88^insert_down38v5,239^v2^insert_chatgpt&utm_term=linux ps&spm=1018.2226.3001.4187#2_45)
- [3、查看指定进程(grep过滤)](https://blog.csdn.net/wangyuxiang946/article/details/128262390?ops_request_misc={"request_id"%3A"168612806516800226598520"%2C"scm"%3A"20140713.130102334.."}&request_id=168612806516800226598520&biz_id=0&utm_medium=distribute.pc_search_result.none-task-blog-2~all~top_positive~default-1-128262390-null-null.142^v88^insert_down38v5,239^v2^insert_chatgpt&utm_term=linux ps&spm=1018.2226.3001.4187#3grep_66)
- [4、查看CPU/内存占用率最高的进程](https://blog.csdn.net/wangyuxiang946/article/details/128262390?ops_request_misc={"request_id"%3A"168612806516800226598520"%2C"scm"%3A"20140713.130102334.."}&request_id=168612806516800226598520&biz_id=0&utm_medium=distribute.pc_search_result.none-task-blog-2~all~top_positive~default-1-128262390-null-null.142^v88^insert_down38v5,239^v2^insert_chatgpt&utm_term=linux ps&spm=1018.2226.3001.4187#4CPU_78)
- [5、查看指定用户的进程](https://blog.csdn.net/wangyuxiang946/article/details/128262390?ops_request_misc={"request_id"%3A"168612806516800226598520"%2C"scm"%3A"20140713.130102334.."}&request_id=168612806516800226598520&biz_id=0&utm_medium=distribute.pc_search_result.none-task-blog-2~all~top_positive~default-1-128262390-null-null.142^v88^insert_down38v5,239^v2^insert_chatgpt&utm_term=linux ps&spm=1018.2226.3001.4187#5_114)
- [6、分页查看进程](https://blog.csdn.net/wangyuxiang946/article/details/128262390?ops_request_misc={"request_id"%3A"168612806516800226598520"%2C"scm"%3A"20140713.130102334.."}&request_id=168612806516800226598520&biz_id=0&utm_medium=distribute.pc_search_result.none-task-blog-2~all~top_positive~default-1-128262390-null-null.142^v88^insert_down38v5,239^v2^insert_chatgpt&utm_term=linux ps&spm=1018.2226.3001.4187#6_124)
- [二、拓展](https://blog.csdn.net/wangyuxiang946/article/details/128262390?ops_request_misc={"request_id"%3A"168612806516800226598520"%2C"scm"%3A"20140713.130102334.."}&request_id=168612806516800226598520&biz_id=0&utm_medium=distribute.pc_search_result.none-task-blog-2~all~top_positive~default-1-128262390-null-null.142^v88^insert_down38v5,239^v2^insert_chatgpt&utm_term=linux ps&spm=1018.2226.3001.4187#_133)
-
- [1、TTY字段(终端类型)](https://blog.csdn.net/wangyuxiang946/article/details/128262390?ops_request_misc={"request_id"%3A"168612806516800226598520"%2C"scm"%3A"20140713.130102334.."}&request_id=168612806516800226598520&biz_id=0&utm_medium=distribute.pc_search_result.none-task-blog-2~all~top_positive~default-1-128262390-null-null.142^v88^insert_down38v5,239^v2^insert_chatgpt&utm_term=linux ps&spm=1018.2226.3001.4187#1TTY_134)
- [2、STAT字段(进程状态)](https://blog.csdn.net/wangyuxiang946/article/details/128262390?ops_request_misc={"request_id"%3A"168612806516800226598520"%2C"scm"%3A"20140713.130102334.."}&request_id=168612806516800226598520&biz_id=0&utm_medium=distribute.pc_search_result.none-task-blog-2~all~top_positive~default-1-128262390-null-null.142^v88^insert_down38v5,239^v2^insert_chatgpt&utm_term=linux ps&spm=1018.2226.3001.4187#2STAT_140)
- [3、僵尸进程](https://blog.csdn.net/wangyuxiang946/article/details/128262390?ops_request_misc={"request_id"%3A"168612806516800226598520"%2C"scm"%3A"20140713.130102334.."}&request_id=168612806516800226598520&biz_id=0&utm_medium=distribute.pc_search_result.none-task-blog-2~all~top_positive~default-1-128262390-null-null.142^v88^insert_down38v5,239^v2^insert_chatgpt&utm_term=linux ps&spm=1018.2226.3001.4187#3_156)
作用:查看系统进程,比如正在运行的进程有哪些,什么时候开始运行的,哪个用户运行的,占用了多少资源。
参数:
- -e 显示所有进程
- -f 显示所有字段(UID,PPIP,C,STIME字段)
- -a 显示一个终端的所有进程
- -u 显示当前用户进程和内存使用情况
- -x 显示没有控制终端的进程
- –sort 按照列名排序
一、常用操作
ps命令常用的方式有三种:
ps -ef:查看所有进程ps -aux:查看所有进程ps -ef | grep tomcat:查看指定进程
1、查看所有进程(连带命令行)
1 | ps -ef |
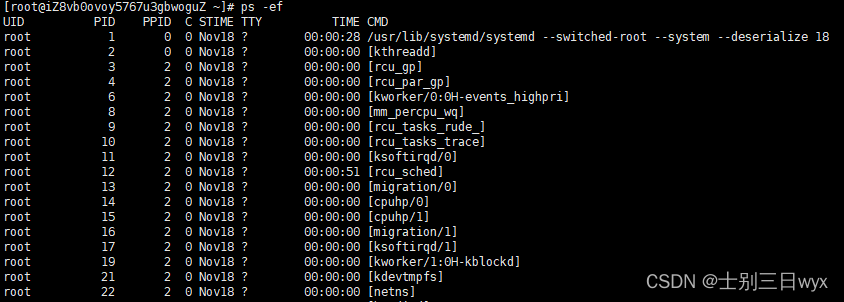
字段解释:
