
硬件茶谈
手柄测试网站
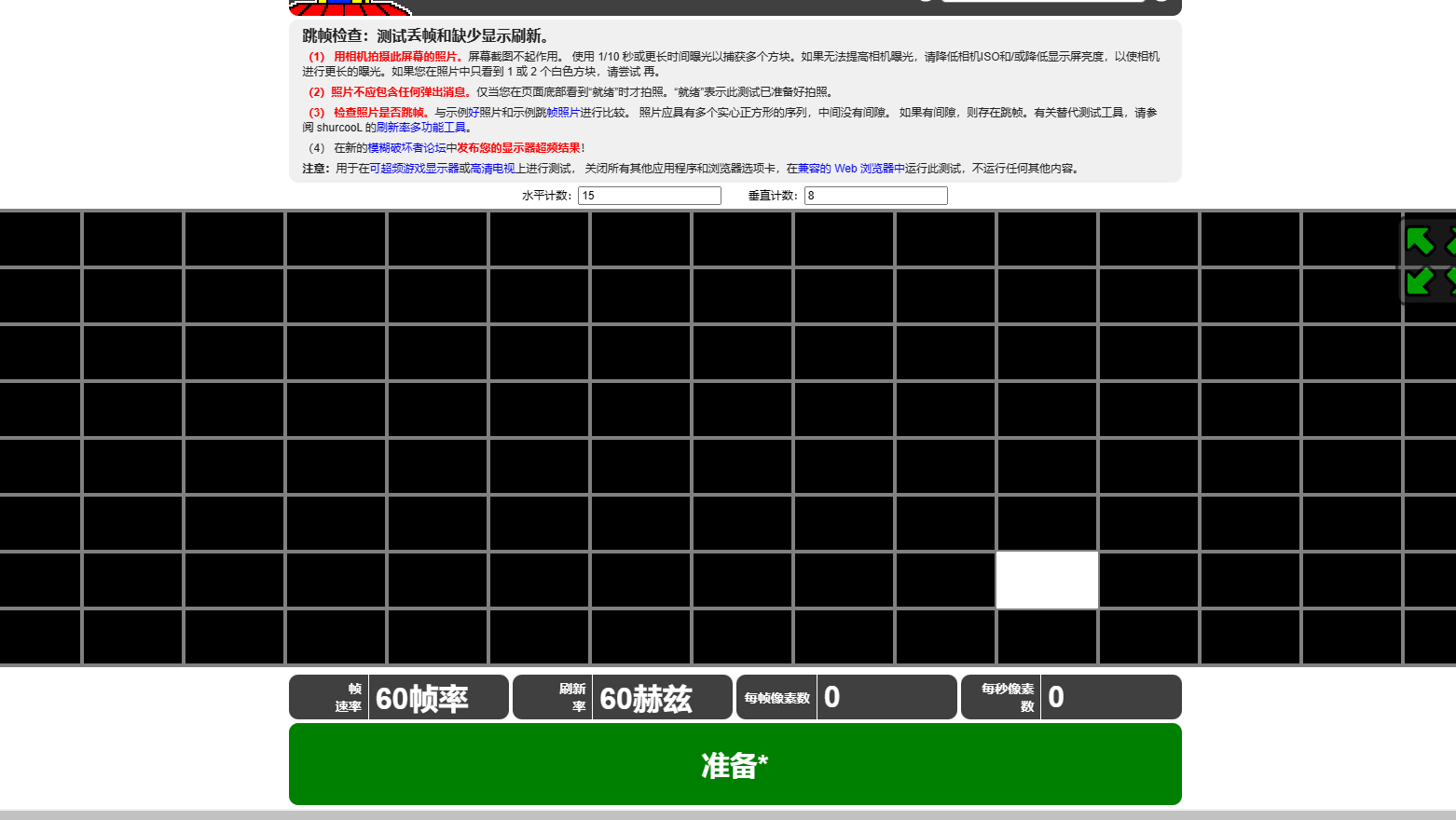
如何检测144帧显示器是否为真?
进入www.ufotest.com,进入frame skipping test 跳帧测试即可,如图,若白块连续运动(可将视频录下来后满放),不发生跳格,即为真
ECC内存如何发现错误并进行纠错?(汉明码)
电脑内存,安插在主板右侧的 DIMM 内存插槽中。每次开机时, CPU 会把要运算的各种数据从硬盘读取到内存,之后和内存交互数据。内存的稳定性很大程度决定了电脑平台运行时的稳定性。但是我们所处的空间中处处都包含着各式各样的无线电磁干扰,包括电脑内部的电路噪声也会干扰到内存的正常运行。.