- UID:用户ID,即进程的拥有者
- PID:进程ID
- PPID:父进程ID
- C:进程占用的CPU百分比
- STIME:进程开始启动时间
- TTY:登入者的终端机位置
- TIME:进程使用的CPU(运算)时间
- CMD:调用进程的命令
2、显示所有包含其他使用者的进程
1 | ps -aux |
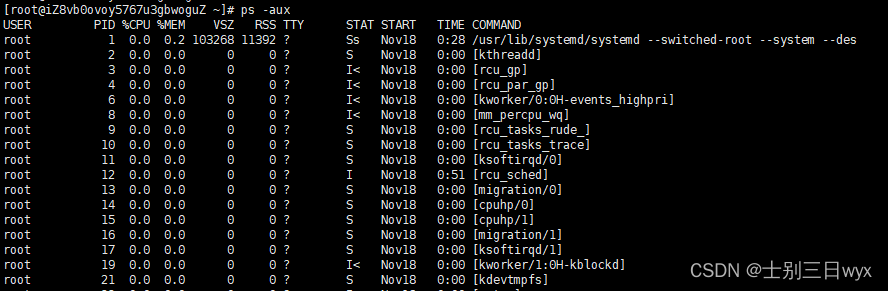
字段解释:
- USER:创建进程的用户
- PID:进程ID
- %CPU:进程占用CPU的百分比
- %MEM:进程占用物理内存的百分比
- VSZ:进程占用虚拟内存的大小(单位KB)
- RSS:进程占用实际物理内存的大小(单位KB)
- TTY:进程在哪个终端运行。
- STAT:进程状态
- START:进程开始启动的时间
- TIME:进程使用的CPU(运算)时间
- COMMAND:调用进程的命令
3、查看指定进程(grep过滤)
ps -ef 通常会配合 grep 来过滤指定的进程,比如
搜索 mysql 的进程:ps -ef | grep mysql

搜索 tomcat 的进程:ps -ef | grep tomcat

4、查看CPU/内存占用率最高的进程
1)查看进程的时候,让进程按照CPU使用率排序,然后展示前10行,就能清晰地看到哪些进程占用的资源比较多。
PS1:head -11 是因为标题也算一行
PS2:+、-号可以调整排序,-pcpu 表示降序,+pcpu 表示升序
1 | ps -aux --sort=-pcpu | head -11 |
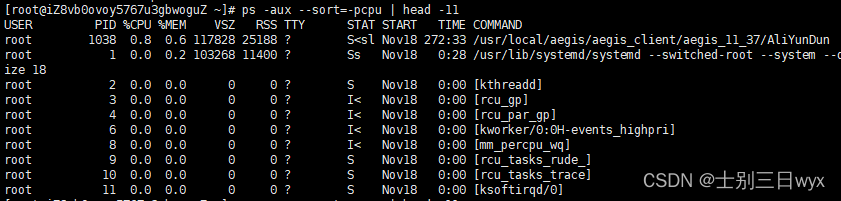
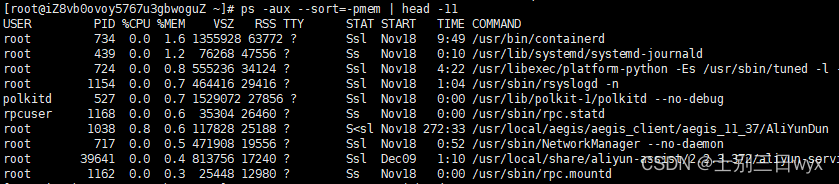
2)同理,把 -pcpu 换成 -pmem,就能查看内存使用最多的10个进程。
1 | ps -aux --sort=-pmem | head -11 |
3)如果不限制行数,也可以使用 sort 按照指定的列排序
降序:
1 | ps -aux | sort -nk 4 -r |
升序:
1 | ps -aux | sort -nk 4 |
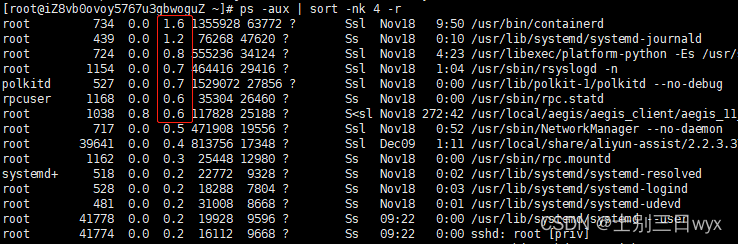
5、查看指定用户的进程
查看某个用户开启了哪些进程,可以使用 -u 参数指定用户名,比如,查看root用户的进程有哪些:
1 | ps -u root -ef |
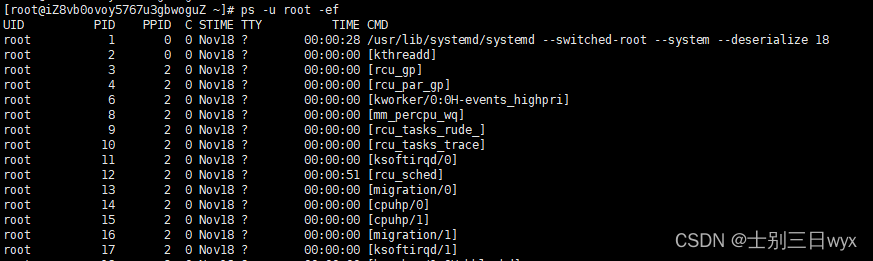
6、分页查看进程
除了 grep 外,还可以配合 more 分页查看进程:ps -ef | more
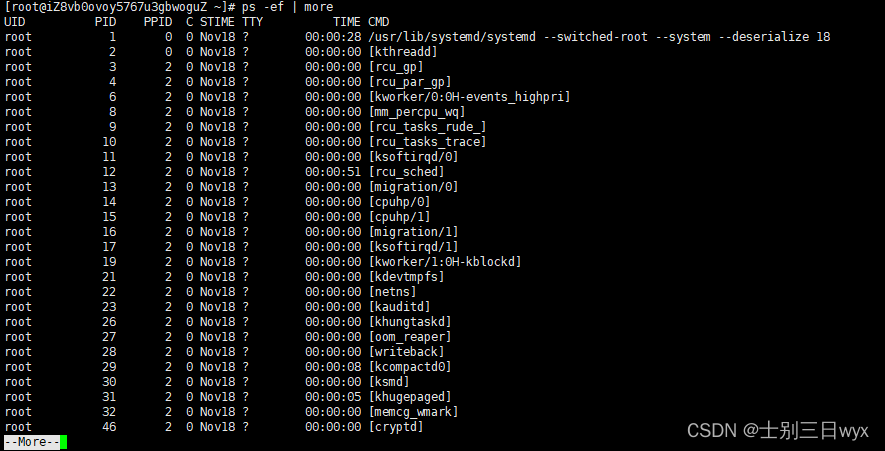
翻页的操作同 more 命令,q键退出,空格键翻页
二、拓展
1、TTY字段(终端类型)
TTY字段表示运行进程的终端是哪个,这里的终端类型有两种:tty和pts。
- tty:表示物理终端,其中
tty1~6是本地字符界面终端,tty7是本地图形终端 - pts:表示虚拟终端,通常指远程连接的终端,范围是
pts/0~255,比如第一个远程连接的终端是pts/0,第二个远程连接的终端是pts/1,依次类推。
2、STAT字段(进程状态)
STAT字段表示进程的状态,常见的状态有以下几种:
- D:睡眠状态(不可被唤醒),常用于I/O情况。
- R:进程正在运行
- S:睡眠状态(可被唤醒)
- T:停止状态
- W:内存交互状态
- Z:僵尸进程(不存在但暂时无法消除)
- <:高优先级
- N:低优先级
- L:被锁入内存
- s:包含子进程
- l:多线程
- +:位于后台
3、僵尸进程
进程由于非正常停止或程序编写错误,导致子进程比父进程先结束,而父进程又没有正常回收子进程,使子进程一直在内存中,导致资源浪费。这种情况就是僵尸进程。
PS:正常情况下应该是父进程先结束,然后子进程由init接管,init 结束子进程并回收对应的资源。
2.kill 和 killall指令:终止进程
1 | 1.介绍: |
3.查看进程树 pstree
1 | 1.基本语法:pstree [选项] |
4.服务(service)管理
14.5.1.介绍
1 | 服务(service) 本质就是进程,但是是运行在后台的, |
14.5.2. service 管理指令
1 | (1) service 服务名 [start | stop | restart | reload | status] |
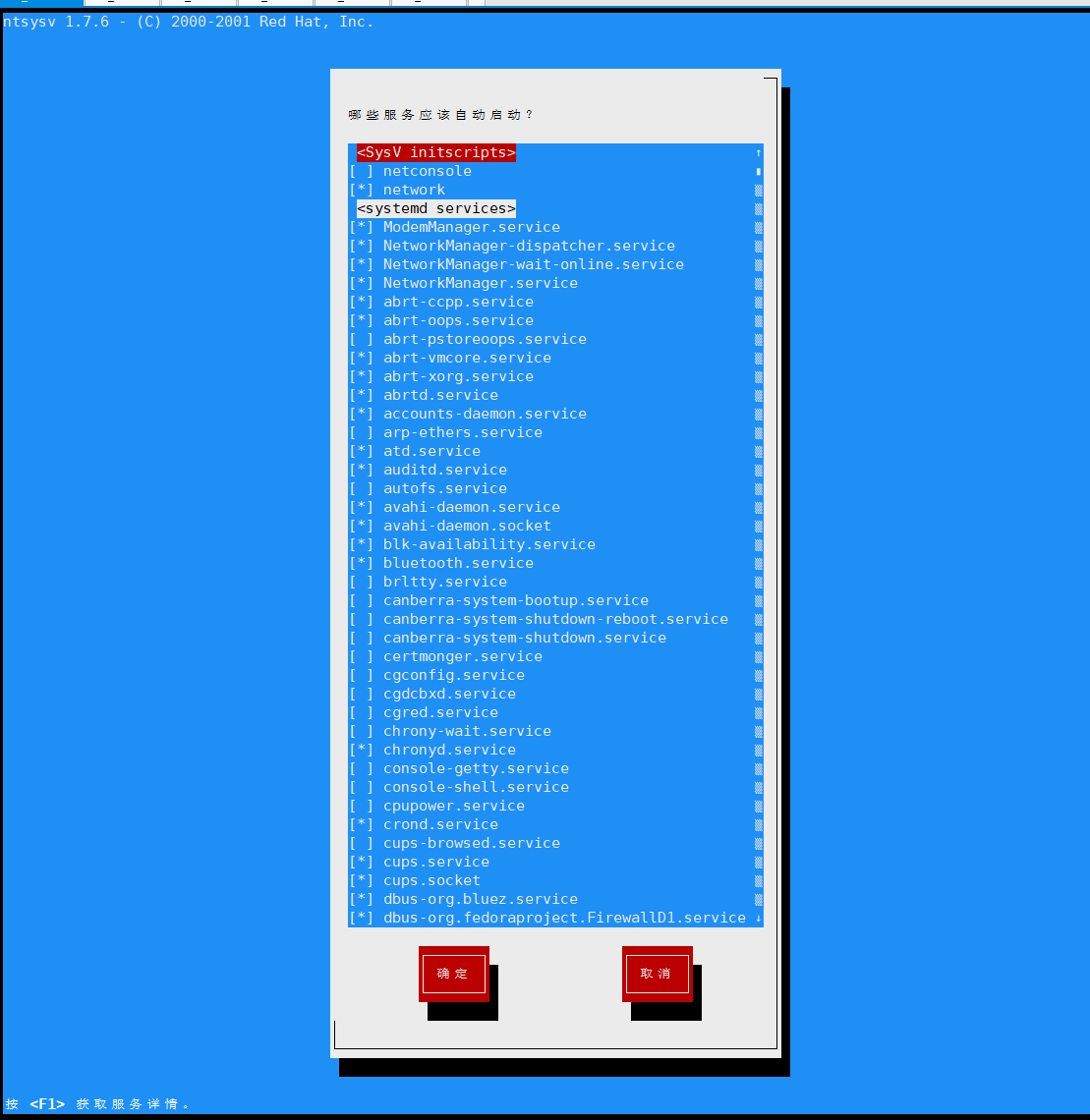
14.5.3.查看服务名方式
1 | 方式 1:直接输入 setup 即可看到所有服务 |
服务的运行级别(runlevel)
1 | Linux 系统有 7 种运行级别(runlevel):常用的是级别 3 和 5 |

CentOS7 后运行级别说明
1 | 在 /etc/initab |
chkconfig 指令
1 | 通过 chkconfig 命令可以给服务在 各个运行级别(上面讲的) 设置开启自启动/关闭自启动 |
systemctl 管理指令
1 | 基本语法:systemctl [start | stop | restart | status] 服务名 |
systemctl 设置服务的自启动状态
1 | systemctl list-unit-files [ | grep 服务名] (查看服务开机启动状态, grep 可以进行过滤) |
firewall 指令:打开或者关闭指定端口
1 | 在真正的生产环境,往往需要将防火墙打开。 |
1 | (1) 打开端口: firewall-cmd --permanent --add-port=端口号/协议 |
5. top指令:动态监控进程
14.6.1.介绍
1 | top 与 ps 命令很相似。 |
14.6.2.基本语法
1 | top [选项] |
1 | 输入top指令后:每一条都是一个进程 |
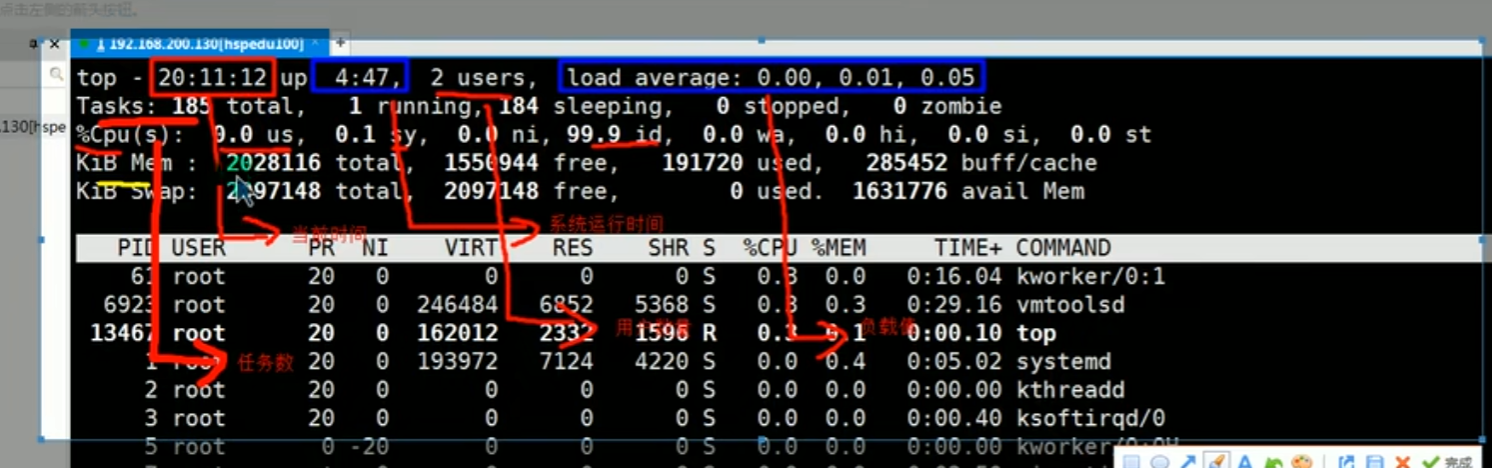
14.6.3.交互操作说明
1 | 输入命令top |

14.6.4.应用实例
1 | 案例 1:监视特定用户, 比如监控 tom 用户 |
6. netstat指令:监控网络状态
14.7.1.查看系统网络情况netstat
1 | 基本语法: |
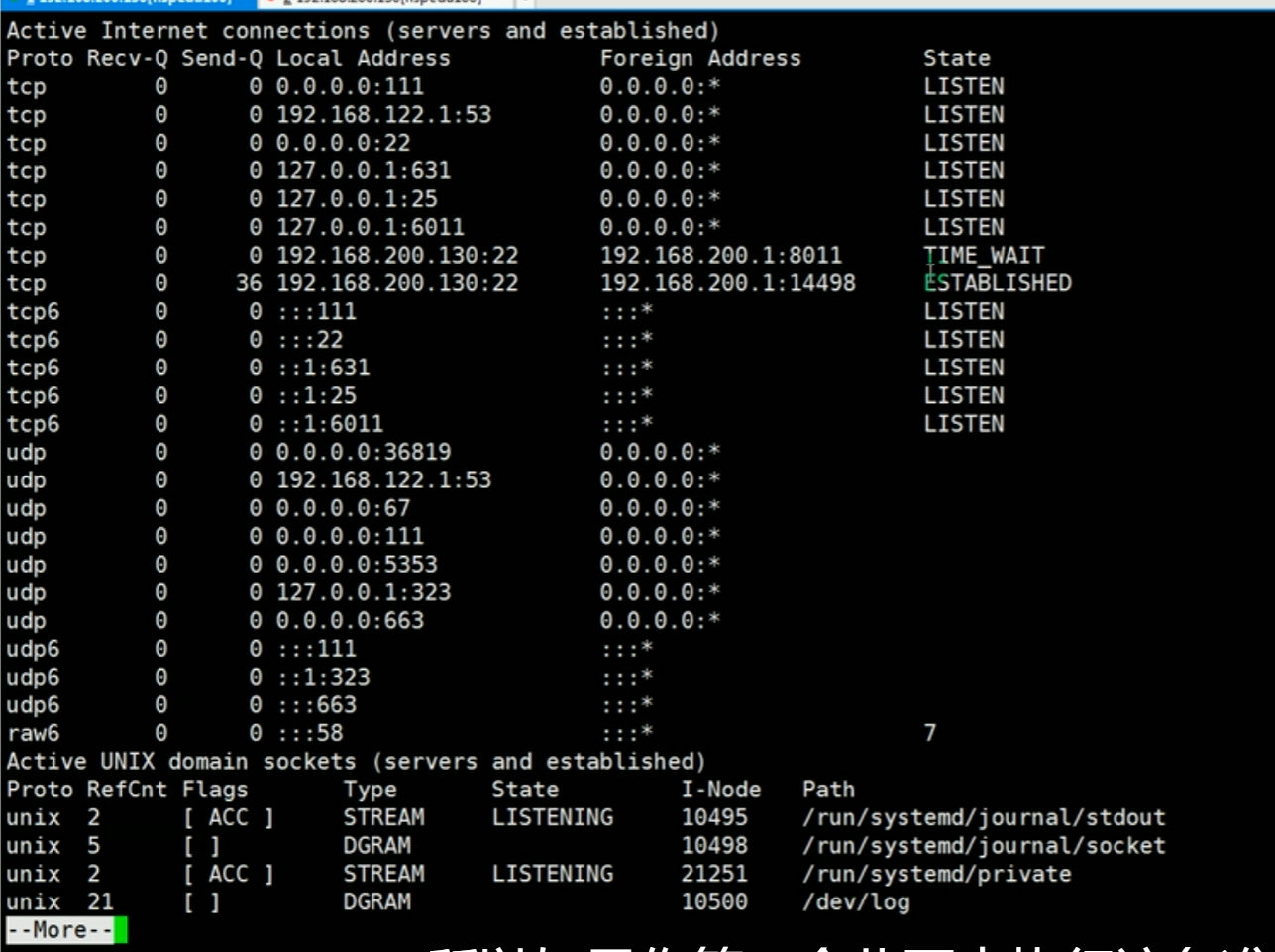
1 | 案例:查看服务名为 sshd 的服务的信息。 |
14.7.2.检测主机连接命令ping
1 | 是一种网络检测工具,它主要是用检测远程主机是否正常,或是两部主机间的网线或网卡故障。 |
Linux 实操篇- RPM 与 YUM
15.1. RPM
15.1.1.介绍
1 | RPM 是 Red-Hat Package Manager(红帽软件包管理器)的缩写 |
15.1.2. rpm 的简单查询指令
1 | 查询已安装的 rpm软件包 列表: |
15.1.3. rpm 的其它查询指令
1 | rpm -qa (查询所安装的所有 rpm 软件包) |
15.1.4.删除 rpm 软件包
1 | 基本语法:rpm -e RPM软件包的名称 //-e erase擦去 |
15.1.5.安装 rpm 软件包
1 | 基本语法:rpm -ivh RPM软件包全路径名称 |
15.2. yum
15.2.1.介绍
1 | Yum(全称为 Yellow dog Updater, Modified)是一个 Shell 前端软件包管理器。 |
15.2.2. yum 的基本指令
1 | 查询 yum 服务器是否有 需要安装的软件: |
15.3.总结
1 | rpm 是从本地安装包下载 |
大数据定制篇-Shell编程
17.1.为什么要学习Shell 编程
1 | (1) Linux 运维工程师在进行服务器集群管理时,需要编写 Shell 程序来进行服务器管理。 |
17.2. Shell 是什么
1 | Shell 是一个命令行解释器,它为用户提供了一个向 Linux 内核发送请求以便运行程序的界面系统级程序,用户可以用 Shell 来启动、挂起、停止甚至是编写一些程序。 |
17.3. Shell 脚本
1 | 1.脚本格式要求: |
17.4. Shell 的变量
17.4.1. Shell 变量介绍
1 | (1) Linux Shell 中的变量分为:系统变量和用户自定义变量。 |
17.4.2. shell 自定义变量
1 | 基本语法: |
 ****
****
17.5.设置环境变量(全局变量)
1 | 可以将变量提升为全局环境变量,供多个shell程序共同使用。 |
17.6.位置参数变量
1 | 1.介绍 |
17.7.预定义变量
1 | 1.基本介绍: |
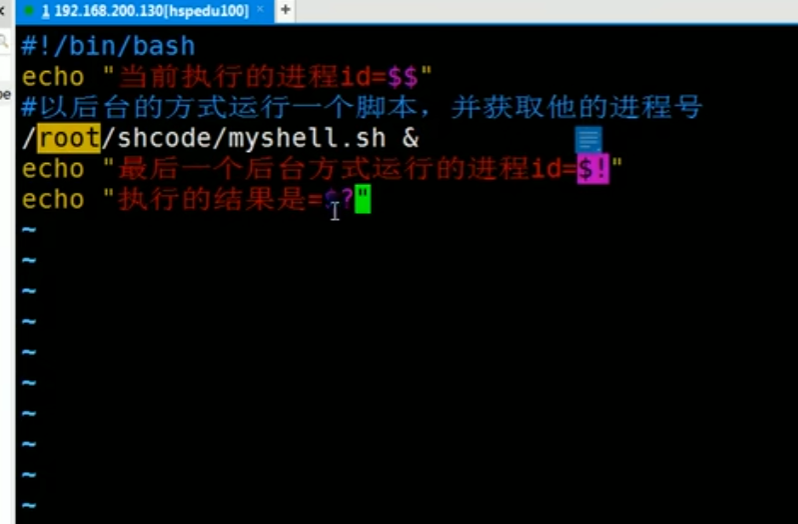
17.8.运算符
1 | 1.基本介绍: |
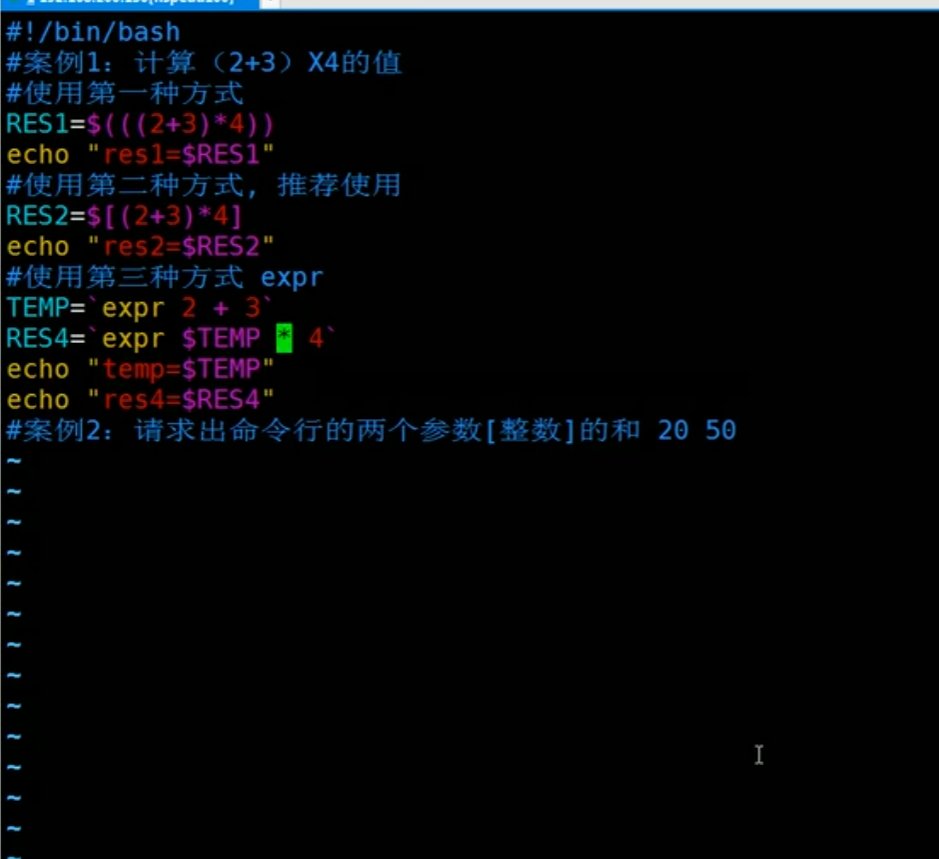
17.9.条件判断
1 | 1.基本语法: |
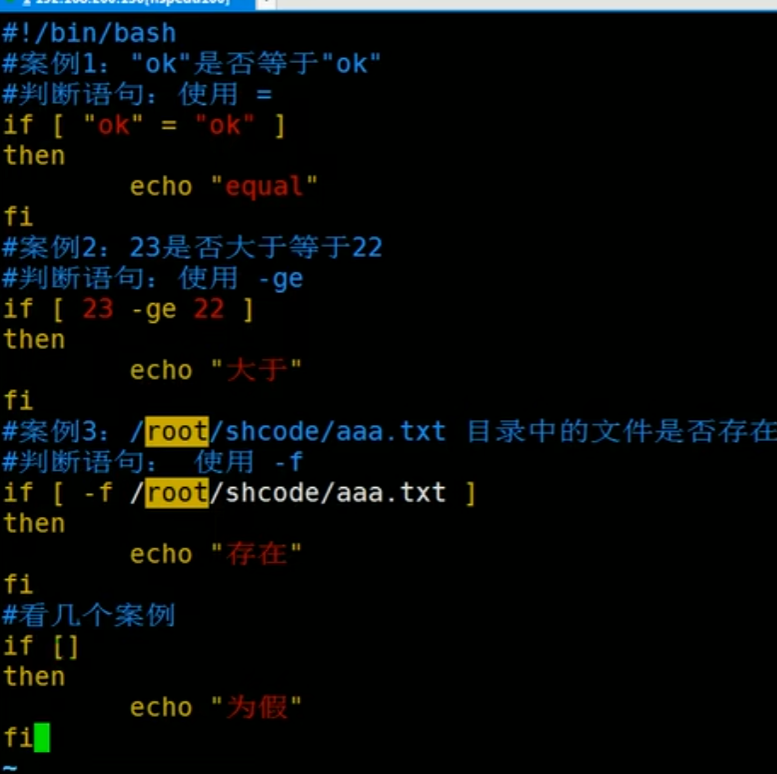
17.10.流程控制
17.10.1. if 语句
1 | 1.基本语法: |
17.10.2. case 语句
1 | 1.基本语法: |
17.10.3. for 循环
1 | 基本语法: |
17.10.4. while 循环
1 | 基本语法: |
17.11. read 读取控制台输入
1 | 1.基本语法: |
函数
17.12.1.函数介绍
1 | shell 编程和其它编程语言一样,有系统函数,也可以自定义函数。系统函数中,我们这里就介绍两个。 |
17.12.2.系统函数
1 | 1.basename 基本语法 |
17.12.3.自定义函数
1 | 基本语法: |
17.13. Shell 编程综合案例
1 | 1.需求分析: |
1 | 2.代码 |
Ubuntu
1.下载
Ubuntu系统下载官方链接:Ubuntu系统下载
VMware下载官方链接: VMware Workstation 16 Player下载
下完VMware直接安装就行了
2 VM安装Ubuntu
双击打开VMware Workstation 16 Player

点击创建新虚拟机
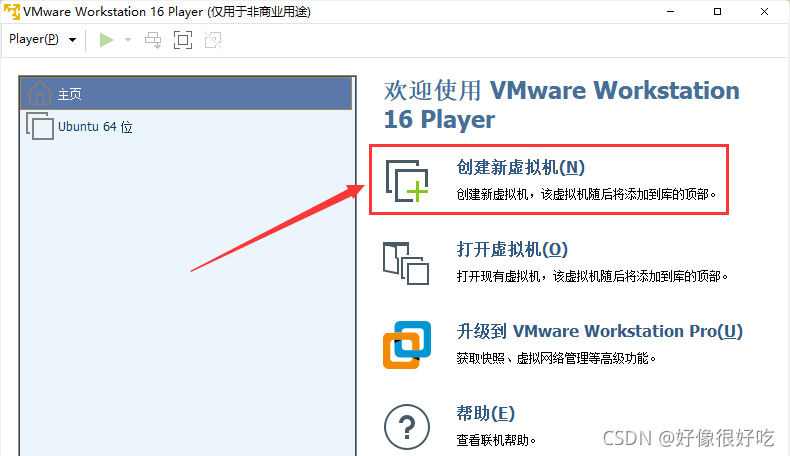
选择稍后安装操作系统,再点下一步
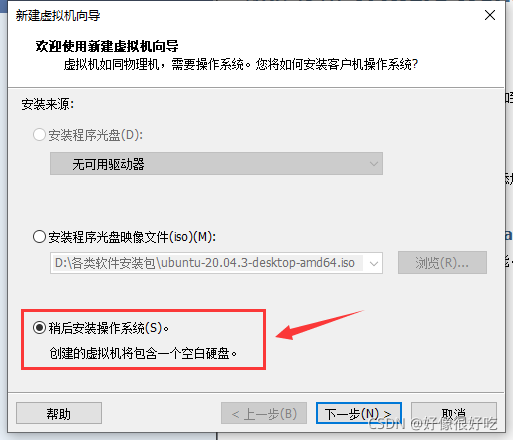
然后注意这两个地方,选择操作系统和版本如下,再点下一步
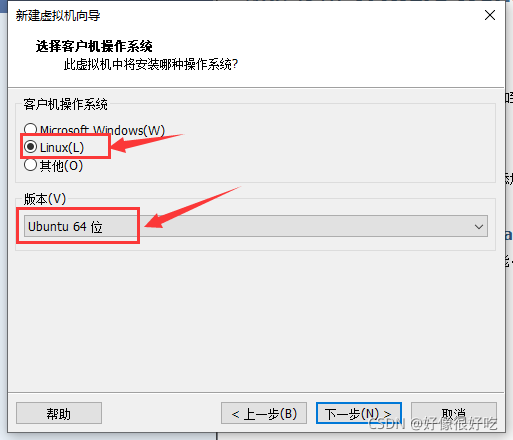
自己定一个系统存储位置,再下一步
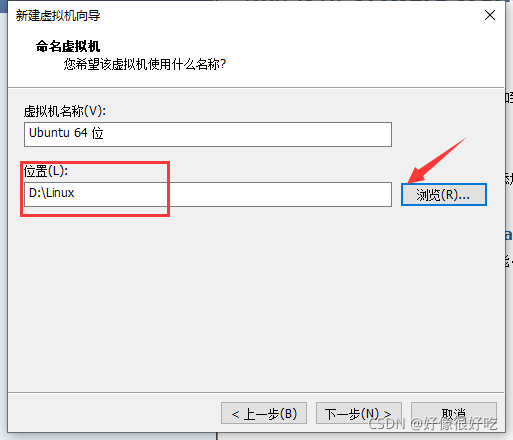
最大磁盘大小按需修改,选择存储为单个文件,再下一步
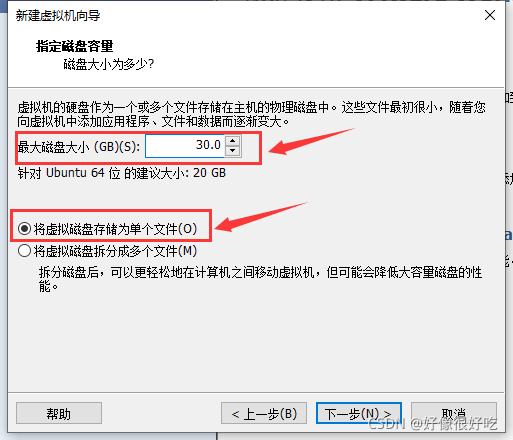
点击自定义硬件
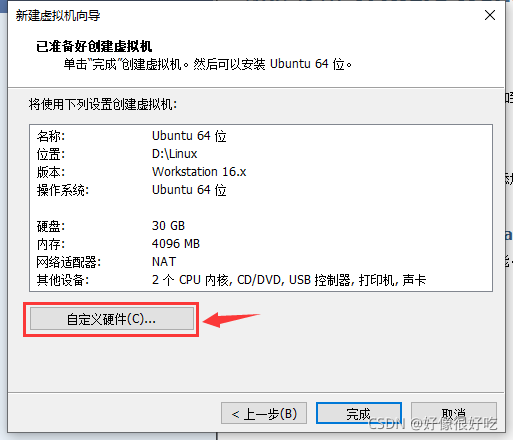
选择使用ISO映像文件,浏览选中刚开始下载的Ubuntu系统,然后点右下角的关闭,再点完成
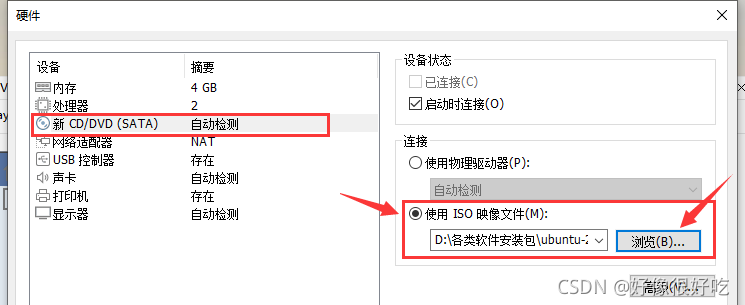
选中,点击播放虚拟机
然后等待…
进入之后,下拉选中 中文简体,再点Ubuntu安装
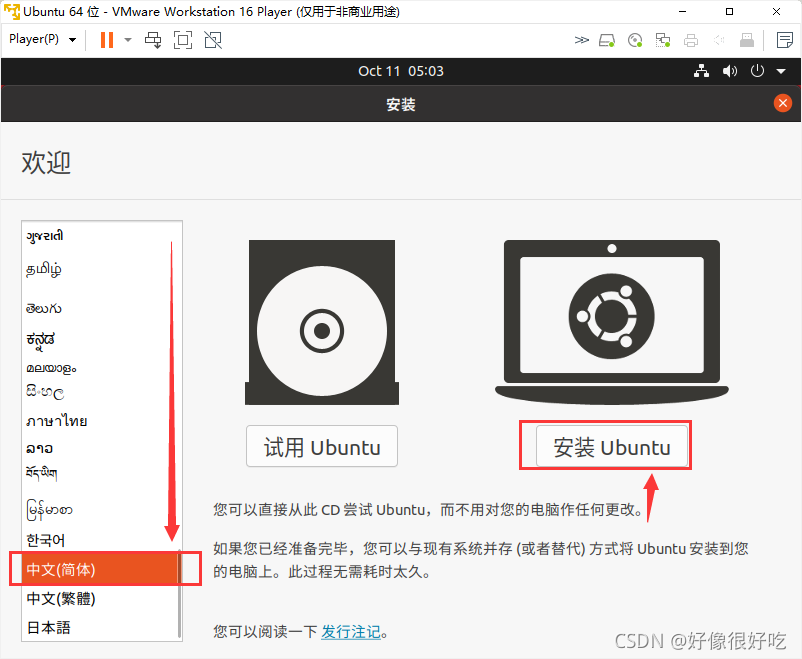
再双击chinese。这里因为Ubuntu系统显示器大小不对,下面的界面显示不出来,我们在下一步先来修改它的显示器大小
到这里后,本来右下箭头所指地方有 继续 按钮,但是显示不出来,我们先关掉安装界面,退出安装
等待…然后进入如下页面,点击右上角倒三角形,再点击设置
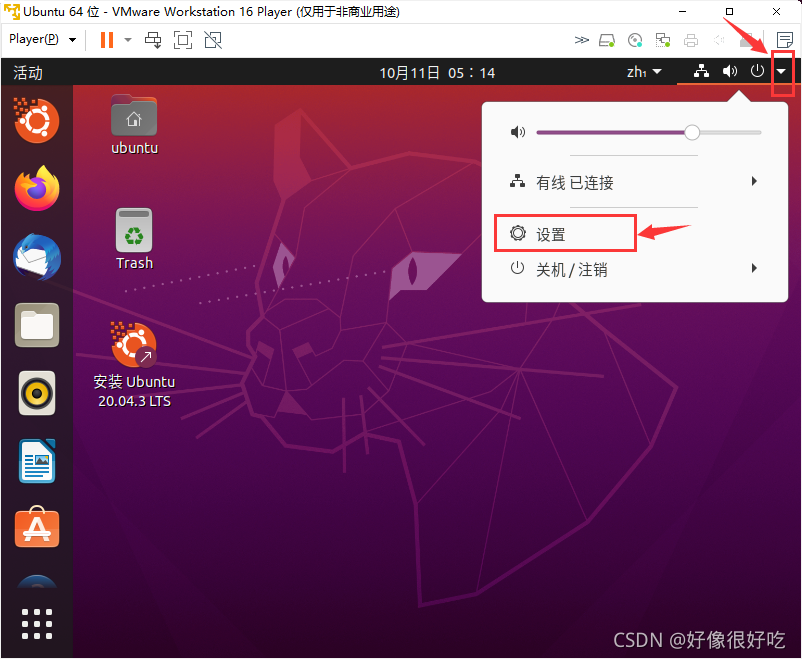
下拉找到显示器,点击分辨率
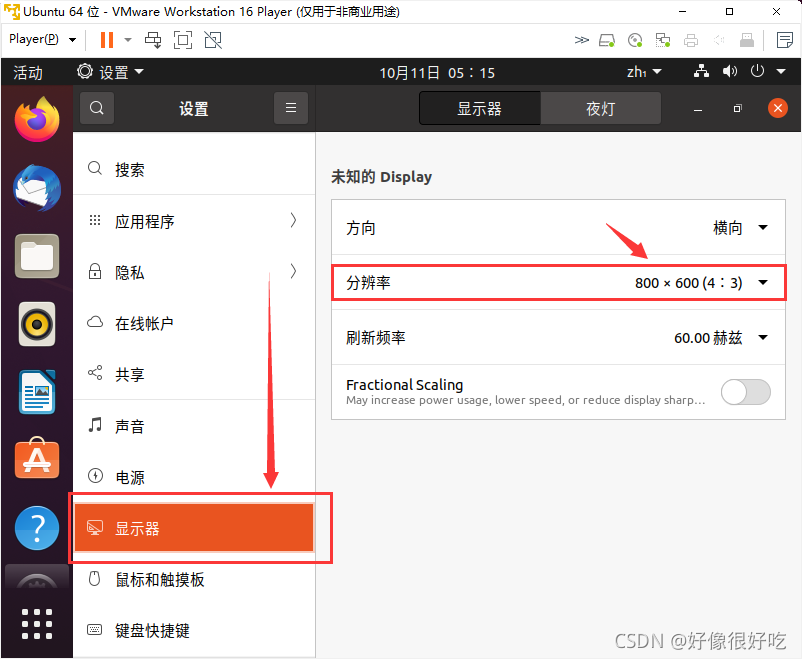
任意改为另一个,例如1024x768,再点击应用
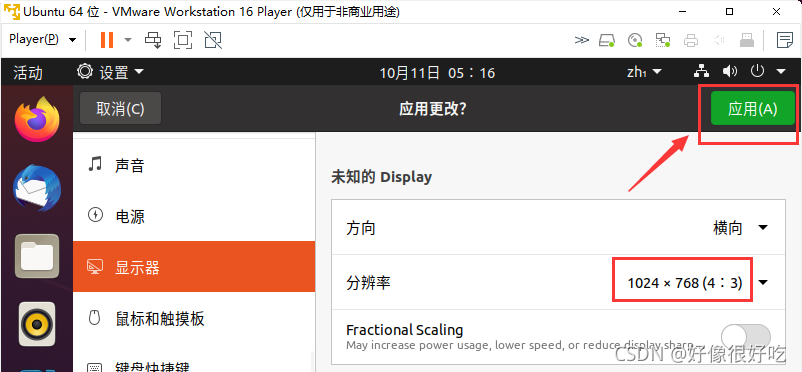
选择保留更改
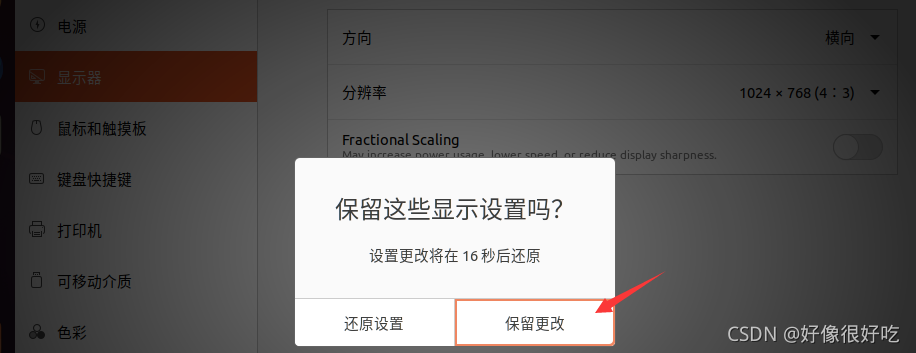
然后点击左上角图标,重新进入系统安装
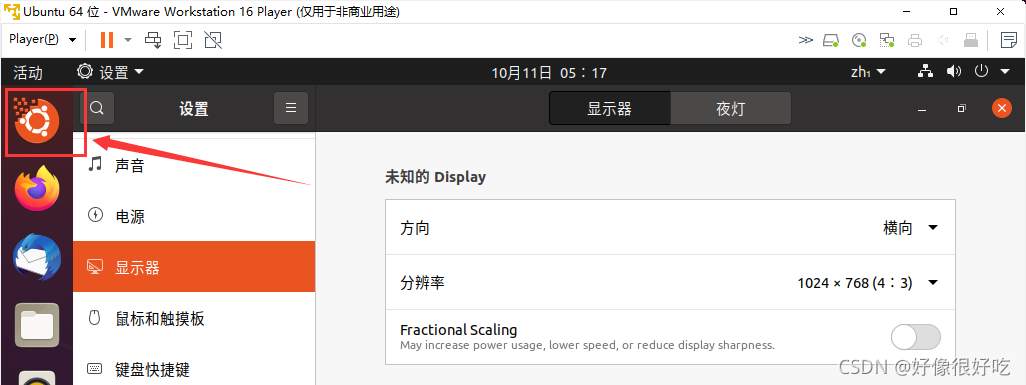
可以看到这时能显示继续的按钮,点击继续
点击现在安装
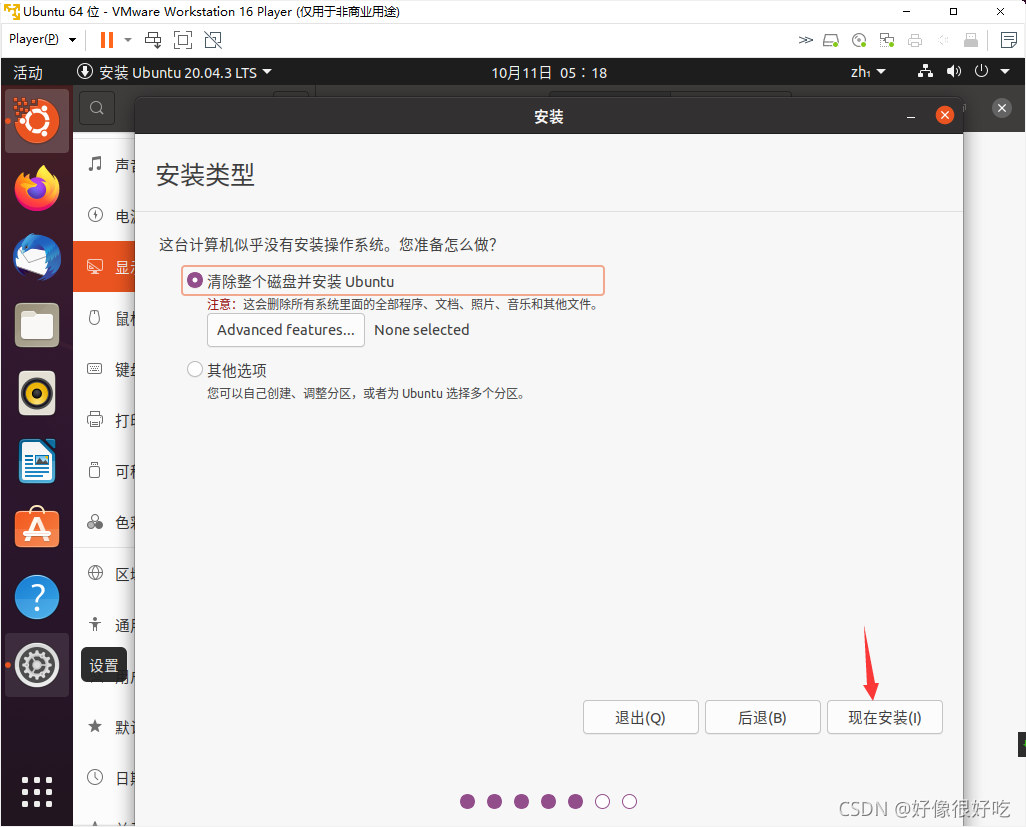
再点击继续
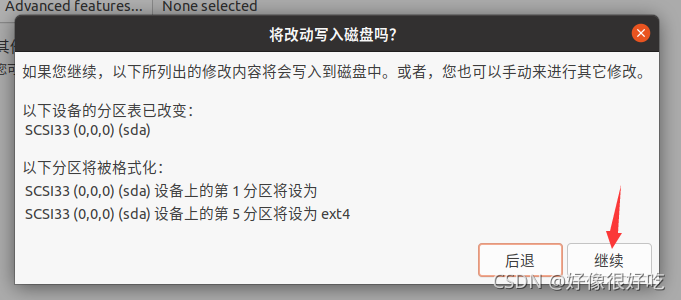
选择地区
点中国所在范围
自行填写以下信息
然后便进入安装等待界面
下载文件时间较长,可点击展开选择skip,然后再等待一段时间…
安装完成,提示重启,点击重启
然后根据提示,进入系统,显示如下界面,即安装完成。
3 更改Ubuntu软件源
配置系统的软件源,提高下载速度
先点左下角矩形网格,找到并打开 软件与更新
按图示修改
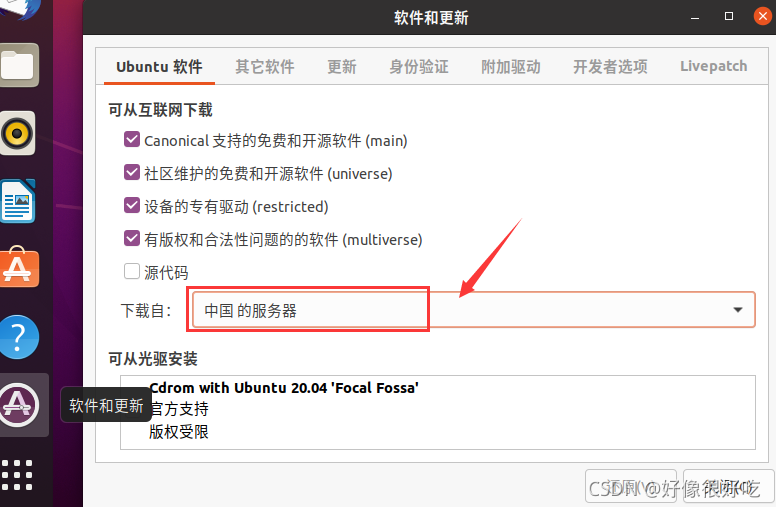
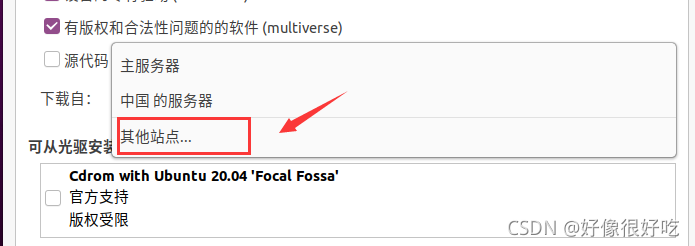
点击选择一个服务器,如第一个,再点选择服务器
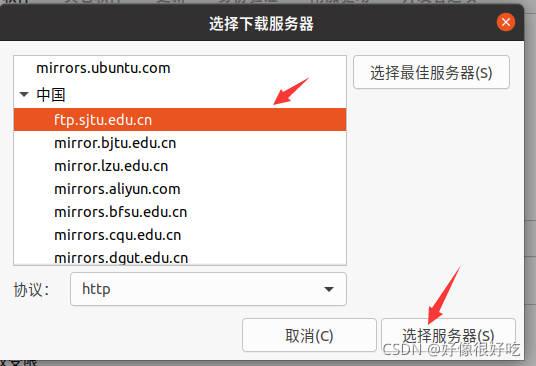
再点关闭
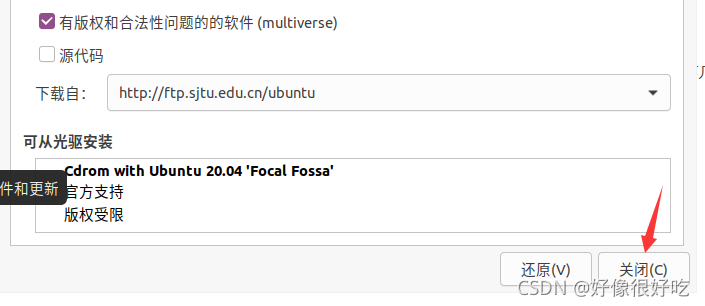
点击重新载入,并等待
其中需输入密码,即之前自行设置的密码,此后有软件更新点击更新即可
到这里软件源更改完成。
4 Windows与Ubuntu跨系统复制粘贴
打开终端,手动输入以下命令,再重启ubuntu系统就可以了
即通过安装VMtools实现了Windows与Ubuntu跨系统复制粘贴,也实现了Ubuntu窗口自适应
1 | sudo apt-get autoremove open-vm-tools |
所有命令
| 命令 | 说明 |
|---|---|
| apt-get update | 更新源 |
| apt-get upgrade | 更新所有已安装的包 |
| apt-get install |
安装软件包 |
| apt-get install –reinstall |
重新安装软件包 |
| apt-get install -f |
修复安装(破损的依赖关系)软件 |
| apt-get remove |
删除软件包 |
| apt-get purge |
删除软件包 |
| apt-get clean | 清除缓存(/var/cache/apt/archives/{,partial}下) 中所有已下载的包 |
| apt-cache stats | 显示系统软件包的统计信息 |
| apt-cache search |
使用关键字pkg搜索软件包 |
| apt-cache show | 显示软件包pkg_name的详细信息 |
| apt-cache depends |
查看pkg所依赖的软件包 |
| apt-cache rdepends |
查看pkg被那些软件包所依赖 |
| apt-get build-dep |
构建pkg源码包的编译依赖 (这条命令很神奇,一步搞定所有编译依赖) |
Ubuntu中的apt命令(相当于centos yum)
apt-get命令本身并不具有管理软件包功能,只是提供了一个软件包管理的命令行平台。在这个平台上使用更丰富的子命令,完成具体的管理任务。
apt-get命令的一般语法格式为:
1 | apt-get subcommands [ -d | -f | -m | -q| --purge | --reinstall | -b | -s | -y | -u | -h | -v ] [pkg] |
apt-cache提供了搜索功能。
说明:下文命令中,尖括号中内容为用户视具体情况而定,如可替换为实际的软件包名 MySQL-server等。
-
更新或升级操作:
1
2
3
4
5
6
7
8
9apt-get update
apt-get upgrade
apt-get dist-upgrade -
安装或重装类操作:
1
2
3
4
5
6
7
8
9apt-get install <pkg> # 安装软件包<pkg>,多个软件包用空格隔开
apt-get install --reinstall <pkg> # 重新安装软件包<pkg>
apt-get install -f <pkg> # 修复安装(破损的依赖关系)软件包<pkg> -
卸载类操作:
1
2
3
4
5apt-get remove <pkg> # 删除软件包<pkg>(不包括配置文件)
apt-get purge <pkg> # 删除软件包<pkg>(包括配置文件) -
下载清除类操作:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25apt-get source <pkg> # 下载pkg包的源代码到当前目录
apt-get download <pkg> # 下载pkg包的二进制包到当前目录
apt-get source -d <pkg> # 下载完源码包后,编译
apt-get build-dep <pkg> # 构建pkg源码包的依赖环境(编译环境?)