这些干扰会导致内存和 CPU 在交互数据时发生比特翻转,某个 0 变成 1 或者某个 1 变成0。如果比特翻转发生在某些不重要的数据上,可能只是单纯的导致软件报错或者闪退,但是如果发生在重要的系统或者驱动数据上,就可能导致电脑蓝屏死机。对于家用 PC 来讲,绝大多数内存错误都可以通过重启解决,毕竟重启以后,内存里的数据又都会再重新写入一遍,错误也就被更正了。但是对于服务器来讲,一次宕机可能会造成灾难级的损失,所以服务器往往会使用稳定性更高的 ECC 内存,这种内存可以主动发现数据传输过程中出现的错误,并将错误纠正。不过大多数媒体只是提及 ECC 内存能纠错,并未阐述其原理。所以本期节目我们带你详细了解一下 ECC 内存究竟是如何发现错误并纠正的。



如果有某组数据发生了错误,通过对比其他两组数据,就能定位错误的位置并纠正。不过这种方案也有很大的弊端,假如有两组数据正好在同一个位置发生了比特翻转,在纠错的过程中就会把错误的数据当成正确的。不过这倒不算什么硬伤,毕竟同时发生两个错误还同时出现在一个位置的可能性太低,真正的硬伤还是浪费带宽。
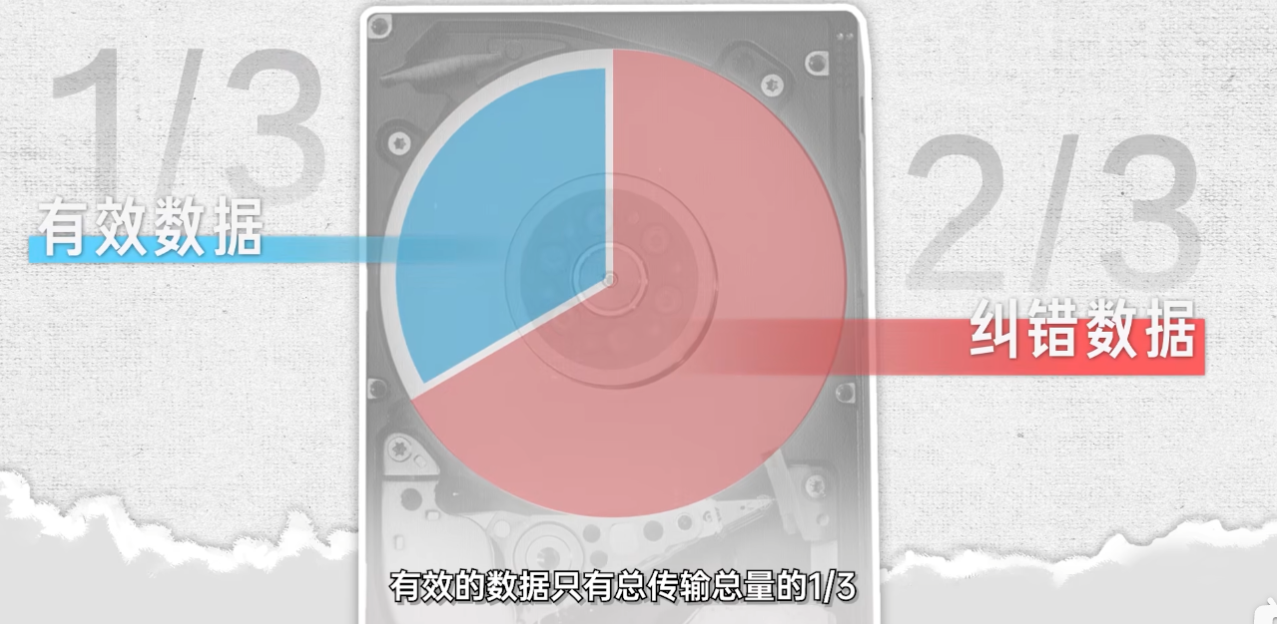
三组数据中有效的数据只有传输总量的 1/ 3,有 2/ 3 的数据都属于纠错码。为了能减少纠错码的占比,人们想到了一个非常巧妙的方法奇偶校验。我们知道计算机用的是二进制,二进制的数只有 0 和1。我们通过在数据的开头增加一位纠错码,然后数出原始数据中 1 的个数。如果 1 的个数是偶数,那纠错码就保持是 0 不变。如果 1 的个数是奇数,纠错码变成1,把总数据的 1 的个数填补成偶数。这样接收方接收到数据以后,收到的数据中,如果 1 的个数是偶数,说明数据没有错误如果是基数,说明数据发生了错误,再重新传输一个新的数据即可。这极大程度的节约了带宽。

这时候你可能会好奇地问道要是纠错码自己发生了,比特翻转呢?仔细思考一下,你会发现没有影响纠错码发生了比特翻转, 1 的总个数也是会变成奇数。接收方还是会发现数据组中有错误。奇偶校验不是用一个数据去保护其他的数据,而是通过一个数据改变整组数据的既有性。纠错码本身就存在于这组数据中,换而言之,纠错码在保护其他数据的同时,也在保护自己。不过通过这个性质,你会发现,基耦校验只能单纯的知道数据错了,并不知道错在哪里。发现错误以后,必须要等待发送方重新发送,无形间会造成延迟。同时你应该发现了,单纯的依靠基偶信无法处理两位数据错误。如果同时有两个 0 比特翻转成了1,或者某个 1 变成 0 的同时又有一个 0 变成1,那 1 的总个数还是偶数。