apt-get clean # 清除缓存(/var/cache/apt/archives/{,partial}下)中所有已下载的包
apt-get autoclean # 类似于clean,但清除的是缓存中过期的包(即已不能下载或者是无用的包)
apt-get autoremove # 删除因安装软件自动安装的依赖,而现在不需要的依赖包 -
查询类操作:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17apt-cache stats # 显示系统软件包的统计信息
apt-cache search <pkg> # 使用关键字pkg搜索软件包
apt-cache show <pkg_name> # 显示软件包pkg_name的详细信息
apt-cache depends <pkg> # 查看pkg所依赖的软件包
apt-cache rdepends <pkg> # 查看pkg被那些软件包所依赖 -
关于软件安装目录的说明:
一般的deb包(包括新立得或者apt-get下载的)都在**/usr/share**。 自己下载的压缩包或者编译的包,有些可以选择安装目录,一般放在/usr/local/,也有在/opt的。
-
关于apt-get的缓存目录:
默认的缓存目录是**/var/cache/apt/archives/**, 为日后重装系统后安装软件节省下载时间或者将软件包给别人用,可以将该目录下的软件包压缩备份后清理以节省空间。
-
apt 安装
-
sudo apt search package #搜索包 sudo apt show package #获取包的相关信息,如说明、大小、版本等 sudo apt depends package #了解使用依赖 sudo apt rdepends package #查看该包被哪些包依赖 sudo apt-cache pkgnames #执行pkgnames子命令列出当前所有可用的软件包 sudo apt policy package #使用policy命令显示软件包的安装状态和版本信息。 sudo apt install package #安装包 sudo apt install package=version #安装指定版本的包 sudo apt install package --reinstall #重新安装包 sudo apt -f install #修复安装, "-f = --fix-missing" sudo apt remove package #删除包 sudo apt purge package #删除包,包括删除配置文件等 sudo apt autoremove #自动卸载所有未使用的软件包 sudo apt source package #下载该包的源代码 sudo apt update #更新apt软件源信息 sudo apt upgrade #更新已安装的包 sudo apt full-upgrade #在升级软件包时自动处理依赖关系 sudo apt dist-upgrade #升级系统 sudo apt dselect-upgrade #使用dselect升级 sudo apt build-dep package #安装相关的编译环境 sudo apt clean && sudo apt autoclean #清理无用的包 sudo apt clean #清理已下载的软件包,实际上是清楚/var/cache/apt/archives目录中的软件包 sudo apt autoclean #删除已经卸载的软件包备份 sudo apt-get check #检查是否有损坏的依赖## 使用Deb包安装1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
```sql
sudo aptitude update 更新可用的包列表
sudo aptitude upgrade 升级可用的包
sudo aptitude dist-upgrade 将系统升级到新的发行版
sudo aptitude install pkgname 安装包
sudo aptitude remove pkgname 删除包
sudo aptitude purge pkgname 删除包及其配置文件
sudo aptitude search string 搜索包
sudo aptitude show pkgname 显示包的详细信息
sudo aptitude clean 删除下载的包文件
sudo aptitude autoclean 仅删除过期的包文件 -
sudo dpkg -i <package.deb> #安装包 sudo dpkg -r <package.deb> #删除包 sudo dpkg -p <package.deb> #彻底删除包(包括配置文件) dpkg -l #列出当前已安装的包1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
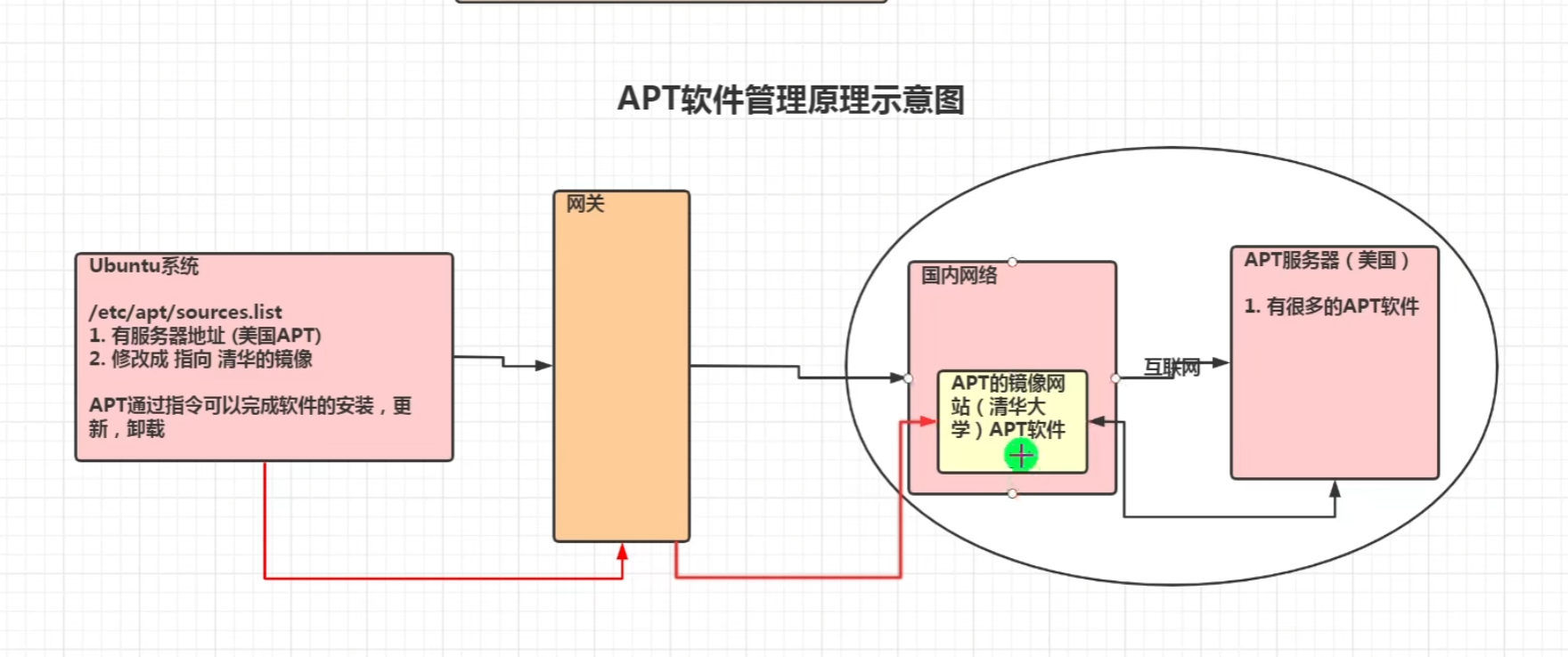
可更换下载源,具体可参照[Ubuntu更换国内源(apt更换源)_ubuntu换源_墨痕诉清风的博客-CSDN博客](https://blog.csdn.net/u012206617/article/details/122321849?ops_request_misc=%7B%22request%5Fid%22%3A%22168640487816800192226268%22%2C%22scm%22%3A%2220140713.130102334..%22%7D&request_id=168640487816800192226268&biz_id=0&utm_medium=distribute.pc_search_result.none-task-blog-2~all~top_click~default-1-122321849-null-null.142^v88^insert_down38v5,239^v2^insert_chatgpt&utm_term=ubuntu更换国内源&spm=1018.2226.3001.4187)
# Ubuntu远程登录
## 1.ssh介绍
SSH为 Secure Shell (安全外壳协议)的缩写,由 IETF 的网络工作小组(Network Working Group)所制定;SSH 为建立在应用层和传输层基础上的安全协议。
SSH是目前较可靠,专为远程登录会话和其他网络服务提供安全性的协议。常用于远程登录。几乎所有 UNIX/LInux 平台都可运行 SSH。
使用 SSH服务,需要安装相应的服务器和客户端。客户端和服务器的关系:如果,A 机器想被 B 机器远程控制,那么,**A机器需要安装 SSH服务器,B 机器需要安装 SSH客户端**。
和 CentOS 不一样,Ubuntu 默认没有安装 SSHD服务(**使用 netstat -anp | more 指令查看: apt install net-tools**),因此,我们不能进行远程登录。
## 2.安装SSH和启用
```bash
sudo apt-get install openssh-server
1
执行上面指令后,在当前这台 Linux 上就安装了 SSH服务端和客户端。
1 | service sshd restart |
执行上面的指令,就启动了 sshd 服务。会监听端口 22
3.远程登录
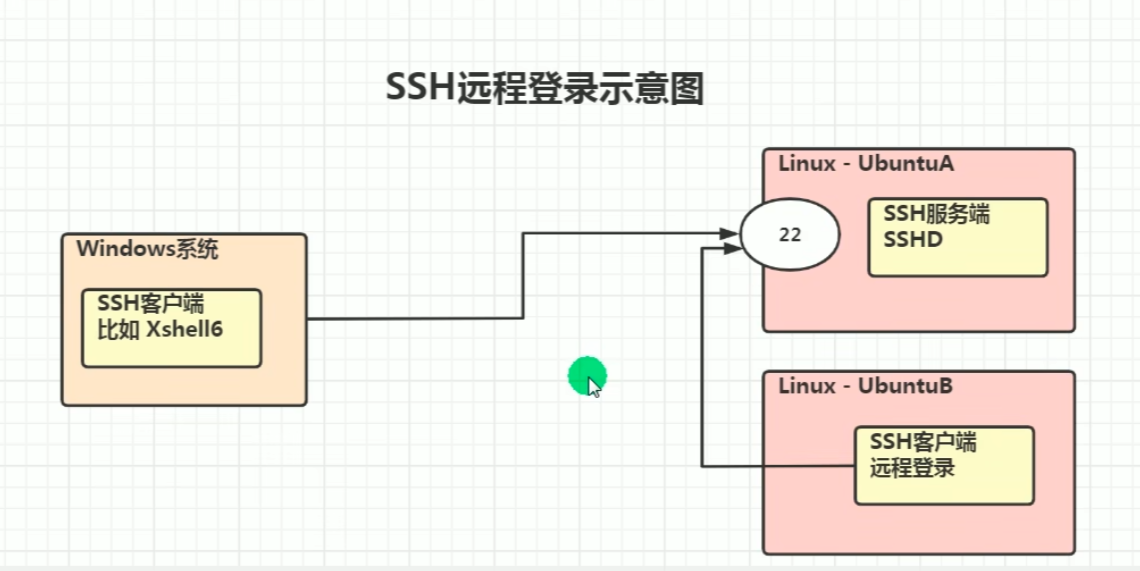
1.使用ssh远程工具(xshell)登录 Ubuntu
查看 ip 地址: ifconfig
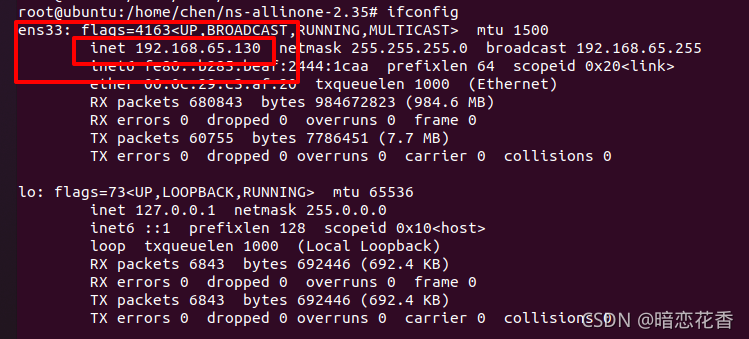
注意:使用普通用户登录,需要的时候再 su 切换成 root 用户
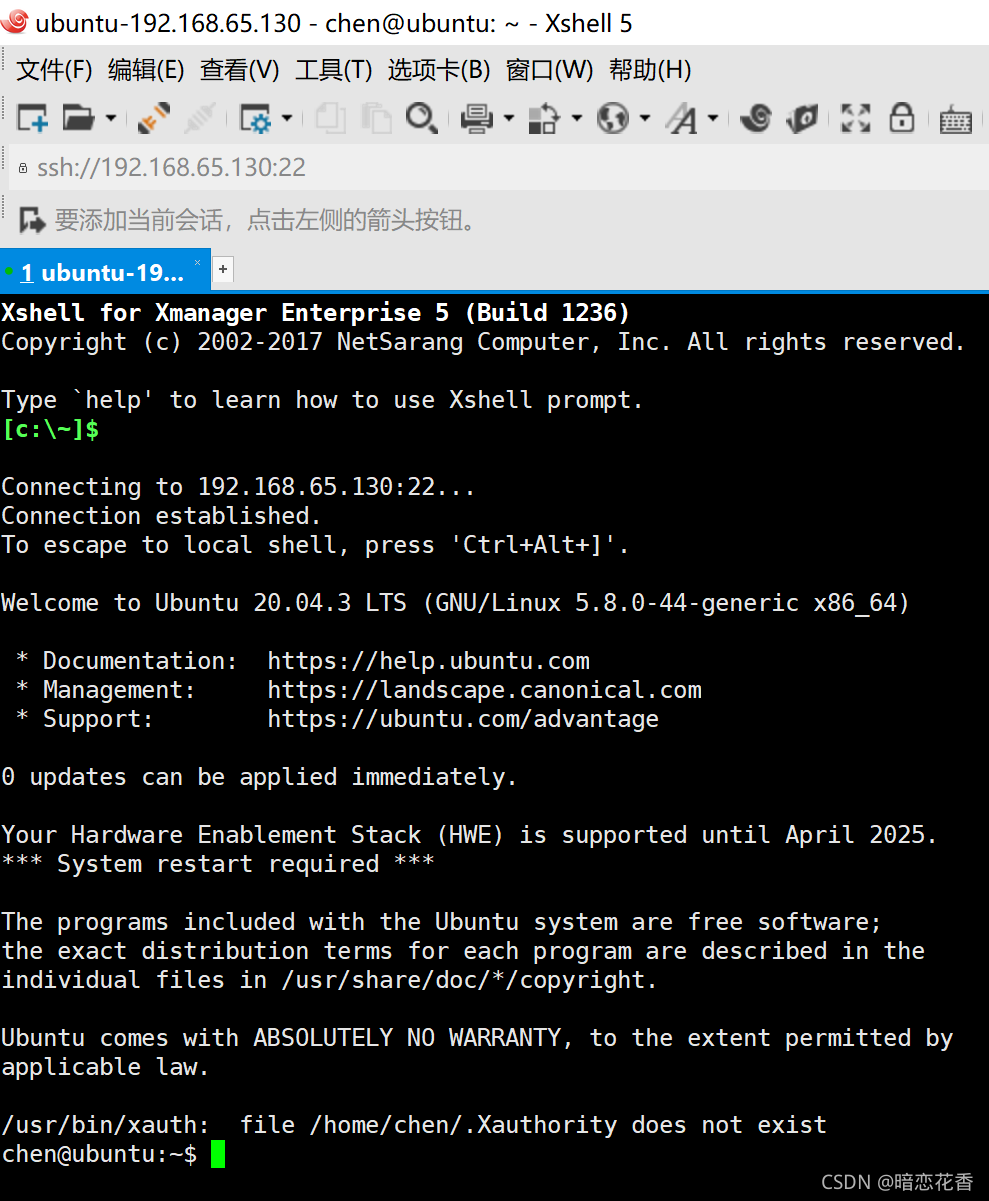
2.用另一台机器远程登录Ubuntu
在Windows端打开CMD 或 Git Bash 命令窗口,或者在另一台centos或Ubuntu机器系统(该机器也要安装ssh服务器)控制终端输入“ssh 用户名@目标主机IP”,即可控制该机器
退出用exit 或 logout
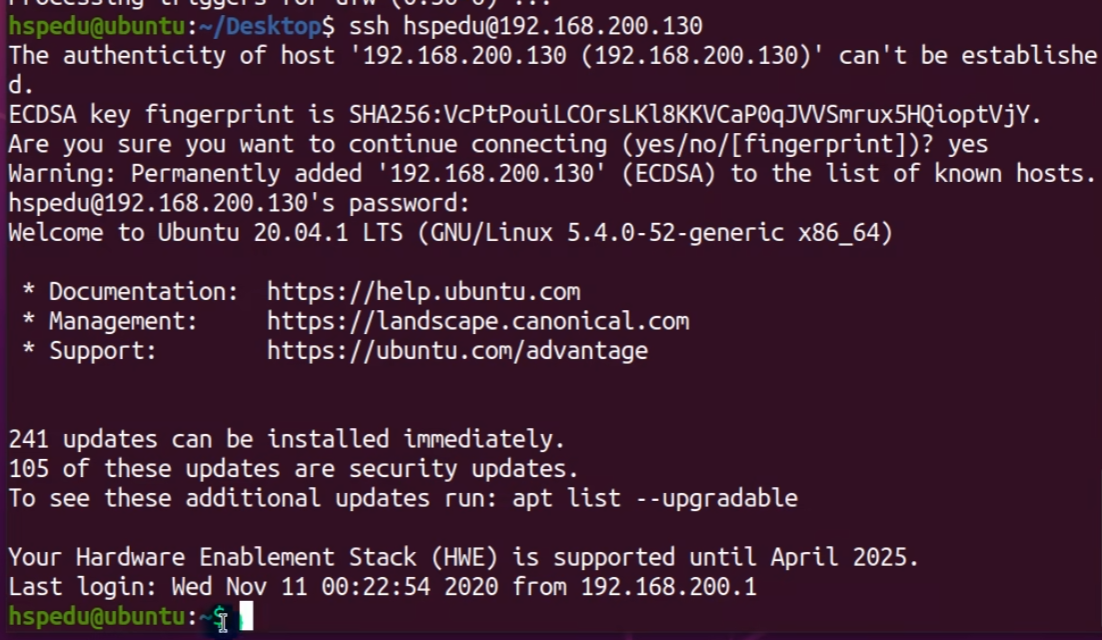
Linux 高级篇-日志管理
21.1.基本介绍
1 | (1)日志文件是重要的系统信息文件,其中记录了许多重要的系统事件,包括用户的登录信息、系统的启动信息、系统的安全信息、邮件相关信息、各种服务相关信息等。 |
21.2.系统常用的日志
1 | 系统日志文件的保存位置:/var/log/ 目录下 |

21.3.日志管理服务 rsyslogd
1 | CentOS7.6 日志服务是 rsyslogd (rocket-fast system for log) |
1 | 1.在进行日志管理时,要保证rsyslogd服务是启动的! |
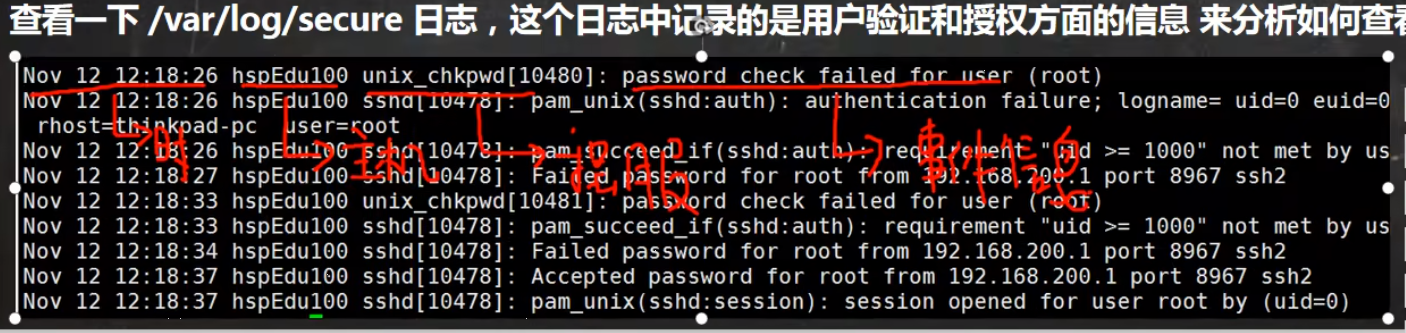
21.4.日志轮替
21.4.1.基本介绍
1 | 日志轮替(logrotate)就是把旧的日志文件移动并改名,同时建立新的空日志文件,当旧日志文件超出保存的范围之后,就会进行删除 |
21.4.2.日志轮替文件命名
1 | (1) centos7 使用 logrotate 进行日志轮替管理 |
21.4.3. logrotate 配置文件
1 | /etc/logrotate.conf 为 logrotate 的全局配置文件(写了日志文件轮替规则) |
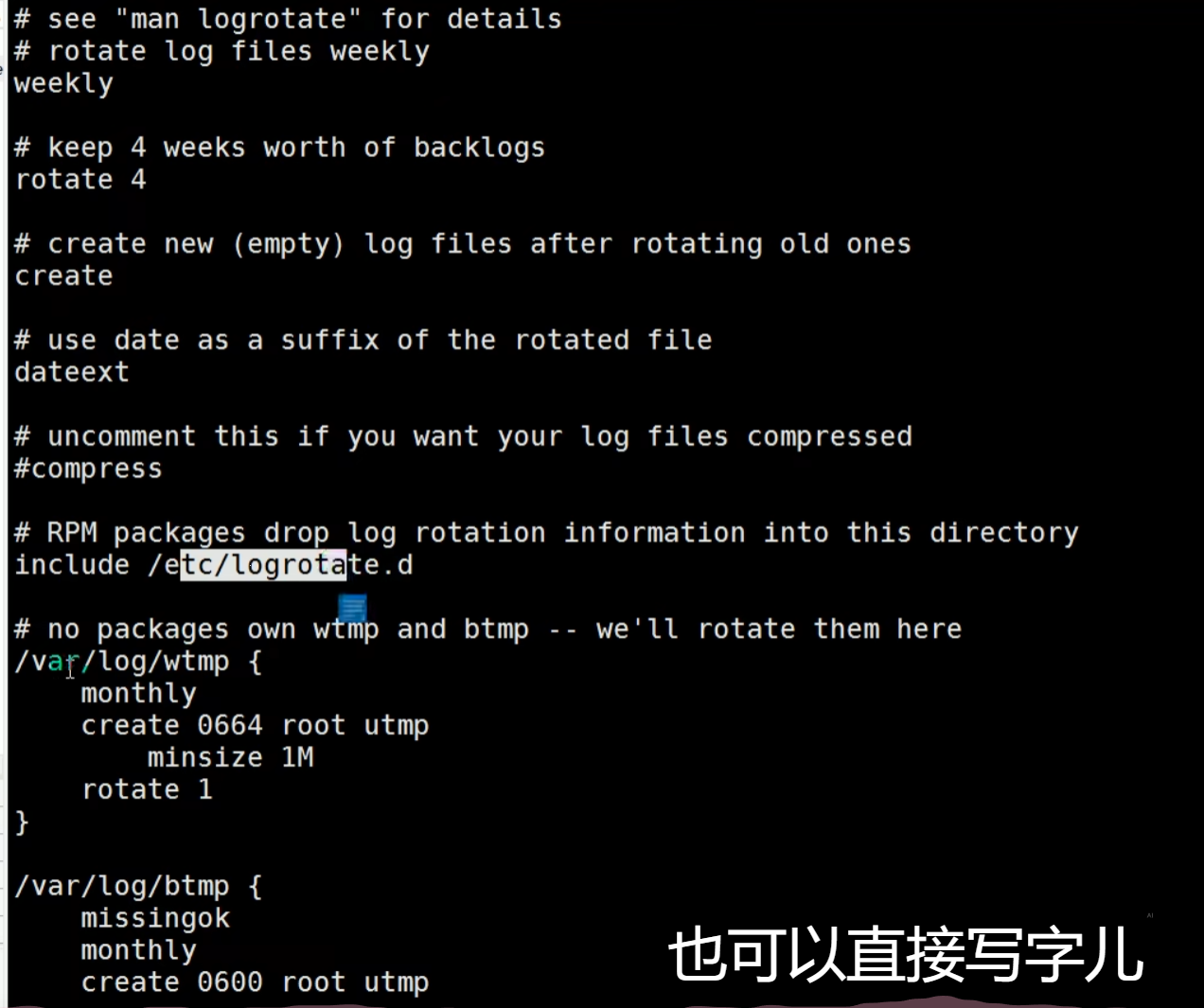
也可以写在/etc/logrotate.d目录下
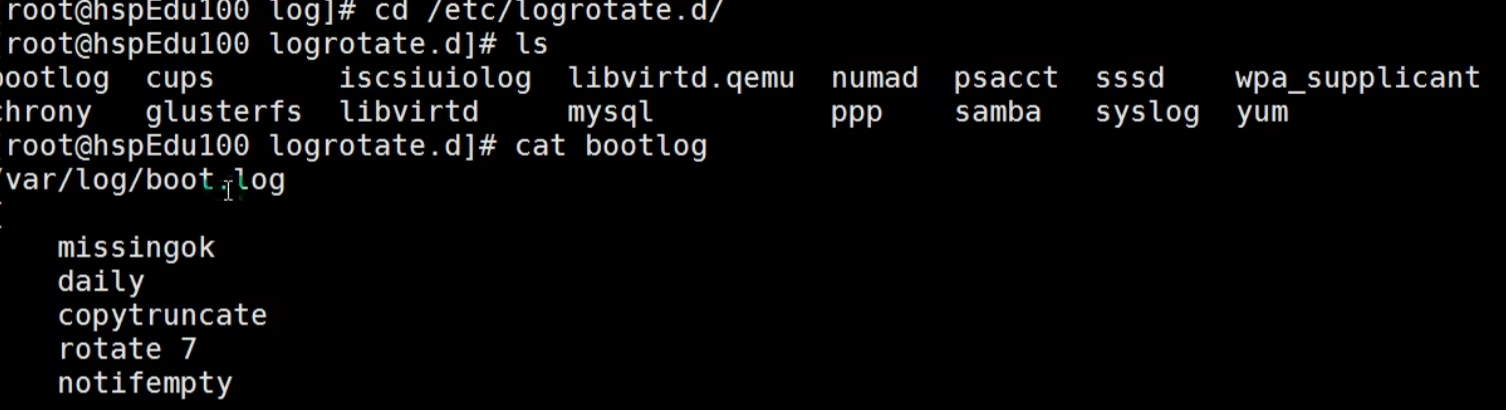
21.4.4.把自己的日志加入日志轮替
1 | 1) 第一种方法: |
21.4.5.应用实例
1 | 案例:在/etc/logrotate.conf 进行配置, 或者直接在 /etc/logrotate.d/ 下创建文件 hsplog |
1 | 在 /etc/logrotate.d/ 下创建文件 hsplog |
21.5.日志轮替机制原理
1 | 日志轮替之所以可以在指定的时间备份日志,是依赖系统定时任务。 |
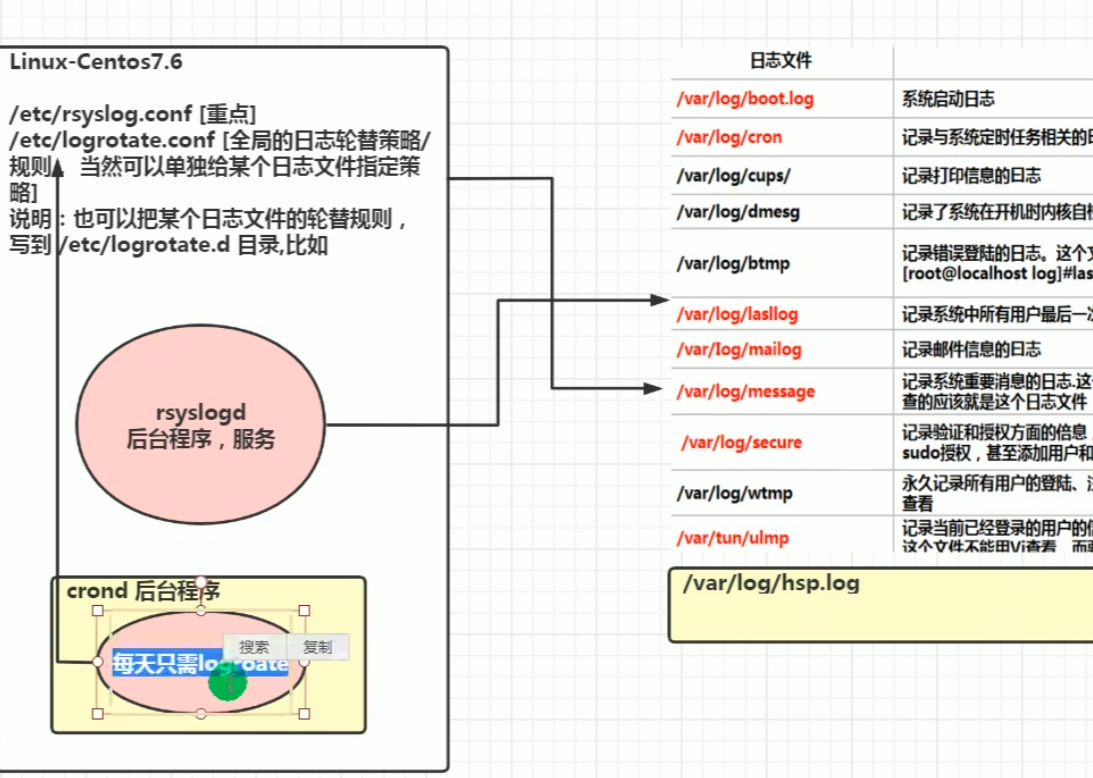
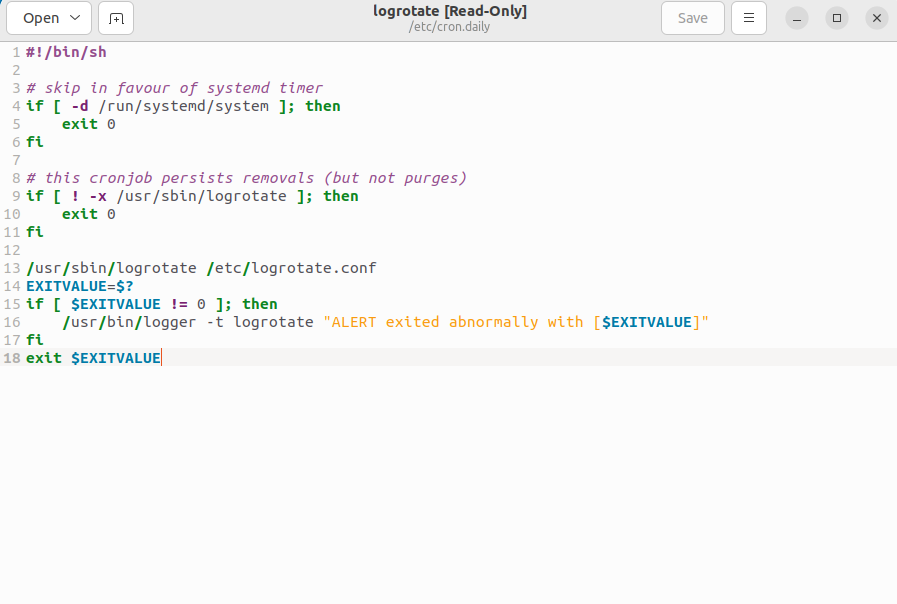
21.6.查看内存日志
1 | 有一些日志是写到内存里的,还没有写到文件里,因为这些日志是实时变化的 |
Linux 高级篇-定制自己的 Linux 系统
22.1.基本介绍
1 | 通过裁剪现有 Linux 系统(CentOS7.6),创建属于自己的 min Linux 小系统 |
22.2.基本原理
1 | 启动流程介绍: |
22.3.制作 min linux 思路分析
1 | 1.在现有的 Linux 系统(centos7.6)上加一块硬盘/dev/sdb |
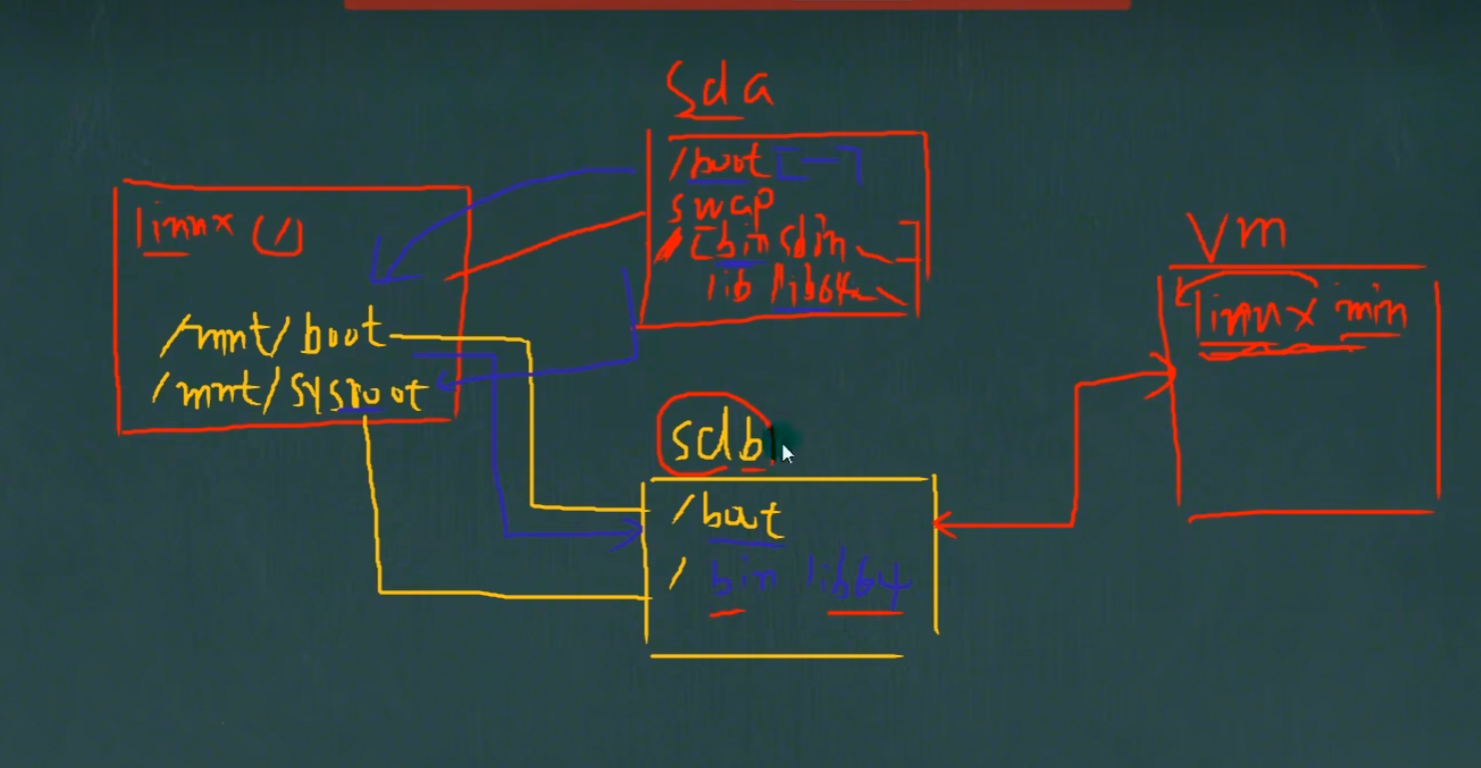
22.4.操作步骤
- 首先,我们在现有的linux添加一块大小为20G的硬盘
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-Edgyugcy-1659016464933)(../../../Pictures/Linux/wps1-16590160625644.jpg)]](https://raw.githubusercontent.com/godwad/2023/main/202356ebed17b2fe4d258645ddbf44069a4a.jpeg)

![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-pIG9BUdl-1659016464933)(../../../Pictures/Linux/wps3-16590160625632.jpg)]](https://raw.githubusercontent.com/godwad/2023/main/2023155111aad04d45ac9b27466e87b80424.jpeg)
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-mxrDRrX4-1659016464933)(../../../Pictures/Linux/wps4-16590160625643.jpg)]](https://raw.githubusercontent.com/godwad/2023/main/2023d74629366f614576adabb155794b773e.jpeg)