为了解决奇偶校验的这两个问题,理查德汉民在奇偶校验的基础上发明了汉民码,也就是目前绝大多数 ECC 内存使用的纠错码。它用很少的纠错码对大量的数据进行错误的查找和纠正。利用基友校验,我们可以知道数据中有没有发生错误,再通过一定的交集和排除,我们就能确定错误数据的位置。这就是汉密码的核心原理。这里有一个 16 比特的数据串,为了方便后面的理解,我们按顺序把它排列成 4* 4 的数据矩阵。
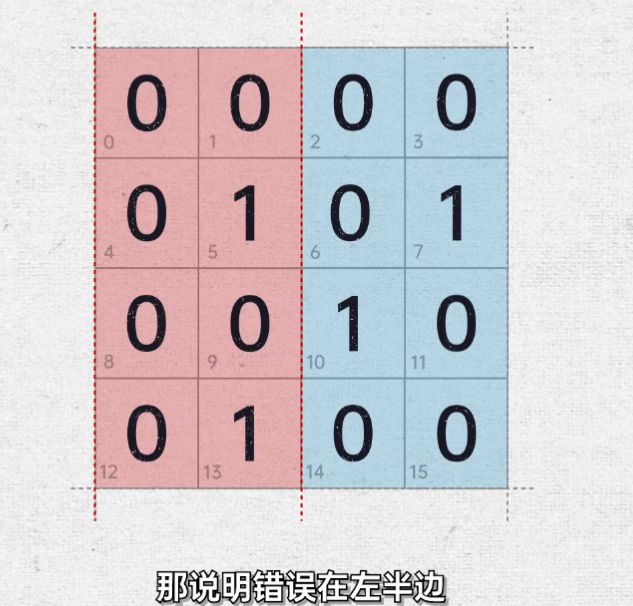
要想能定位错误数据的位置, 将数据按照一定的规律分成不同的几组,让它们之间有一定的交集。这个交集该怎么取?计算机中有一个定位数据的好方法二分法。我们只对一半的数据再做检查,如果错误不在这一半,就在另一半。比如,我们可以让 2 号数据位不再存放原始数据,而是对右半边的数据进行基偶校验。目前右半边的数据中有两个 1 已经是偶数了,所以我们的 2 号校验码保持是 0 即可。这时候,假设有一个数据在传输过程中发生了错误,接收方收到数据以后,如果发现右半边的 1 的个数是奇数,说明错误在右半边。如果右半边的 1 的个数是偶数,说明错误在左半边。顺着这个思路往下捋,我们还需要一个纠错码,继续把一半的数据再对半分来进一步缩小范围。比如我们可以设置第1号数据为纠错码,也不存放原始数据了,而是用来对 24 列的数据进行基偶校验。我们发现 24 列里有 3 个1,所以我们让 1 号纠错码变成1,把 24 列中的 1 的个数填补成偶数。这样接收方接收到数据以后,如果发现二次列的 1 的个数是奇数,错误在 24 列。如果 24 列的 1 的个数是偶数,错误在 13 列。通过上面这两个纠错码的区域既有校验结果,我们就能确定数据错误所在的列。假设已知数据块内有一个错误,如果两个区域都通过了,既有校验没有发现错误,那说明错误在第1列。如果两个区域既有校验都出错,那说明错误数据在第4列。而如果 1 号区域发现错误, 2 号区域没有发现,那说明错误在第二列。反过来, 1 号区域没发现, 2 号区域发现了,错误就在第三列。
将数据按照一定的规律分成不同的几组,让它们之间有一定的交集。这个交集该怎么取?计算机中有一个定位数据的好方法二分法。我们只对一半的数据再做检查,如果错误不在这一半,就在另一半。比如,我们可以让 2 号数据位不再存放原始数据,而是对右半边的数据进行基偶校验。目前右半边的数据中有两个 1 已经是偶数了,所以我们的 2 号校验码保持是 0 即可。这时候,假设有一个数据在传输过程中发生了错误,接收方收到数据以后,如果发现右半边的 1 的个数是奇数,说明错误在右半边。如果右半边的 1 的个数是偶数,说明错误在左半边。顺着这个思路往下捋,我们还需要一个纠错码,继续把一半的数据再对半分来进一步缩小范围。比如我们可以设置第1号数据为纠错码,也不存放原始数据了,而是用来对 24 列的数据进行基偶校验。我们发现 24 列里有 3 个1,所以我们让 1 号纠错码变成1,把 24 列中的 1 的个数填补成偶数。这样接收方接收到数据以后,如果发现二次列的 1 的个数是奇数,错误在 24 列。如果 24 列的 1 的个数是偶数,错误在 13 列。通过上面这两个纠错码的区域既有校验结果,我们就能确定数据错误所在的列。假设已知数据块内有一个错误,如果两个区域都通过了,既有校验没有发现错误,那说明错误在第1列。如果两个区域既有校验都出错,那说明错误数据在第4列。而如果 1 号区域发现错误, 2 号区域没有发现,那说明错误在第二列。反过来, 1 号区域没发现, 2 号区域发现了,错误就在第三列。
当确定错误数据所在的列以后,接下来就是要确定错误数据所在的行。后面的内容你应该猜到了。我们可以用 4 号纠错码检测 24 行, 8 号纠错码检测 34 行。通过一定的交集和排除,我们就能确定错误数据所在的行。结合上面判断出来的列,就可以精确地定位错误数据的位置。而二进制数只有可能是 0 或者1。一旦找到错误数据所在的位置,重新翻转回来,也就可以实现纠正了。这时候会有一个新的问题。

开头我们是假设有一个错误作为前提来判断错误数据的位置。但是如果我们不知道盘面的数据里是否有错误, 1248 校验码全部都既有校验通过了,你会发现 0 号的数据位是不会被纳入保护范围内的,它的错误与否不会影响基偶校验的结果。解决方法其实很简单,无论让 0 号的数据也不存储原始数据,而是让它直接对整个盘面的数据做基偶校验。这样我们可以知道盘面里是不是有错误了,同时也能规避掉 0 号位无法被保护的问题。以上就是汉密码最基础的原理