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-LmvNxczU-1659016464934)(../../../Pictures/Linux/wps5-16590160625645.jpg)]](https://raw.githubusercontent.com/godwad/2023/main/202315653f9873064a6ca947e4e4aef1f6d5.jpeg)
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-37wWXZmh-1659016464934)(../../../Pictures/Linux/wps6.jpg)]](https://raw.githubusercontent.com/godwad/2023/main/2023db51f769776e4bba9e132e5c085e3324.jpeg)
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-RAfeKdgK-1659016464934)(../../../Pictures/Linux/wps7.jpg)]](https://raw.githubusercontent.com/godwad/2023/main/20233522bc2049cf43f189ad36b95f18aa22.jpeg)
点击完成,就OK了, 可以使用 lsblk 查看,需要重启
- 添加完成后,点击确定,然后启动现有的linux(centos7.6)。 通过fdisk来给我们的/dev/sdb进行分区
1 | 1 [root@localhost ~]# fdisk /dev/sdb |
- 接下来,我们对/dev/sdb的分区进行格式化
[root@localhost ~]# mkfs.ext4 /dev/sdb1
[root@localhost ~]# mkfs.ext4 /dev/sdb2
- 创建目录,并挂载新的磁盘
#mkdir -p /mnt/boot /mnt/sysroot
#mount /dev/sdb1 /mnt/boot
#mount /dev/sdb2 /mnt/sysroot/
- 安装grub, 内核文件拷贝至目标磁盘
#grub2-install --root-directory=/mnt /dev/sdb
#我们可以来看一下二进制确认我们是否安装成功
#hexdump -C -n 512 /dev/sdb
#cp -rf /boot/* /mnt/boot/
- 修改 grub2/grub.cfg 文件, 标红的部分 是需要使用 指令来查看的
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-OSRjCOhS-1659016464934)(…/…/…/Pictures/Linux/wps8.jpg)] 在grub.cfg文件中 , 红色部分用 上面 sdb1 的 UUID替换,蓝色部分用 sdb2的UUID来替换, 紫色部分是添加的,表示selinux给关掉,同时设定一下init,告诉内核不要再去找这个程序了,不然开机的时候会出现错误的
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-YiyfO80L-1659016464935)(../../../Pictures/Linux/QQ%E5%9B%BE%E7%89%8720220728215211.png)]](https://raw.githubusercontent.com/godwad/2023/main/20232f254351906d4985962586df7c5cec18.png)
- 创建目标主机根文件系统
#mkdir -pv /mnt/sysroot/{etc/rc.d,usr,var,proc,sys,dev,lib,lib64,bin,sbin,boot,srv,mnt,media,home,root}
- 拷贝需要的bash(也可以拷贝你需要的指令)和库文件给新的系统使用
#cp /lib64/. /mnt/sysroot/lib64/
#cp /bin/bash /mnt/sysroot/bin/
- 现在我们就可以创建一个新的虚拟机,然后将默认分配的硬盘 移除掉,指向我们刚刚创建的磁盘即可.
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-2SixoQJN-1659016464935)(../../../Pictures/Linux/wps9.jpg)]](https://raw.githubusercontent.com/godwad/2023/main/20233f2f88eda90b43b2b07d4f0045f8f8a4.jpeg)
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-2hFhRSA2-1659016464935)(../../../Pictures/Linux/wps10.jpg)]](https://raw.githubusercontent.com/godwad/2023/main/2023908aaf1caa21402a8e2c50f9c46f4170.jpeg)
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-Bd9jIKxF-1659016464935)(../../../Pictures/Linux/wps11.jpg)]](https://raw.githubusercontent.com/godwad/2023/main/202386c7c24cf74f448d89f74b1e317efa5d.jpeg)
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-1paMP4bO-1659016464936)(../../../Pictures/Linux/wps12.jpg)]](https://raw.githubusercontent.com/godwad/2023/main/20236b1caa596fe04067885dfbfdafdbf351.jpeg)
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-0R1ziBTC-1659016464936)(../../../Pictures/Linux/wps13.jpg)]](https://raw.githubusercontent.com/godwad/2023/main/2023f2a7dc63a57242a7836e92a30a57a67c.jpeg)
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-B99lSfuy-1659016464936)(../../../Pictures/Linux/wps14.jpg)]](https://raw.githubusercontent.com/godwad/2023/main/2023ddac0517617c49c1a4b3532a9ec24c34.jpeg)
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-XxXA3Eog-1659016464937)(../../../Pictures/Linux/wps15.jpg)]](https://raw.githubusercontent.com/godwad/2023/main/2023cc62c852136c427d8bb3a86a8374079d.jpeg)
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-VYebY6ka-1659016464937)(../../../Pictures/Linux/wps16.jpg)]](https://raw.githubusercontent.com/godwad/2023/main/202335fc9b702bfd4a4c9080b0e2b23d5858.jpeg)
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-3L320UJR-1659016464937)(../../../Pictures/Linux/wps17.jpg)]](https://raw.githubusercontent.com/godwad/2023/main/2023b74d9960d5d946feb6bbe4290bbb4cb2.jpeg)
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-uTb4l5FP-1659016464937)(../../../Pictures/Linux/wps18.jpg)]](https://raw.githubusercontent.com/godwad/2023/main/2023b7e314e888ba4178b68757c77db8f604.jpeg)
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-g7BNVp37-1659016464938)(../../../Pictures/Linux/wps19.jpg)]](https://raw.githubusercontent.com/godwad/2023/main/202353033b92af524bbb8f41488c9e8bad7b.jpeg)
- 这时,很多指令都不能使用,比如 ls , reboot 等,可以将需要的指令拷贝到对应的目录即可
- 如果要拷贝指令,*重新进入到原来的 linux系统拷贝相应的指令即可*,比较将 /bin/ls 拷贝到 /mnt/sysroot/bin 将/sbin/reboot 拷贝到 /mnt/sysroot/sbin
root@hspedu100 ~]# mount /dev/sdb2 /mnt/sysroot/
[root@hspedu100 ~]# cp /bin/ls /mnt/sysroot/bin/
[root@hspedu100 ~]# cp /bin/systemctl /mnt/sysroot/bin/
[root@hspedu100 ~]# cp /sbin/reboot /mnt/sysroot/sbin/
- 再重新启动新的min linux系统,就可以使用 ls , reboot 指令了
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-6W6868xA-1659016464938)(../../../Pictures/Linux/wps20.jpg)]](https://raw.githubusercontent.com/godwad/2023/main/2023ca57ea4d25a44e14af3e123576d59c81.jpeg)
linux 系统-备份与恢复
24.1.基本介绍
1 | 虚拟机可以做快照。 |
24.2.安装 dump 和 restore
1 | 如果 linux 上没有 dump 和 restore 指令,要先安装 |
24.3.使用 dump 完成备份
1 | 1.基本介绍: |
24.4.使用 restore 完成恢复
1 | 1.基本介绍: |
Linux部分源码解读
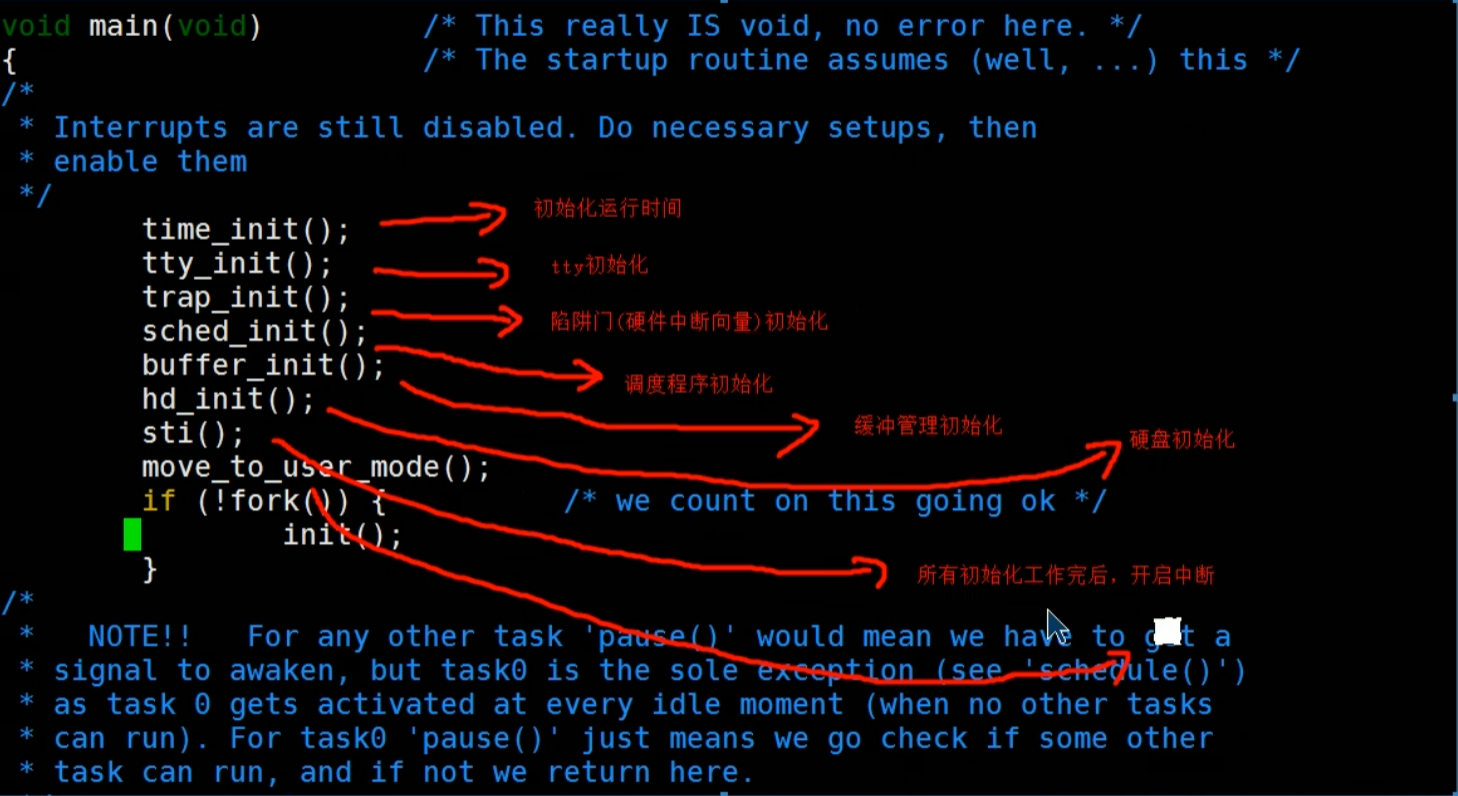
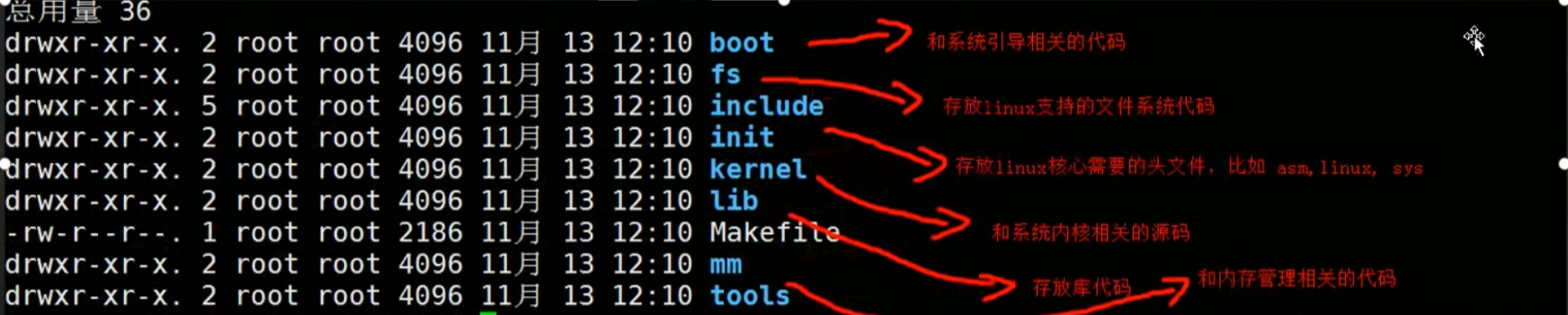
数据备份与恢复
dump备份
一、命令简介
Linux dump命令用于备份文件系统。dump为备份工具程序,可将目录或整个文件系统备份至指定的设备,或备份成一个大文件。dump命令只可以备份ext2/3/4格式的文件系统,centos7默认未安装dump命令,可以使用yum install -y dump安装此命令。
二、使用示例
1、全量备份/boot分区
[root@s135 ~]# dump -0uj -f /root/boot.bak.bz2 /boot/
DUMP: Date of this level 0 dump: Fri Jul 30 16:10:06 2021
DUMP: Dumping /dev/sda1 (/boot) to /root/boot.bak.bz2
DUMP: Label: none
DUMP: Writing 10 Kilobyte records
DUMP: Compressing output at compression level 2 (bzlib)
DUMP: mapping (Pass I) [regular files]
DUMP: mapping (Pass II) [directories]
DUMP: estimated 115437 blocks.