可能会有人好奇,如果错误的位置正好在纠错码上。其实节目的开头我们提到过,基友校验不是用一个数去保护其他的数,而是用一个数保护一组数。纠错码本身也存在于这组数中,所以你可以自己尝试修改一下某位纠错码,最后自己走一轮基耦校验,你会同样的发现你能定位到纠错码出现了错误。只不过纠错码不影响原始数据,改不改正这都无所谓了。
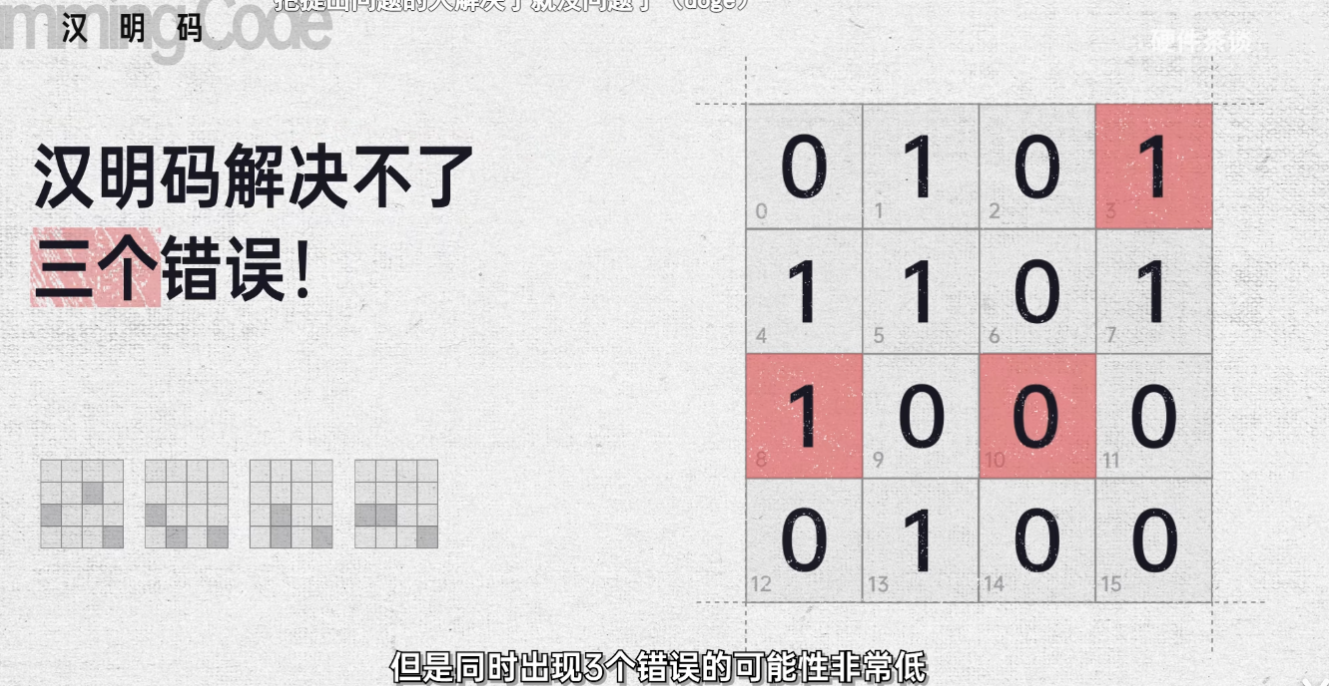
如果传输的数据里同时有两个错误,我们可以再演算一遍,假设第5和第 15 两个数据发生了比特翻转。首先,第二色列区域里的 1 的个数是 4 个偶数,没有错误。但是第三色列里出现了 3 个一奇数取交集,说明错误在第三列第二、 4 行有 4 个1,没有错误,而第三、四行又出现了 3 个一取交集,说明错误在第3行。最终定位错误的数据位置在第 10 位上,但是盘面一共有 6 个一偶数,说明盘面没有错误。盘面的结论和区域的结论发生冲突,说明出现了 2 个错误。虽然我们没有办法定位错误数据的位置,但是我们起码知道有错了,重新传输数据就好了。
这时候可能还会有人问,如果同时出现了 3 个错误,没错哈密码解决不了 3 个错误,但是同时出现 3 个错误的可能性非常低。如果真的出现了,我们要考虑的也应该是降低错误发生的概率,让它不要出现 3 个错误。纠错码存在的意义是用尽可能少的数据去解决不可避免的错误。
此时,我们把整组数据横向排列开来,你会发现除了 0 号,汉密码的位置正好在第一、二、四、八位上,正好是 2 的第 n 次方。这是因为汉密码本质上和二分法原理接近,所以校验位正好是在数据的的一半等位置上。而如果你想传输更多的数据,只需要在每个 2 的第 n 次方的位置上放置一位纠错码,就可以实现对更大块的支持。

块越大,纠错码的占比也就越少。当然,块过大,同时出现好几个错误的几率也就越高。像我们常见的 ECC 内存,在传输数据时,每个块的大小通常是 72 比特,其中 64 比特是原始数据块,另外 8 比特是这 64 比特数据的纠错码。也正是因为汉密码的实现,需要占用额外的数据空间存放纠错码,所以普通 8G 内存只需要 8 颗 1G 的颗粒就可以实现 8G 的容量,而 ECC 内存为了实现 8G 的可用容量,则需要 9 颗 1G 的颗粒。像 3090 泰打开 ECC 显存的功能以后,显存的可用容量下降也是因为这个原因。