DUMP: Volume 1 started with block 1 at: Fri Jul 30 16:10:06 2021
DUMP: dumping (Pass III) [directories]
DUMP: dumping (Pass IV) [regular files]
DUMP: Closing /root/boot.bak.bz2
DUMP: Volume 1 completed at: Fri Jul 30 16:10:22 2021
DUMP: Volume 1 took 0:00:16
DUMP: Volume 1 transfer rate: 6656 kB/s
DUMP: Volume 1 116040kB uncompressed, 106506kB compressed, 1.090:1
DUMP: 116040 blocks (113.32MB) on 1 volume(s)
DUMP: finished in 16 seconds, throughput 7252 kBytes/sec
DUMP: Date of this level 0 dump: Fri Jul 30 16:10:06 2021
DUMP: Date this dump completed: Fri Jul 30 16:10:22 2021
DUMP: Average transfer rate: 6656 kB/s
DUMP: Wrote 116040kB uncompressed, 106506kB compressed, 1.090:1
DUMP: DUMP IS DONE
[root@s135 ~]# ll -h /root/
总用量 105M
-rw-------. 1 root root 1.8K 7月 30 16:03 anaconda-ks.cfg
-rw-r–r–. 1 root root 105M 7月 30 16:10 boot.bak.bz2
[root@s135 ~]# df -hT
文件系统 类型 容量 已用 可用 已用% 挂载点
/dev/mapper/centos-root ext4 9.8G 1.2G 8.1G 13% /
devtmpfs devtmpfs 908M 0 908M 0% /dev
tmpfs tmpfs 919M 0 919M 0% /dev/shm
tmpfs tmpfs 919M 8.5M 911M 1% /run
tmpfs tmpfs 919M 0 919M 0% /sys/fs/cgroup
/dev/sda1 ext4 976M 115M 795M 13% /boot
/dev/mapper/centos-home ext4 17G 45M 16G 1% /home
tmpfs tmpfs 184M 0 184M 0% /run/user/0
2、增量备份/boot分区
在/boot分区创建一个测试文件hi.txt
[root@s135 ~]# cd /boot/
[root@s135 boot]# touch hi.txt
[root@s135 boot]# echo “this is a test” > hi.txt
然后增量备份/boot分区
[root@s135 ~]# dump -1uj -f /root/boot.bak1.bz2 /boot/
DUMP: Date of this level 1 dump: Fri Jul 30 16:17:15 2021
DUMP: Date of last level 0 dump: Fri Jul 30 16:16:41 2021
DUMP: Dumping /dev/sda1 (/boot) to /root/boot.bak1.bz2
DUMP: Label: none
DUMP: Writing 10 Kilobyte records
DUMP: Compressing output at compression level 2 (bzlib)
DUMP: mapping (Pass I) [regular files]
DUMP: mapping (Pass II) [directories]
DUMP: estimated 39 blocks.
DUMP: Volume 1 started with block 1 at: Fri Jul 30 16:17:15 2021
DUMP: dumping (Pass III) [directories]
DUMP: dumping (Pass IV) [regular files]
DUMP: Closing /root/boot.bak1.bz2
DUMP: Volume 1 completed at: Fri Jul 30 16:17:15 2021
DUMP: 40 blocks (0.04MB) on 1 volume(s)
DUMP: finished in less than a second
DUMP: Date of this level 1 dump: Fri Jul 30 16:17:15 2021
DUMP: Date this dump completed: Fri Jul 30 16:17:15 2021
DUMP: Average transfer rate: 0 kB/s
DUMP: Wrote 40kB uncompressed, 11kB compressed, 3.637:1
DUMP: DUMP IS DONE
查看增量备份文件大小
[root@s135 ~]# ll -h /root
总用量 105M
-rw-------. 1 root root 1.8K 7月 30 16:03 anaconda-ks.cfg
-rw-r–r–. 1 root root 12K 7月 30 16:17 boot.bak1.bz2
-rw-r–r–. 1 root root 105M 7月 30 16:10 boot.bak.bz2
3、查询分区的最新备份记录
[root@s135 ~]# dump -W
Last dump(s) done (Dump ‘>’ file systems):
/dev/mapper/centos-root ( /) Last dump: never
/dev/sda1 ( /boot) Last dump: Level 1, Date Fri Jul 30 16:17:15 2021
/dev/mapper/centos-home ( /home) Last dump: never
4、备份文件或目录
备份文件和目录只能使用0级别,即只能全量备份。
[root@s135 ~]# dump -0j -f /home/etc.dump.bz2 /etc/
DUMP: Date of this level 0 dump: Fri Jul 30 16:23:29 2021
DUMP: Dumping /dev/mapper/centos-root (/ (dir etc)) to /home/etc.dump.bz2
DUMP: Label: none
DUMP: Writing 10 Kilobyte records
DUMP: Compressing output at compression level 2 (bzlib)
DUMP: mapping (Pass I) [regular files]
DUMP: mapping (Pass II) [directories]
DUMP: estimated 35010 blocks.
DUMP: Volume 1 started with block 1 at: Fri Jul 30 16:23:30 2021
DUMP: dumping (Pass III) [directories]
DUMP: dumping (Pass IV) [regular files]
DUMP: Closing /home/etc.dump.bz2
DUMP: Volume 1 completed at: Fri Jul 30 16:23:35 2021
DUMP: Volume 1 took 0:00:05
DUMP: Volume 1 transfer rate: 2470 kB/s
DUMP: Volume 1 39190kB uncompressed, 12350kB compressed, 3.174:1
DUMP: 39190 blocks (38.27MB) on 1 volume(s)
DUMP: finished in 5 seconds, throughput 7838 kBytes/sec
DUMP: Date of this level 0 dump: Fri Jul 30 16:23:29 2021
DUMP: Date this dump completed: Fri Jul 30 16:23:35 2021
DUMP: Average transfer rate: 2470 kB/s
DUMP: Wrote 39190kB uncompressed, 12350kB compressed, 3.174:1
DUMP: DUMP IS DONE
三、使用语法及参数说明
1、使用语法
#dump [参数]
2、参数说明
| 常用参数 | 参数说明 |
|---|---|
| -0123456789 | 备份的层级 |
| -b | 指定区块的大小,单位为KB |
| -B | 指定备份卷册的区块数目 |
| -c | 修改备份磁带预设的密度与容量 |
| -d | 设置磁带的密度。单位为BPI |
| -f | 指定备份设备 |
| -h | 当备份层级等于或大于指定的层级时,将不备份用户标示为”nodump”的文件 |
| -j | 使用bzlib库压缩备份文件 |
| -n | 当备份工作需要管理员介入时,向所有”operator”群组中的使用者发出通 |
| -s | 备份磁带的长度,单位为英尺 |
| -T | 指定开始备份的时间与日期 |
| -u | 备份完毕后,在/etc/dumpdates中记录备份的文件系统,层级,日期与时间等 |
| -w | 与-W类似,但仅显示需要备份的文件 |
| -W | 显示需要备份的文件及其最后一次备份的层级,时间与日期 |
restore恢复
一、命令简介
Linux restore命令用来还原由dump操作所备份下来的文件或整个文件系统(一个分区)。restore 指令所进行的操作和dump指令相反,dump操作可用来备份文件,而restore操作则是写回这些已备份的文件。可以从完整或部分备份中恢复单个文件和目录子树。
二、使用示例
1、获取命令帮助
#restore --help或者man restore |more
2、比较数据变化
比较变化参数-C只可以比较出更新或者删除的数据变化,在备份后新增的文件无法比较出来。
[root@s135 ~]# restore -C -f boot.bak.bz2
Dump tape is compressed.
Dump date: Fri Jul 30 16:16:41 2021
Dumped from: the epoch
Level 0 dump of /boot on s135:/dev/sda1
Label: none
filesys = /boot
[root@s135 ~]# rm -rf /boot/symvers-3.10.0-957.el7.x86_64.gz
[root@s135 ~]# restore -C -f boot.bak.bz2
Dump tape is compressed.
Dump date: Fri Jul 30 16:16:41 2021
Dumped from: the epoch
Level 0 dump of /boot on s135:/dev/sda1
Label: none
filesys = /boot
restore: unable to stat ./symvers-3.10.0-957.el7.x86_64.gz: No such file or directory
Some files were modified! 1 compare errors
3、查看模式查看备份文件包含的文件内容
[root@s135 ~]# restore -t -f boot.bak.bz2
Dump tape is compressed.
Dump date: Fri Jul 30 16:16:41 2021
Dumped from: the epoch
Level 0 dump of /boot on s135:/dev/sda1
Label: none
2 .
11 ./lost+found
12 ./efi
13 ./efi/EFI
14 ./efi/EFI/centos
8193 ./grub2
24 ./grub2/device.map
25 ./grub2/i386-pc
27 ./grub2/i386-pc/testload.mod
29 ./grub2/i386-pc/cbtable.mod
31 ./grub2/i386-pc/normal.mod
32 ./grub2/i386-pc/legacy_password_test.mod
…
22 ./initramfs-0-rescue-c0886fb731a041bb9fee61901f7b6427.img
23 ./vmlinuz-0-rescue-c0886fb731a041bb9fee61901f7b6427
333 ./initramfs-3.10.0-957.el7.x86_64kdump.img
4、全量备份还原
# restore -r -f /root/boot.bak.bz2全量备份还原
[root@s135 boot]# ll
总用量 106440
-rw-r–r–. 1 root root 151918 11月 9 2018 config-3.10.0-957.el7.x86_64
drwxr-xr-x. 3 root root 4096 7月 30 15:56 efi
drwxr-xr-x. 2 root root 4096 7月 30 15:57 grub
drwx------. 5 root root 4096 7月 30 16:03 grub2
-rw-r–r–. 1 root root 15 7月 30 16:13 hi.txt
-rw-------. 1 root root 57412428 7月 30 16:01 initramfs-0-rescue-c0886fb731a041bb9fee61901f7b6427.img
-rw-------. 1 root root 21379638 7月 30 16:03 initramfs-3.10.0-957.el7.x86_64.img
-rw-------. 1 root root 13176073 7月 30 16:05 initramfs-3.10.0-957.el7.x86_64kdump.img
drwx------. 2 root root 16384 7月 30 15:56 lost+found
-rw-------. 1 root root 3543471 11月 9 2018 System.map-3.10.0-957.el7.x86_64
-rwxr-xr-x. 1 root root 6639904 7月 30 16:01 vmlinuz-0-rescue-c0886fb731a041bb9fee61901f7b6427
-rwxr-xr-x. 1 root root 6639904 11月 9 2018 vmlinuz-3.10.0-957.el7.x86_64
[root@s135 boot]# restore -r -f /root/boot.bak.bz2
Dump tape is compressed.
restore: ./lost+found: File exists
restore: ./efi: File exists
restore: ./efi/EFI: File exists
restore: ./efi/EFI/centos: File exists
restore: ./grub2: File exists
restore: ./grub2/i386-pc: File exists
restore: ./grub2/locale: File exists
restore: ./grub2/fonts: File exists
restore: ./grub: File exists
5、增量备份还原
#创建还原临时目录
[root@s135 ~]# mkdir bootdir
[root@s135 ~]# cd bootdir/
#首先完成全量备份还原
[root@s135 bootdir]# restore -r -f /root/boot.bak.bz2
Dump tape is compressed.
[root@s135 bootdir]# ll
总用量 106876
-rw-r–r–. 1 root root 151918 11月 9 2018 config-3.10.0-957.el7.x86_64
drwxr-xr-x. 3 root root 4096 7月 30 15:56 efi
drwxr-xr-x. 2 root root 4096 7月 30 15:57 grub
drwx------. 5 root root 4096 7月 30 16:03 grub2
-rw-------. 1 root root 57412428 7月 30 16:01 initramfs-0-rescue-c0886fb731a041bb9fee61901f7b6427.img
-rw-------. 1 root root 21379638 7月 30 16:03 initramfs-3.10.0-957.el7.x86_64.img
-rw-------. 1 root root 13176073 7月 30 16:05 initramfs-3.10.0-957.el7.x86_64kdump.img
drwx------. 2 root root 4096 7月 30 15:56 lost+found
-rw-------. 1 root root 144136 8月 2 10:41 restoresymtable
-rw-r–r–. 1 root root 314036 11月 9 2018 symvers-3.10.0-957.el7.x86_64.gz
-rw-------. 1 root root 3543471 11月 9 2018 System.map-3.10.0-957.el7.x86_64
-rwxr-xr-x. 1 root root 6639904 7月 30 16:01 vmlinuz-0-rescue-c0886fb731a041bb9fee61901f7b6427
-rwxr-xr-x. 1 root root 6639904 11月 9 2018 vmlinuz-3.10.0-957.el7.x86_64
#然后还原增量备份
[root@s135 bootdir]# restore -r -f /root/boot.bak1.bz2
Dump tape is compressed.
[root@s135 bootdir]# ll
总用量 106880
-rw-r–r–. 1 root root 151918 11月 9 2018 config-3.10.0-957.el7.x86_64
drwxr-xr-x. 3 root root 4096 7月 30 15:56 efi
drwxr-xr-x. 2 root root 4096 7月 30 15:57 grub
drwx------. 5 root root 4096 7月 30 16:03 grub2
-rw-r–r–. 1 root root 15 7月 30 16:13 hi.txt
-rw-------. 1 root root 57412428 7月 30 16:01 initramfs-0-rescue-c0886fb731a041bb9fee61901f7b6427.img
-rw-------. 1 root root 21379638 7月 30 16:03 initramfs-3.10.0-957.el7.x86_64.img
-rw-------. 1 root root 13176073 7月 30 16:05 initramfs-3.10.0-957.el7.x86_64kdump.img
drwx------. 2 root root 4096 7月 30 15:56 lost+found
-rw-------. 1 root root 144208 8月 2 10:44 restoresymtable
-rw-r–r–. 1 root root 314036 11月 9 2018 symvers-3.10.0-957.el7.x86_64.gz
-rw-------. 1 root root 3543471 11月 9 2018 System.map-3.10.0-957.el7.x86_64
-rwxr-xr-x. 1 root root 6639904 7月 30 16:01 vmlinuz-0-rescue-c0886fb731a041bb9fee61901f7b6427
-rwxr-xr-x. 1 root root 6639904 11月 9 2018 vmlinuz-3.10.0-957.el7.x86_64
6、交互式模式下还原指定文件
#创建还原临时目录
[root@s135 ~]# mkdir bootdir
#进入交互模式
[root@s135 bootdir]# restore -i -f /root/boot.bak.bz2
Dump tape is compressed.
#获取交互式下的命令帮助
restore > help
Available commands are:
ls [arg] - list directory
cd arg - change directory
pwd - print current directory
add [arg] - addarg' to list of files to be extracted delete [arg] - deletearg’ from list of files to be extracted
extract - extract requested files
setmodes - set modes of requested directories
quit - immediately exit program
what - list dump header information
verbose - toggle verbose flag (useful with ``ls’’)
prompt - toggle the prompt display
help or?' - print this list If noarg’ is supplied, the current directory is used
#列出备份文件中的内容
restore > ls
.:
.vmlinuz-3.10.0-957.el7.x86_64.hmac
System.map-3.10.0-957.el7.x86_64
config-3.10.0-957.el7.x86_64
efi/
grub/
grub2/
initramfs-0-rescue-c0886fb731a041bb9fee61901f7b6427.img
initramfs-3.10.0-957.el7.x86_64.img
initramfs-3.10.0-957.el7.x86_64kdump.img
lost+found/
symvers-3.10.0-957.el7.x86_64.gz
vmlinuz-0-rescue-c0886fb731a041bb9fee61901f7b6427
vmlinuz-3.10.0-957.el7.x86_64
#将config-3.10.0-957.el7.x86_64文件添加到还原列表
restore > add config-3.10.0-957.el7.x86_64
#开始原因
restore > extract
You have not read any volumes yet.
Unless you know which volume your file(s) are on you should start
with the last volume and work towards the first.