【硬件科普】音响耳机麦克风这些设备是怎么工作的?音频的采样率和采样精度是什么?
听觉作为仅次于视觉的第二感官,是人们获取信息的重要来源。为了满足视听的双重传达,越来越多的电子设备都具有了声音播放的能力。这些你每天都在接触的设备,他们究竟是如何播放出我们想要的声音的?想要了解外放设备是怎么工作的,我们首先得知道声音的本质到底是什么。
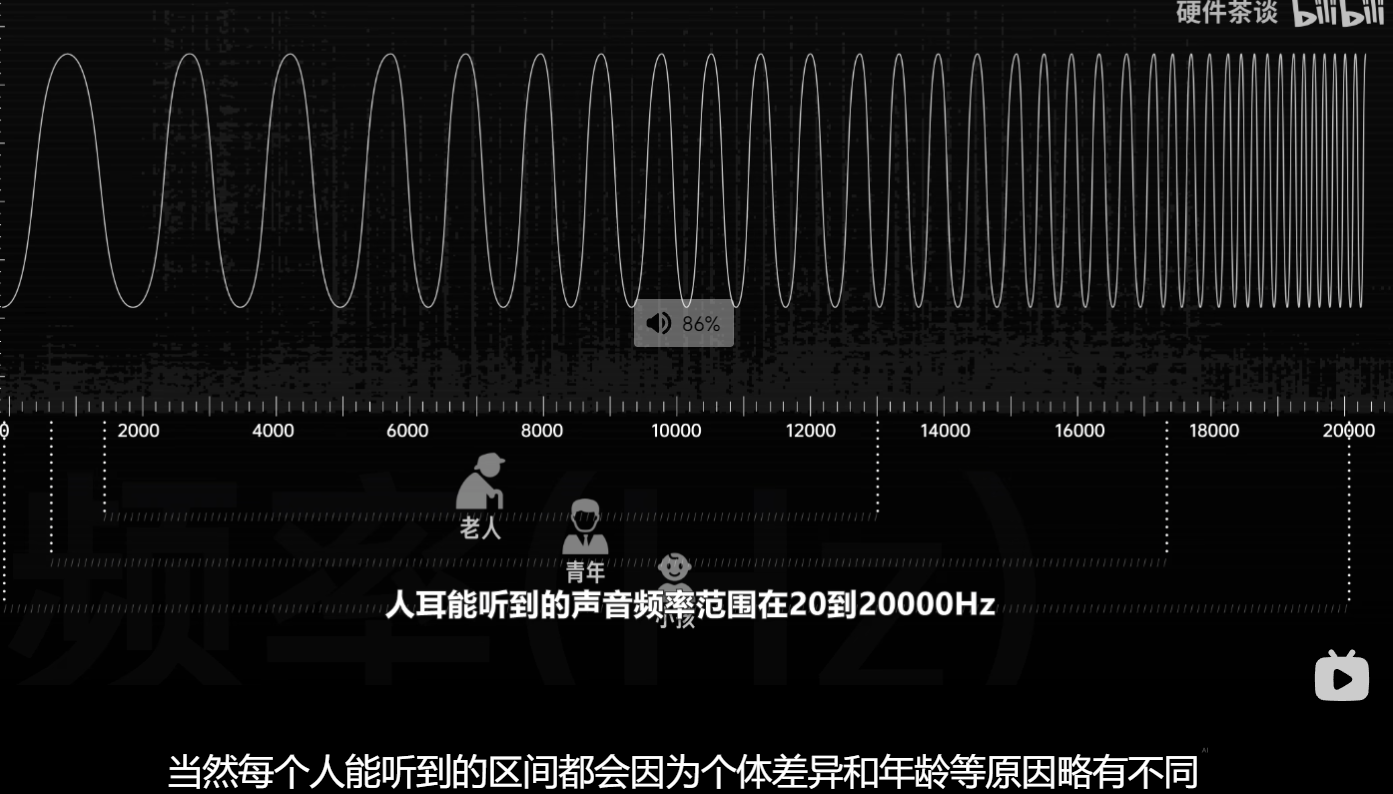
波形图里有两个重要的属性,一个是周期。周期指的是空气分子来回震动所需的时间。周期的倒数就是频率,也就是 1 秒震动多少次,单位是赫兹。比如震动一次的时间是 0. 2 秒, 1 秒就可以震动 5 次,频率就是 5 赫兹。频率会直接决定声音的音调,也就是它到底是do还是ra。频率越低,声音越低沉频率越高,声音则越尖锐。换而言之,我们分辨一个声音到底是什么,其实就是在分辨它的频率。

另外一个属性是振幅,指的是空气分子从原点到最大位移的距离。振幅越大,空气分子振动所包含的能量越多,直观的感受就是声音也会更大。反之,振幅越小,声音则就越小。但振幅不会影响声音的音调。多还是多? right 还是right?人耳能听到的声音频率范围在 20- 2万赫兹。当然,每个人能听到的区间都会因为个体差异和年龄等原因略有不同,但大体是接近的。
。既然声音的本质是振动,我们可以参照人耳的鼓膜设置一个振膜来捕获振动信息。但振膜的振动该怎么转换成可以存储在计算机里的音频文件呢?电磁感应现象可以帮到大忙。我们知道,把水通入一根水管,就会产生水流,而把电子通入一根导线,就会产生电流。电流的本质就是电子在导体内发生了定向移动。同时,物理学家发现,电子的运动会受到磁场的牵引。如果我们把一个回路的部分导线放在一个定向磁场内,来回推拉导线,这些电子在磁场的作用下,会和导线发生相对运动,进而产生电流,这就是磁身电。但反过来,电也可以生磁。一根通电的导线周围会产生一个非常微弱的磁场。如果把导线盘成一个圈,磁场的形状就变成了一个甜甜圈了。假如我们盘好几层,磁场的强度就会叠加起来。最后我们就得到了一个螺旋线圈。通过控制通入线圈的电压、电流大小,我们就可以控制磁场的大小,也可以通过调转正负极的方向来调整磁场的方向。这就是电声磁的实际应用。可控磁力的电磁铁。如果你能理解电磁感应现象,那麦克风和扬声器的工作原理也就很好理解了。麦克风就是磁身电的应用。
这是一个经过简化后的麦克风结构,主要有阵膜、线圈、磁铁这三部分。当振膜捕获到振动以后,会带动线圈一块发生位移。线圈一旦动起来,线圈内的电子在磁场的作用下就会发生移动,从而产生电流。此时只需要监测线圈两极的电压,就可以得到声音的波形图,机械振动就被转化成了电压信号。但麦克风捕获到的电压曲线是模拟信号,而计算机只能存储 0101 的数字信号,这时候我们就需要对这个电压曲线进行量化,也就是魔术转换。ADC。 AD 芯片会每隔级微秒对麦克风线圈的电压波芯图进行一次打点采样,得到每一点的电压值,并把它们转换成二进制数。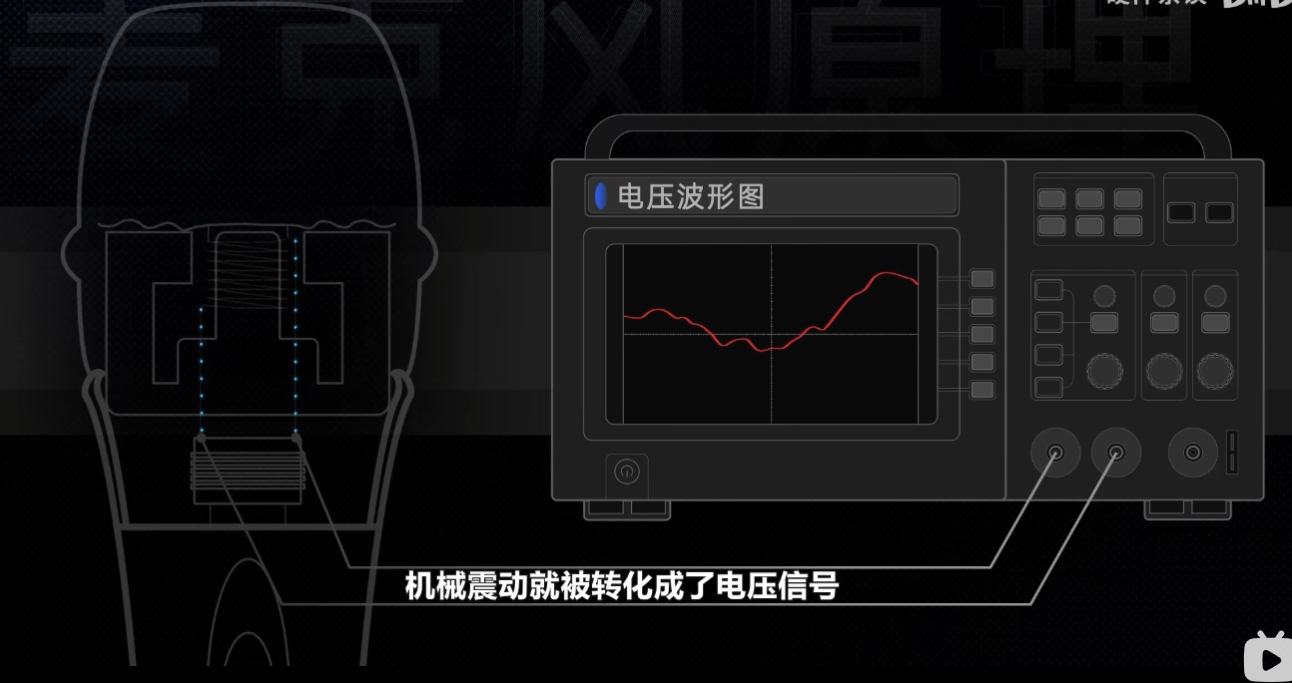

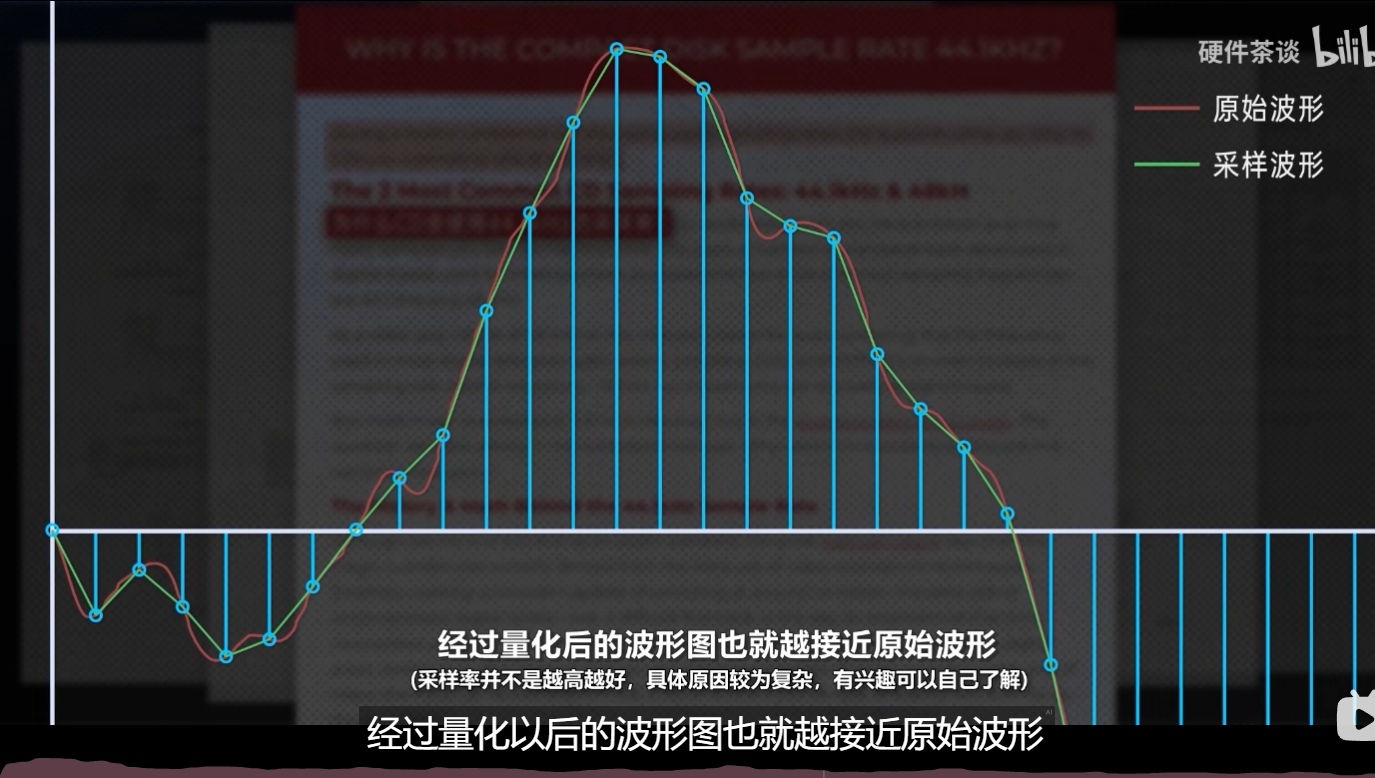
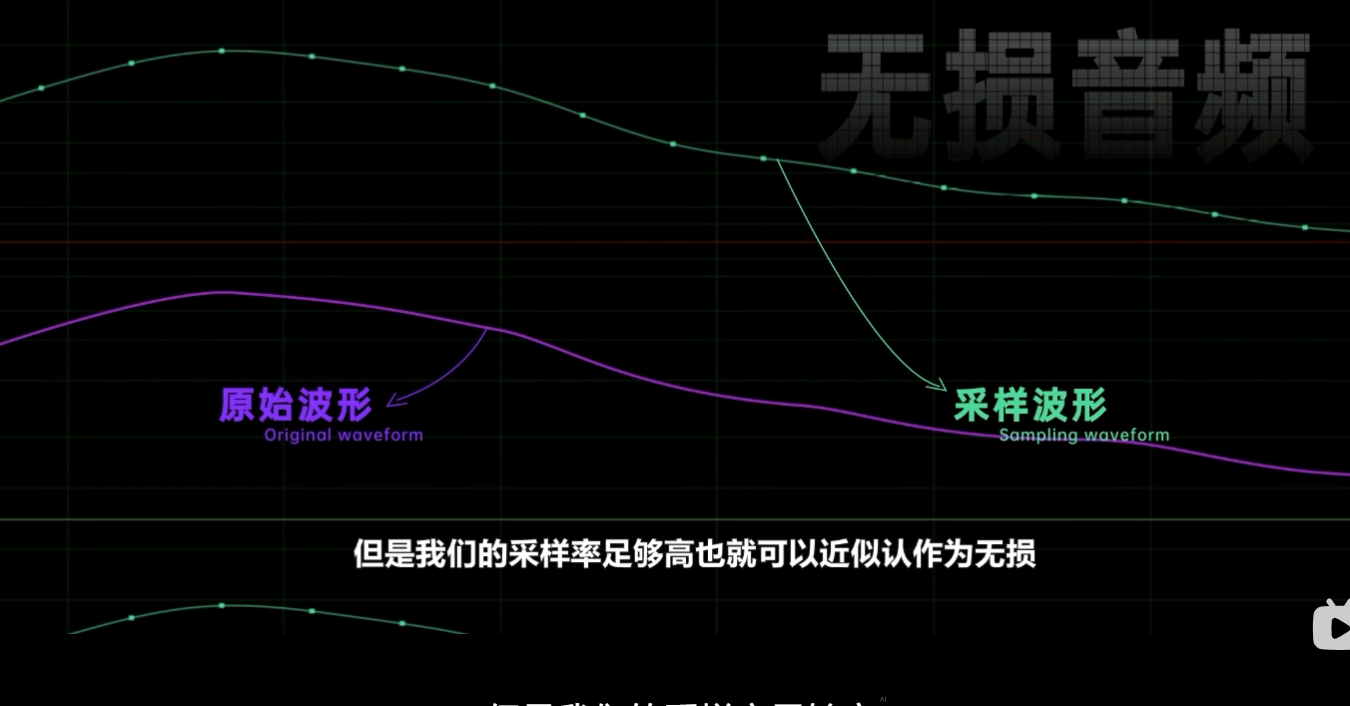
1 秒。采样多少次就是音频的采样率。根据向东奈菲斯特采样定理,采样频率高于信号最高频率的一倍,原来的连续信号就可以从采样样本中重建出来。而人耳可以听到的频率范围是 20- 2万赫兹,所以我们的采样率只要高于4万,就可以还原出原本的声音了。由于上个世纪录像机的录制格式与 PAL 制式规范等一些原因,这个数值最终被定为了 4410 零赫兹。现在常见的也有 48000 赫兹、 96000 赫兹等等。采样次数越高,两次采样的间隔时间越短,经过量化以后的波形图也就越接近原始波形。
除了采样率,魔术转换的过程中还有一个参数也很重要,那就是采样精度。如果 44100 48000 是对横坐标的时间进行采样,那采样精度你就可以理解为对纵坐标的电压值进行采样。如果采样精度只有一位数,那这个电压就只有 0 和 1 两种状态,声音也就只有静音和出声这两种记录方式。如果采样精度有两位数,那就是00011011,这四种状态音频的电压就能被细化成 4 个台阶。同理,如果是有三位数,那音频的电压就可以被细化成 8 种状态。这里边几位数就是几比特,也就是每次采样会产生的数据大小,采样精度只需要高于 16 比特,量化导致的音频失真就几乎听不到了。