Specify next volume # (none if no more volumes): 1
set owner/mode for ‘.’? [yn] n
restore > quit
[root@s135 bootdir]# ls
config-3.10.0-957.el7.x86_64
三、使用语法及参数说明
1、使用语法
#restore [模式] [选项]
2、模式参数说明
| 参数 | 参数说明 |
|---|---|
| -C | 比较备份数据和实际数据的变化 |
| -i | 进入交互模式手动指定需要恢复的文件 |
| -P | 还原从现有转储文件创建新的快速文件访问文件,而不还原其内容 |
| -R | 全面还原文件系统时,检查应从何处开始进行。 |
| -r | 还原模式,用于数据还原 |
| -t | 查看模式,查看备份文件中的数据 |
| -x | 设置文件名称,且从指定的存储媒体里读入它们,若该文件已存在在备份文件中,则将其还原到文件系统内。 |
3、常用选项参数说明
| 参数 | 参数说明 |
|---|---|
| -b<区块大小> | 设置区块大小,单位是Byte。 |
| -c | 不检查dump操作的备份格式,仅准许读取使用旧格式的备份文件。 |
| -D<文件系统> | 允许用户指定文件系统的名称。 |
| -f<备份文件> | 从指定的文件中读取备份数据,进行还原操作。 |
| -h | 仅解出目录而不包括与该目录相关的所有文件。 |
| -m | 解开符合指定的inode编号的文件或目录而非采用文件名称指定。 |
| -s<文件编号> | 当备份数据超过一卷磁带时,您可以指定备份文件的编号。 |
| -v | 显示指令执行过程。 |
| -y | 不询问任何问题,一律以同意回答并继续执行指令。 |
Linux图形化界面-webmin和bt宝塔
webmin由于太老不多做介绍,可查看Linux操作系统——Linux可视化管理-webmin 和 bt 运维工具_linux可视化管理工具_胖虎不秃头的博客-CSDN博客
一、宝塔面板简介
宝塔面板是一款服务器管理软件,支持windows和linux系统,可以通过Web端轻松管理服务器,提升运维效率。例如:创建管理网站、FTP、数据库,拥有可视化文件管理器,可视化软件管理器,可视化CPU、内存、流量监控图表,计划任务等功能。宝塔面板拥有极速方便的一键配置与管理,可一键配置服务器环境(LAMP/LNMP/Tomcat/Node.js),一键部署SSL,异地备份;提供SSH开启关闭服务,SSH端口更改,禁ping,防火墙端口放行以及操作日志查看;CPU、内存、磁盘IO、网络IO数据监测,可设置记录保存天数以及任意查看某天数据;计划任务可按周期添加执行,支持SHELL脚本,提供网站、数据库备份以及日志切割,且支持一键备份到又拍云存储空间,或者其他云存储空间里;通过web界面就可以轻松管理安装所用的服务器软件,还有实用的扩展插件;集成方便高效的文件管理器,支持上传、下载、打包、解压以及文件编辑查看。
博文实验环境:
- 操作系统:centos7.9
- 宝塔面板版本:7.9.0
二、安装步骤
0、安装要求:
- 内存:512M以上,推荐768M以上(纯面板约占系统60M内存)
- 硬盘:300M以上可用硬盘空间(纯面板约占20M磁盘空间)
- 系统:CentOS 7.1+ (Ubuntu16.04+.、Debian9.0+),确保是干净的操作系统,没有安装过其它环境带的Apache/Nginx/php/MySQL/pgsql/gitlab/java(已有环境不可安装)
- 架构:x86_64
2、安装wget命令
[root@s146 ~]# yum install -y wget
3、下载安装脚本
[root@s146 ~]# wget -O install.sh http://download.bt.cn/install/install_6.0.sh
4、执行安装脚本
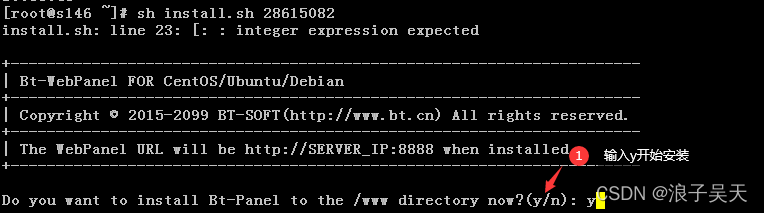
#请注意,需要root用户执行安全脚本
[root@s146 ~]# sh install.sh 28615082
5、注册一个宝塔账户
利用安装间隙注册一个宝塔账户,脚本安装执行大概需要10分钟。
6、安装完成
安装完成后会有如下提示,请保存用户名、密码、面板地址。登录宝塔面板需要使用到。另外如果需要访问外网面板地址需要在出口防火墙上进行NAT映射和安全策略开放。
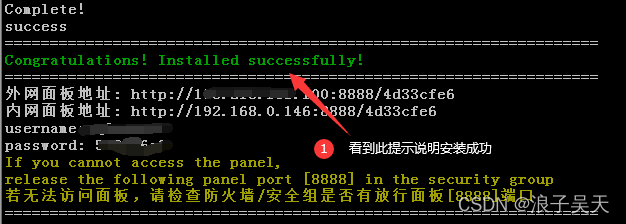
7、登录宝塔面板
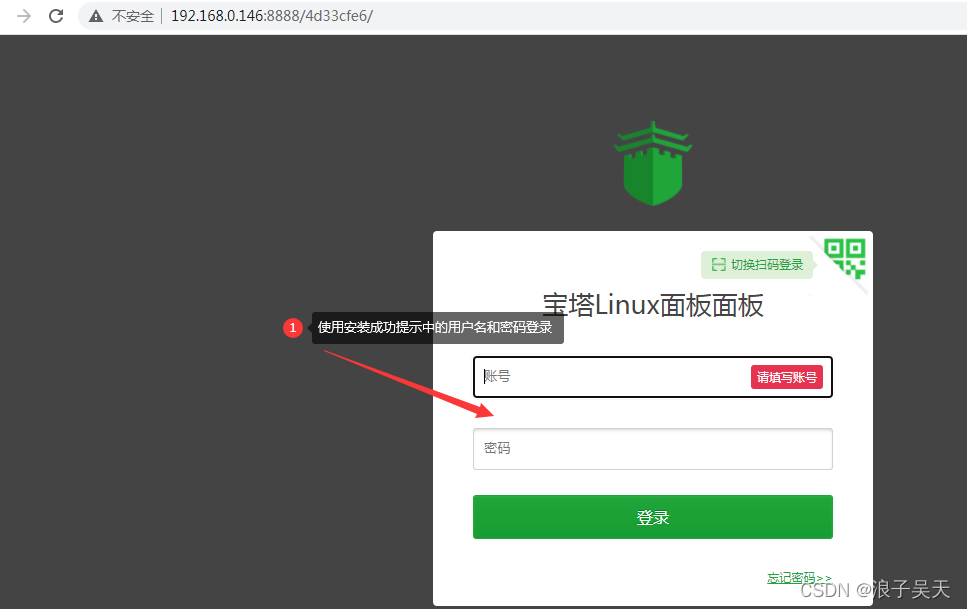
8、阅读并同意用户协议
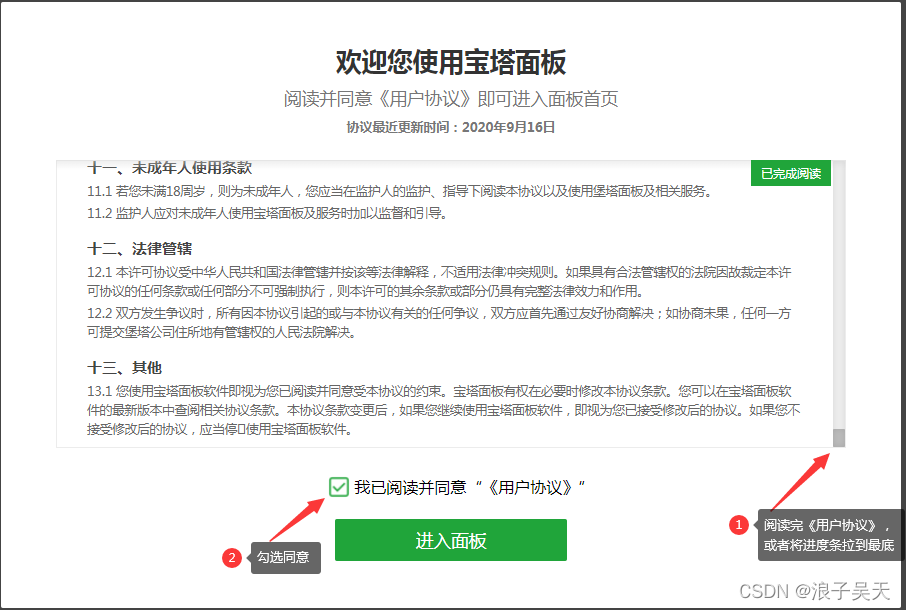
9、绑定宝塔官网注册的账号
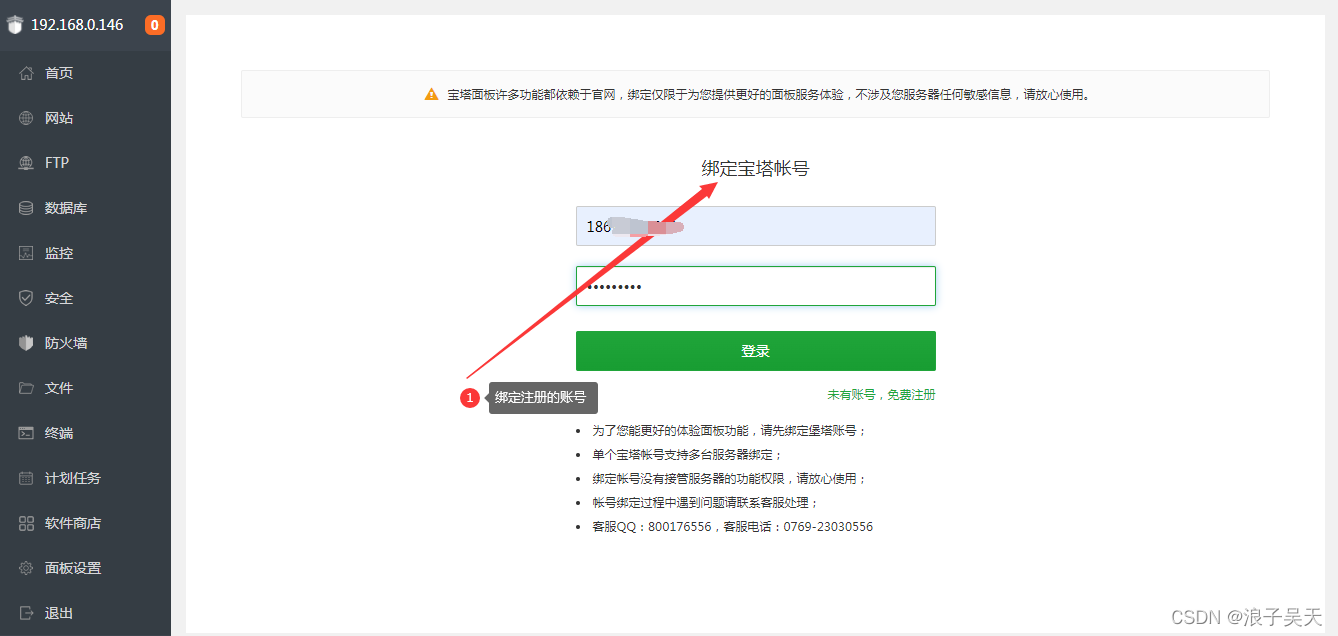
10、宝塔面板安装完成
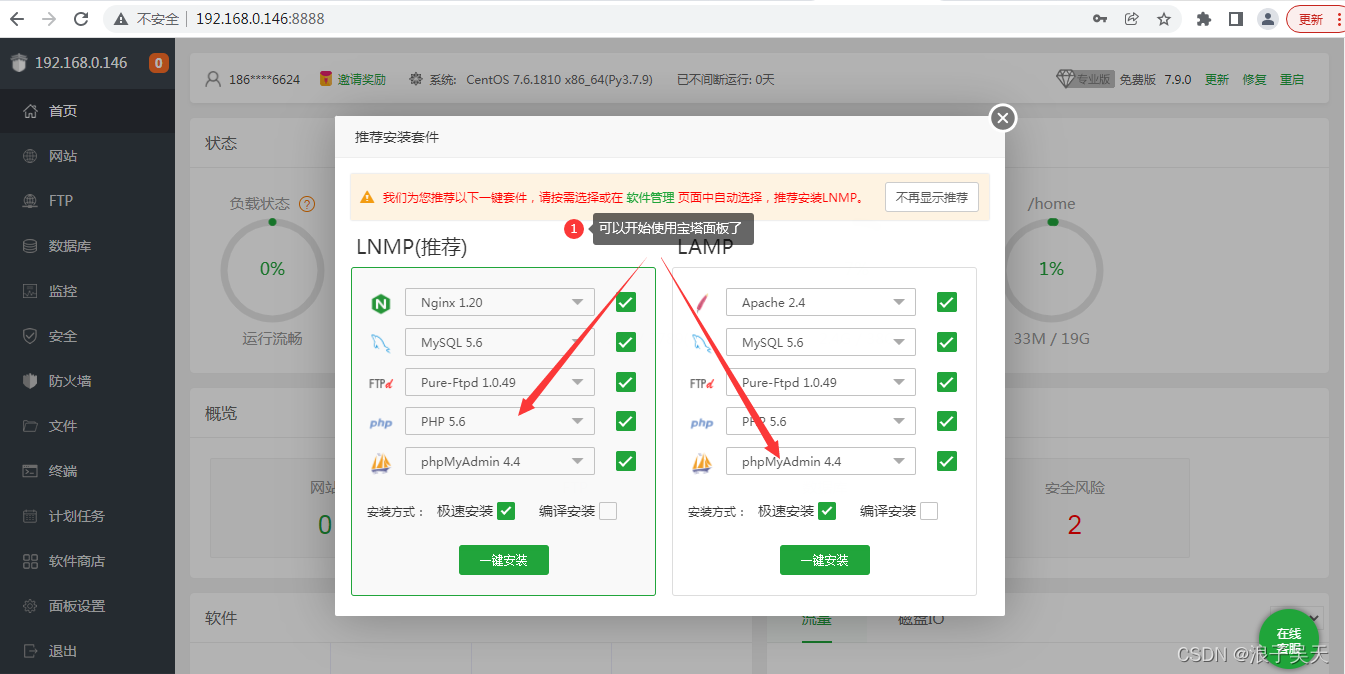
三、使用简介
1、软件安装示例——ftp软件安装
- 软件商店搜索ftp并选择Pure-Ftpd,点击安装

- 点击确定
- 安装完成
- 添加ftp账户
- ftp登录测试
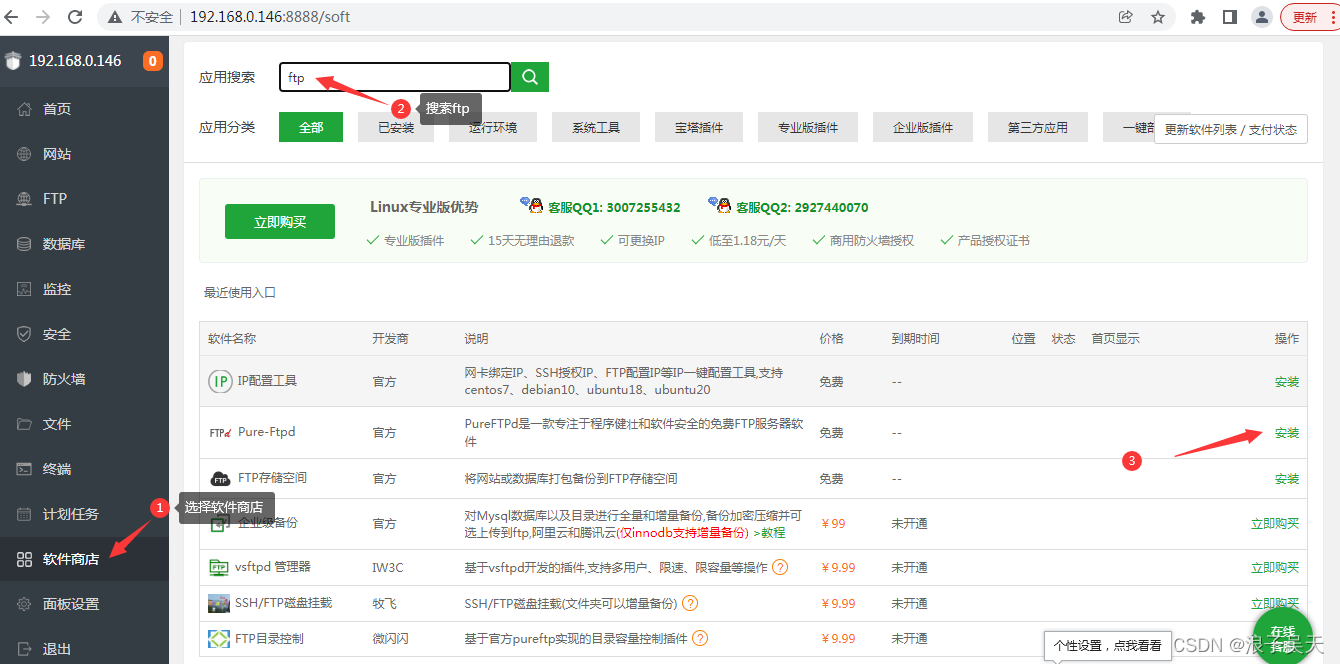
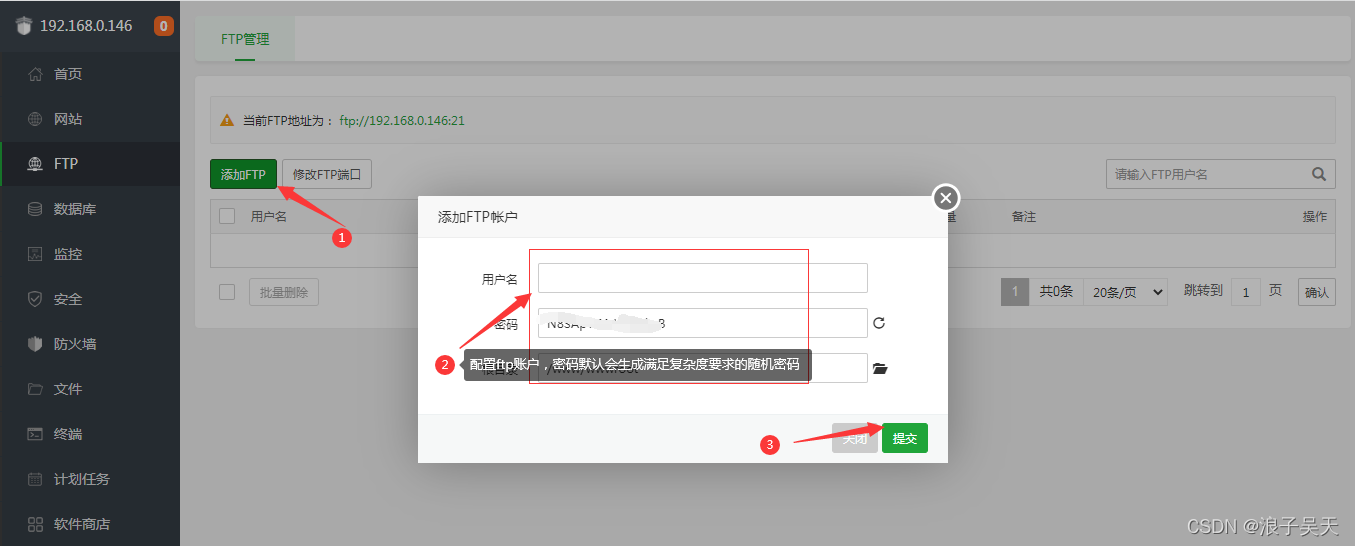
2、面板设置
- 面板设置
- 安全设置
- 通知设置
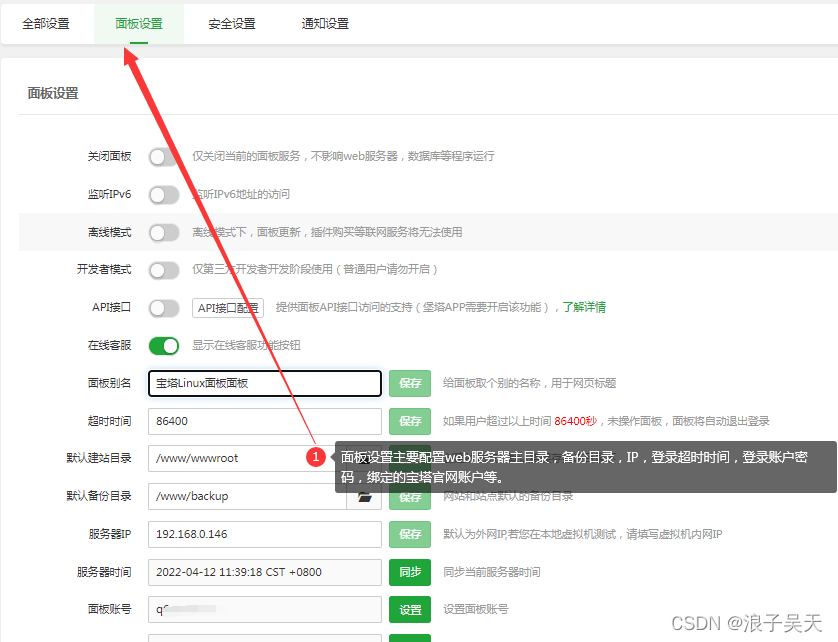
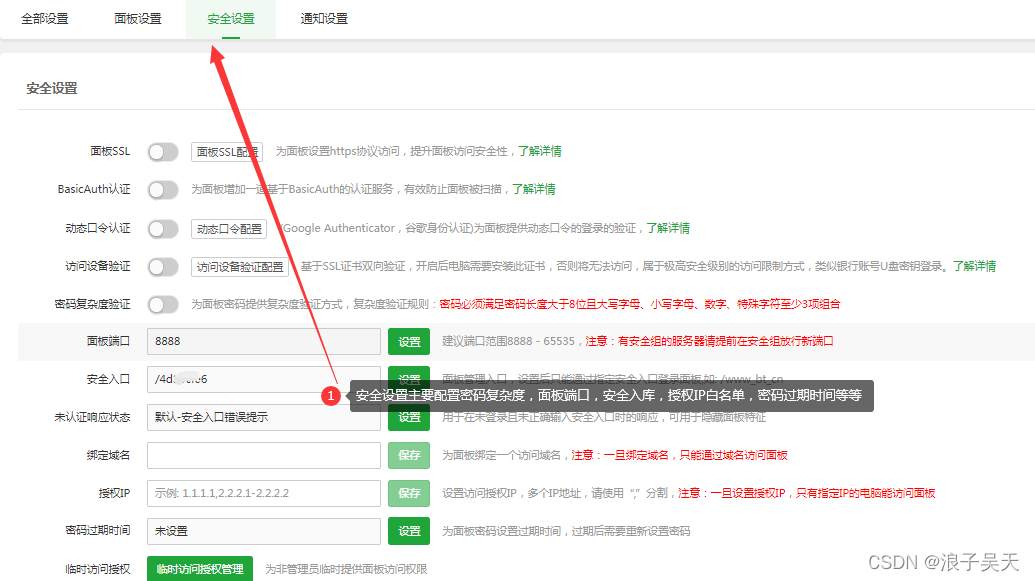
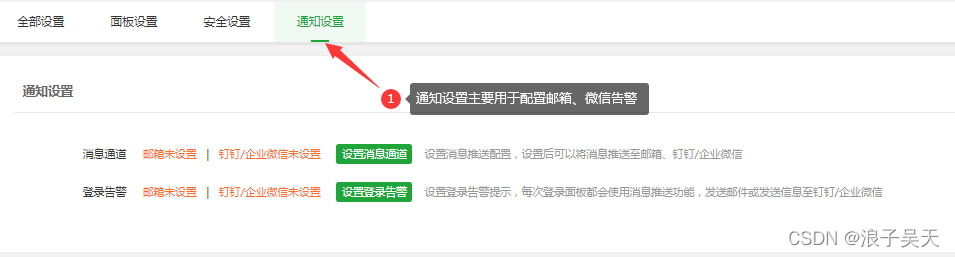
3、命令行终端操作
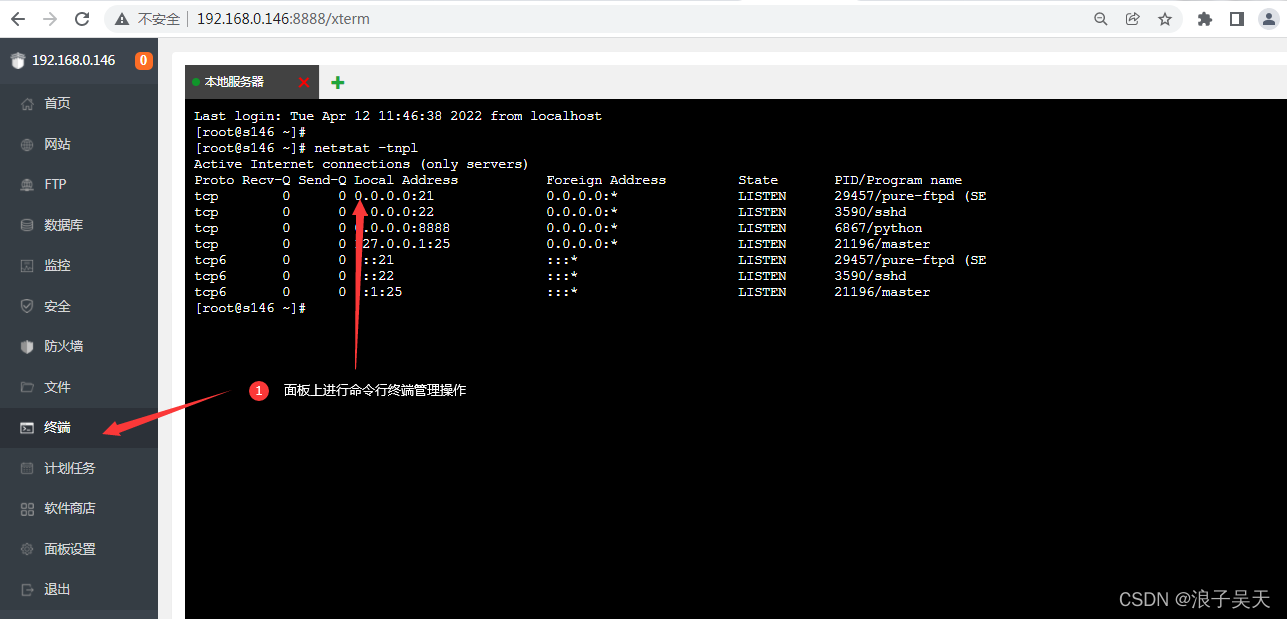
4、安全管理
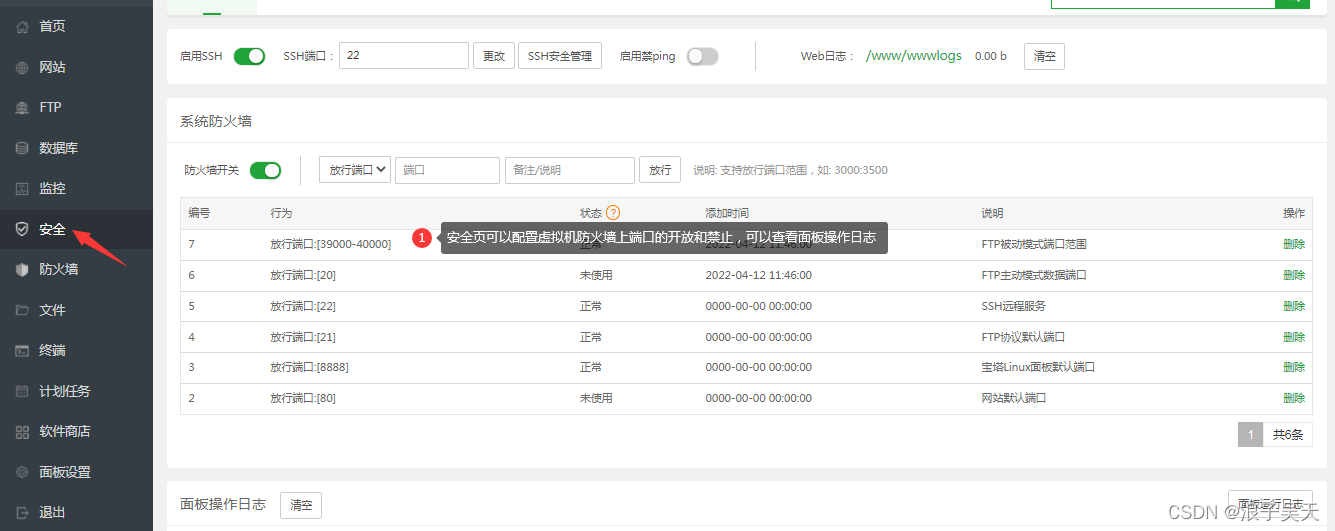
5、文件上传下载
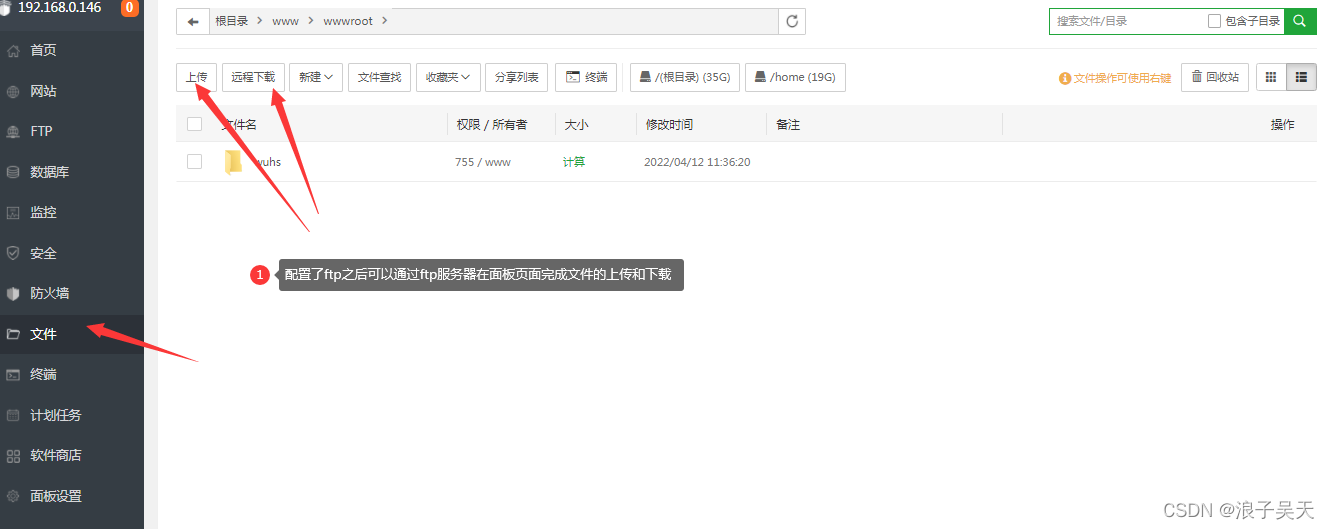
6、定时任务
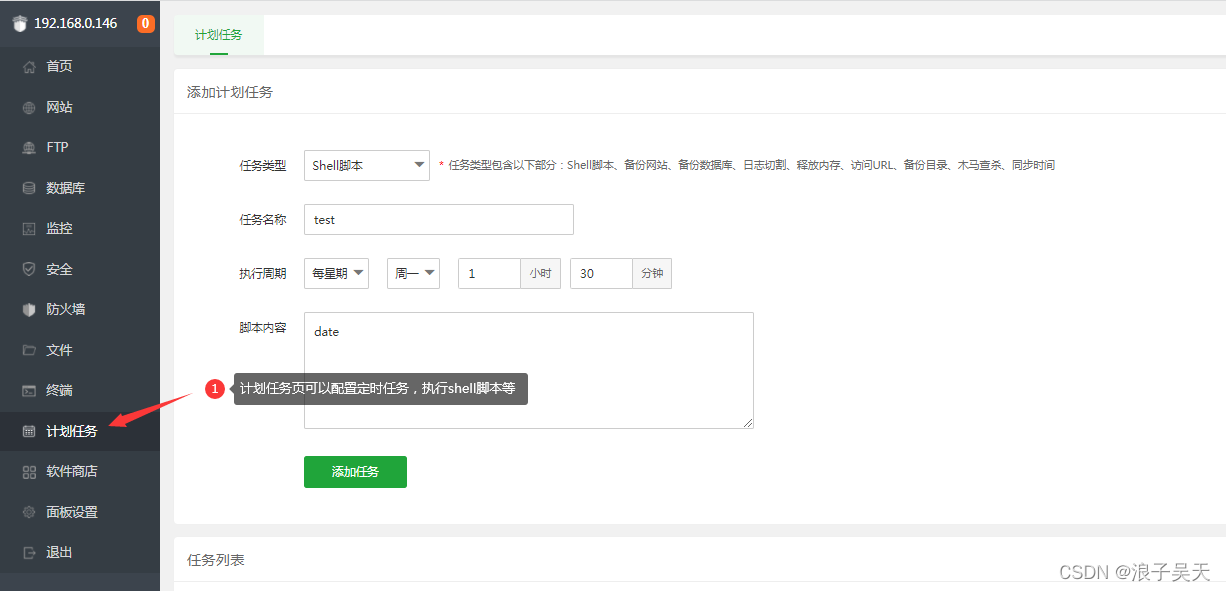
7、系统监控
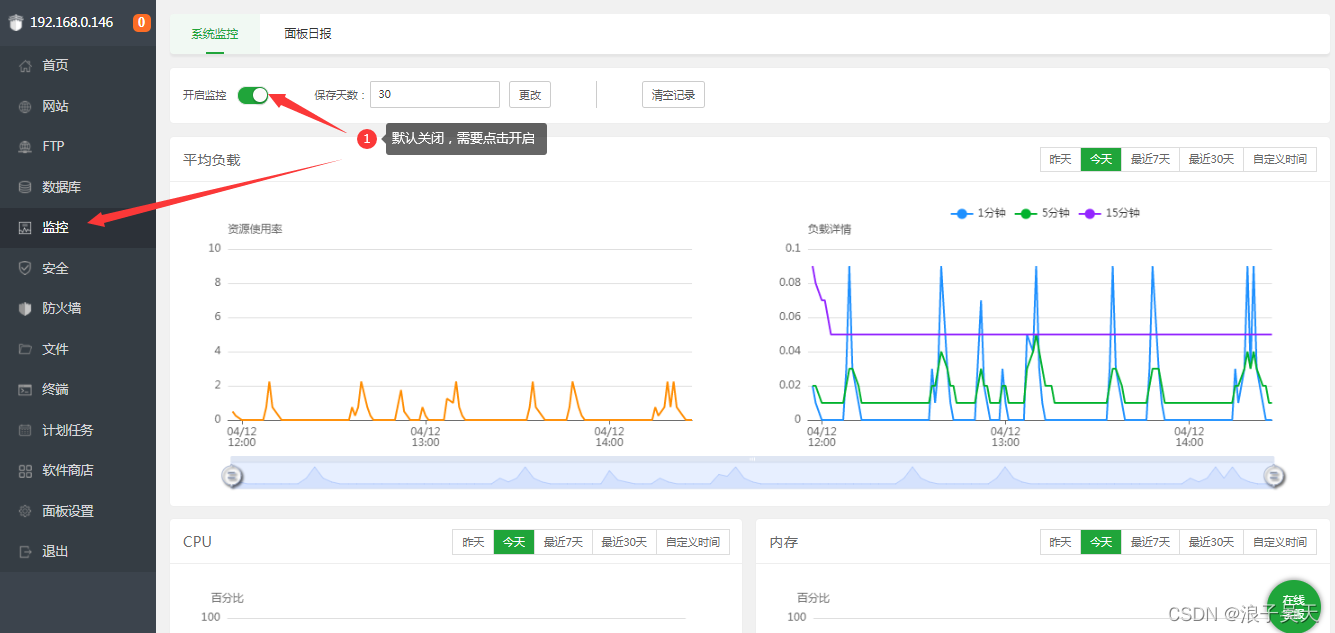
8、服务启停管理
- 查看宝塔面板服务状态
[root@s146 ~]# bt status
Bt-Panel (pid 6867) already running
Bt-Task (pid 6893) already running
- 启动宝塔面板服务
[root@s146 ~]# bt start
Starting Bt-Panel… done
Starting Bt-Tasks… done
- 停止宝塔面板服务
[root@s146 ~]# bt stop
Stopping Bt-Tasks… done
Stopping Bt-Panel… done
- 重启宝塔面板服务
[root@s146 ~]# bt restart
Stopping Bt-Tasks… done
Stopping Bt-Panel… done
Starting Bt-Panel… done
Starting Bt-Tasks… done
- 重载宝塔面板服务配置
[root@s146 ~]# bt reload
Reload Bt-Panel… done
- 查看宝塔面板日志
[root@s146 ~]# bt logs
192.168.0.32 - - [2022-04-12 11:57:06] “GET /static/img/soft_ico/ico-php_filter.png HTTP/1.1” 304 188 0.007153
192.168.0.32 - - [2022-04-12 11:57:06] “GET /static/img/soft_ico/ico-coll_admin.png HTTP/1.1” 304 188 0.005967
…
- 查看宝塔面板默认信息
bt default
此指令可用于查看当前宝塔的账户和密码,如果忘记了的话
BT-Panel default info!
…
四、QA
1、报错请使用正确的入口登录面板
- 报错信息:
- 报错原因:当前新安装的已经开启了安全入口登录,新装机器都会随机一个8位字符的安全入口名称
- 解决方案:
使用安全入库url链接访问,就是安装完成后提示中的内网面板地址。如果未保持,可以使用命令bt default命令查看。
2.正在重新连接服务器
此情况是ssh面板开启导致的,关闭ssh面板即可
注:宝塔面板 账户和密码为 vljenqxz 55ab60cb
ftp账户 密码为root XTj2wR3zk84Fd5t8
数据库名:www_godwad_com
用户:www_godwad_com
密码:BysXzkcYnH
访问站点:http://www.godwad.com/index.php
数据库:MySQL数据库编码:utf8mb4账号:666_com密码:KBHt4MYkaE
防木马病毒入侵—chkrootkit
Rootkit是一种特殊的恶意软件,它的功能是在安装目标上隐藏自身及指定的文件、进程和网络链接等信息,比较多见到的是Rootkit一般都和木马、后门等其他恶意程序结合使用。Rootkit一词更多地是指被作为驱动程序,加载到操作系统内核中的恶意软件。
chkrootkit简介
chkrootkit是一个linux下检RootKit的脚本,在某些检测中会调用当前目录的检测程序
下载源码:wget ftp://ftp.pangeia.com.br/pub/seg/pac/chkrootkit.tar.gz
解压后执行 make 命令,就可以使用了
一般直接运行,一旦有INFECTED,说明可能被植入了RootKit
1 | ./chkrootkit | grep INFECTED |
Linux面试题(节选)
cut分割 3为分割后的第三段 sort排序(从小到大) uniq -c统计次数
sort -nr从大到小排
awk分割与cut原理相同
awk -F " "分割空格 ’ {printf $5表示分割出来的第五段} ’
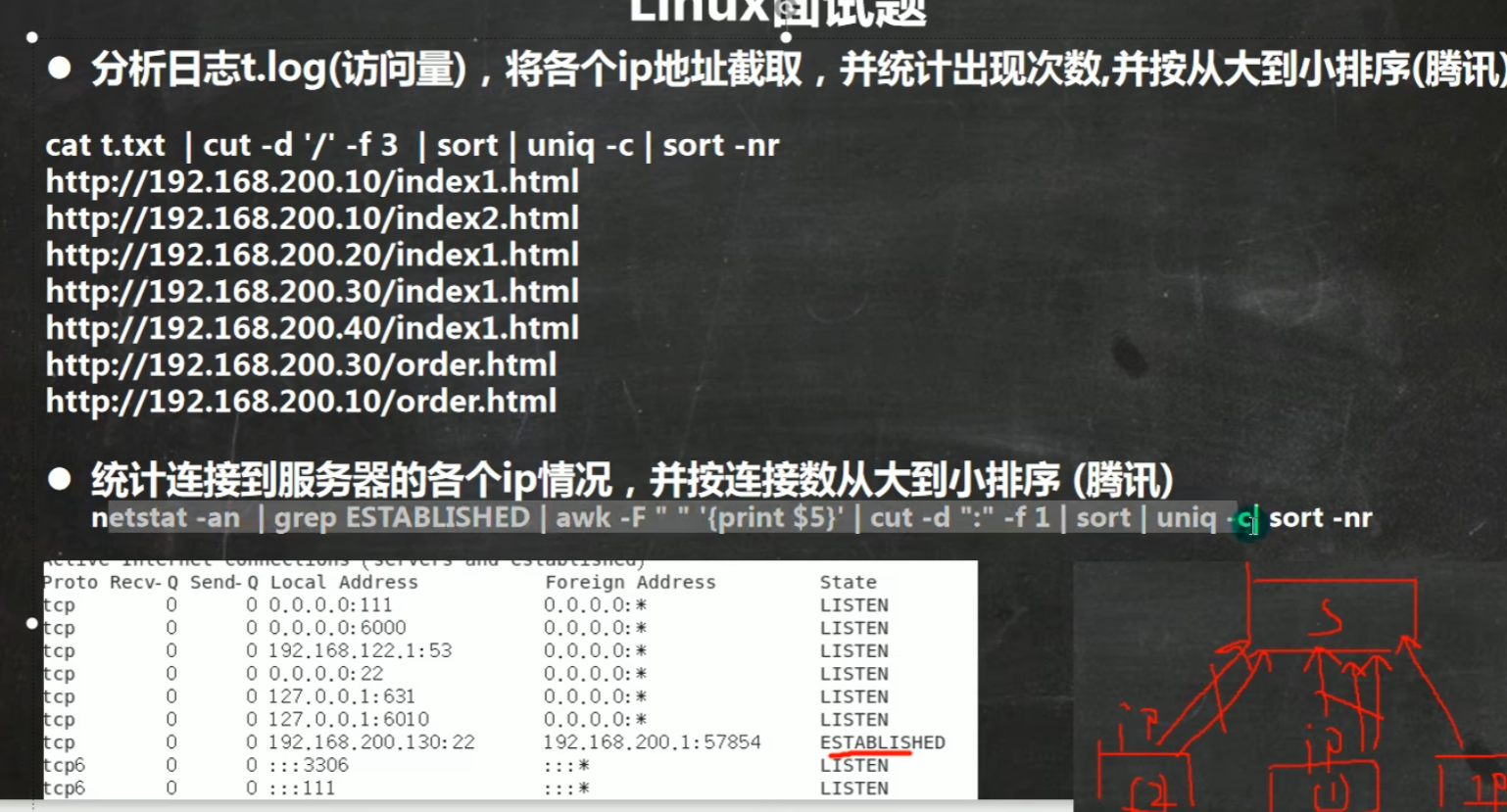
1 | 1.用户tom对目录/home/test有执行x和读r写w权限,/home/test/hello.java是只读文件,问tom对 |
1 | Linux面试题 |
1 | Linux面试题 |
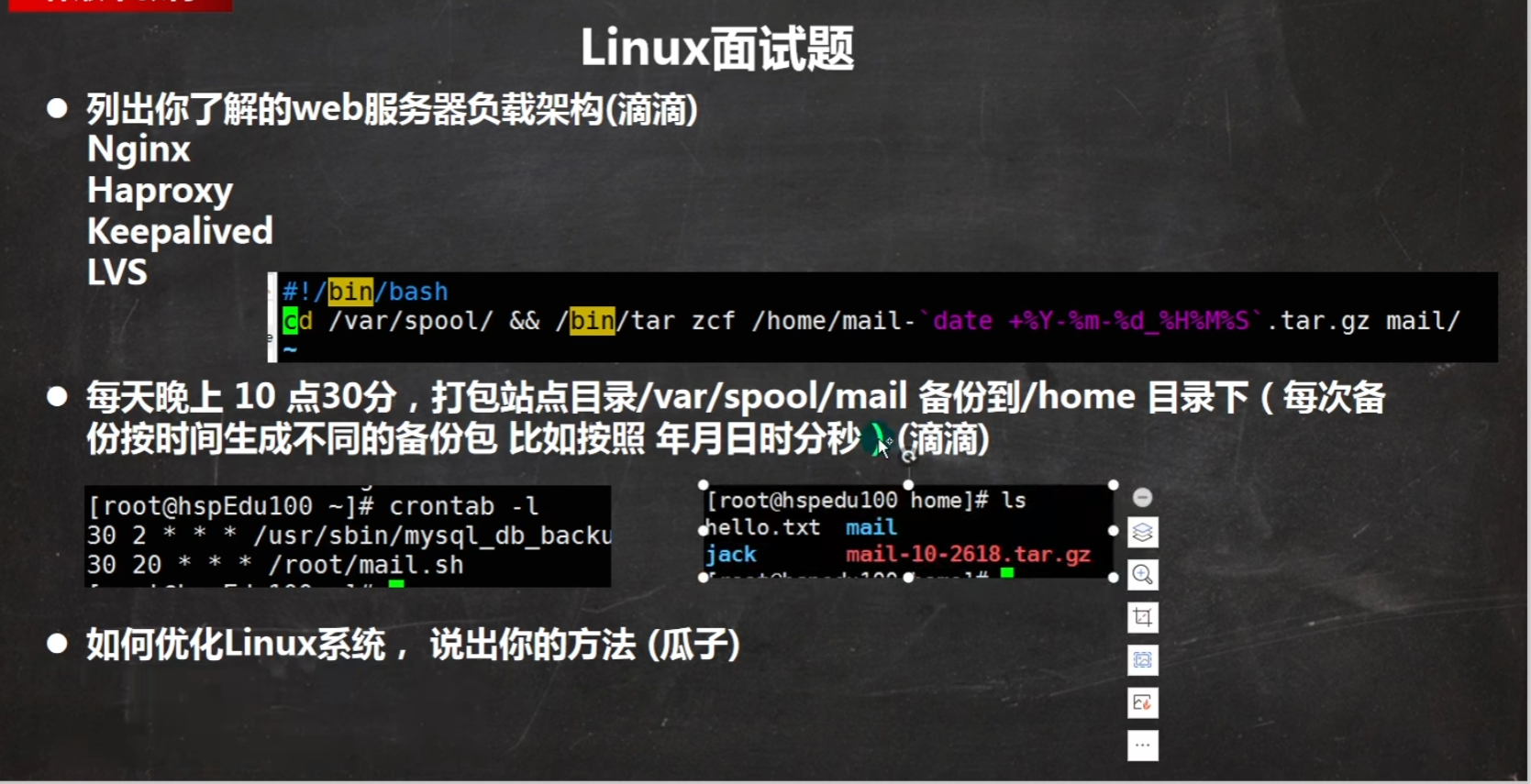
1 | 如何优化Linux系统,说出你的方法 |