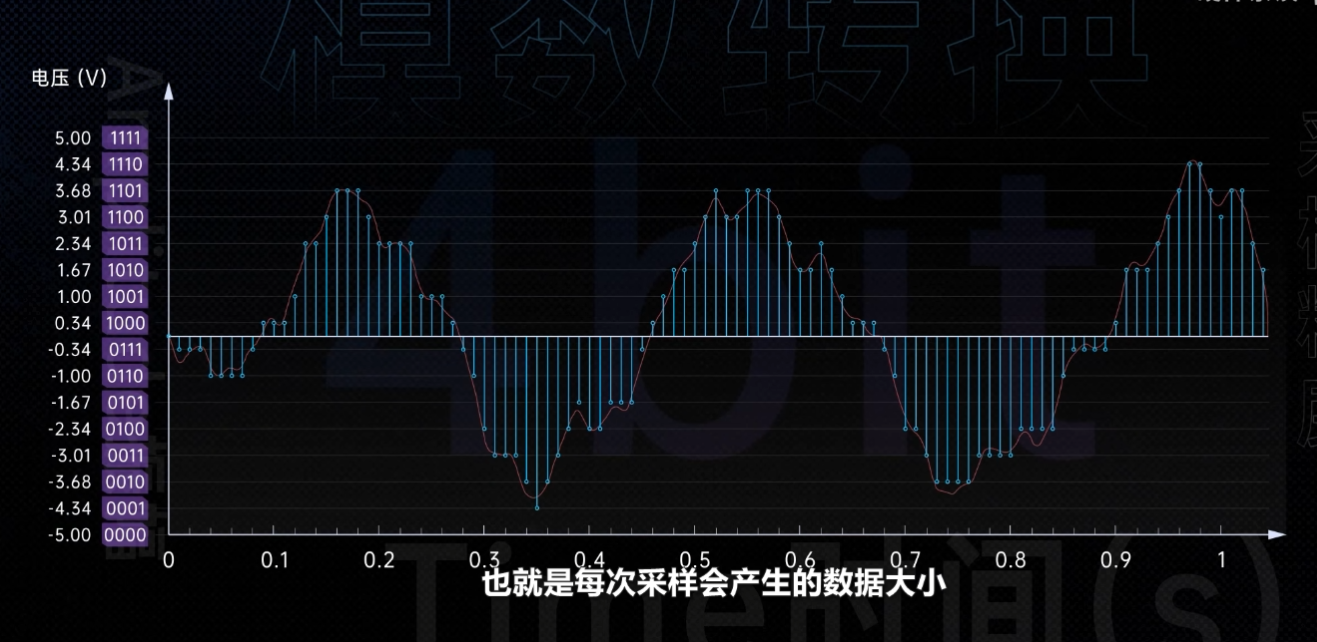
现在的音频文件大多都是 24 比特的,也就是 2 的 24 次方,相当于 y 轴的电压,存在 16777216 个台阶,足以细化声音的各种细节。最后我们再把这些信息按照时间依次排列开来,就得到了一份音频文件 24 比特。 48000 赫兹的单声道音频文件,一秒采样了 48000 次。每次采样会产生 24 比特的数据,所以一秒钟的数据量就有 24* 48000,也就是 1152000 比特。常见的音频文件是左右双声道的,所以需要乘以2。而一个 3 分钟的歌曲,总长是 180 秒,再乘以180,也就是总计 41472 万比特的数据,大约 49. 4 MB 的文件大小。
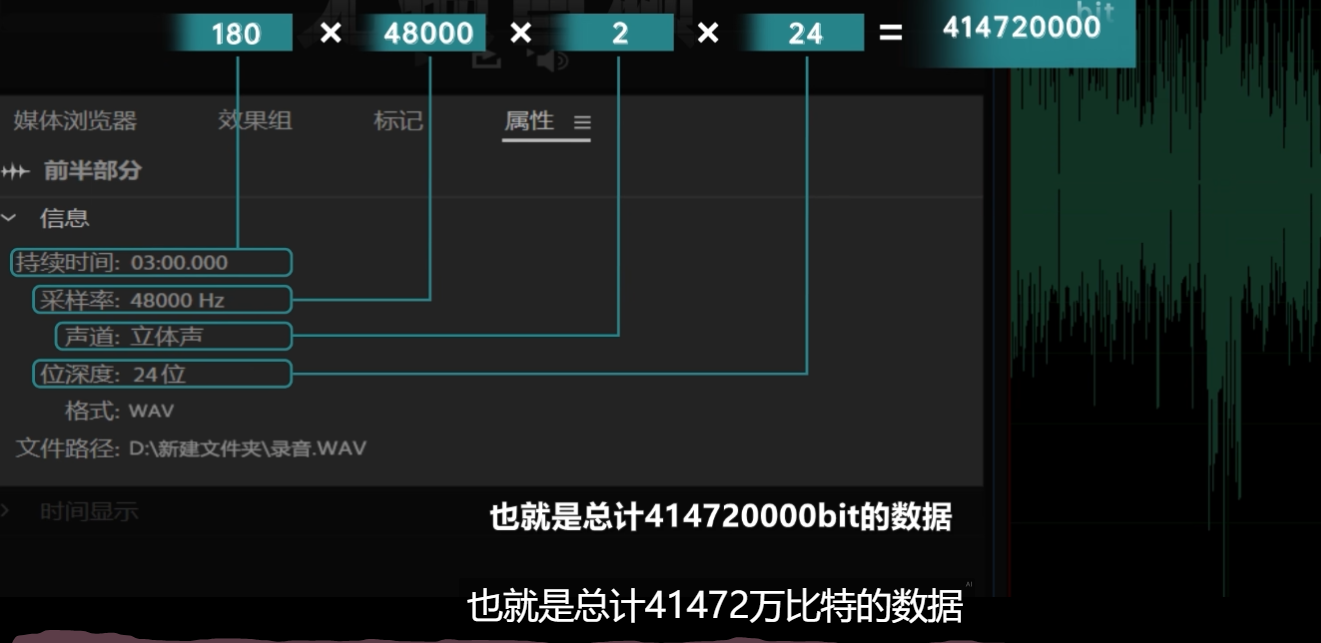
这是一个无损的音频文件,但它不是无损的声音,因为采样后的数据必定和原始的电压波形图有些微的差别,但是我们的采样率足够高,也就可以近似的认作为无损。
 我们常见的 MP3 歌曲只有十几兆的 t 机,是因为它们都经过了有损压缩的。关于音频压缩,碍于篇幅限制,之后有机会再给大家详细的讲解。这时候你在看到系统声音设置中关于扬声器的各种输出规格,也就可以明白这些参数到底是什么意思了。过高的采样率和采样精度也会占用硬件性能,在绝大多数情况下,设置为 24 比特 48000 赫兹就可以满足需求了。
我们常见的 MP3 歌曲只有十几兆的 t 机,是因为它们都经过了有损压缩的。关于音频压缩,碍于篇幅限制,之后有机会再给大家详细的讲解。这时候你在看到系统声音设置中关于扬声器的各种输出规格,也就可以明白这些参数到底是什么意思了。过高的采样率和采样精度也会占用硬件性能,在绝大多数情况下,设置为 24 比特 48000 赫兹就可以满足需求了。

有了音频文件以后,接下来要做的就是通过扬声器播放出来。扬声器则是电声词的应用,也是麦克风工作原理的倒置。这是一个经过简化后的扬声器,你会发现它的结构和麦克风是一模一样的。这一次,我们是给线圈通电,通过控制电压和电流,控制线圈内的磁场和泳磁铁发生吸引或排斥作用,带动振膜振动,进而发出声音。不过线圈只能接受电压波形图这种模拟信号,所以数字文件在进入音响后还需要经过 DAC 数模转换,通过各种滤波器把原始音频文件重新恢复成平滑的电压波形,最后再施加到扬声器的单元线圈上。
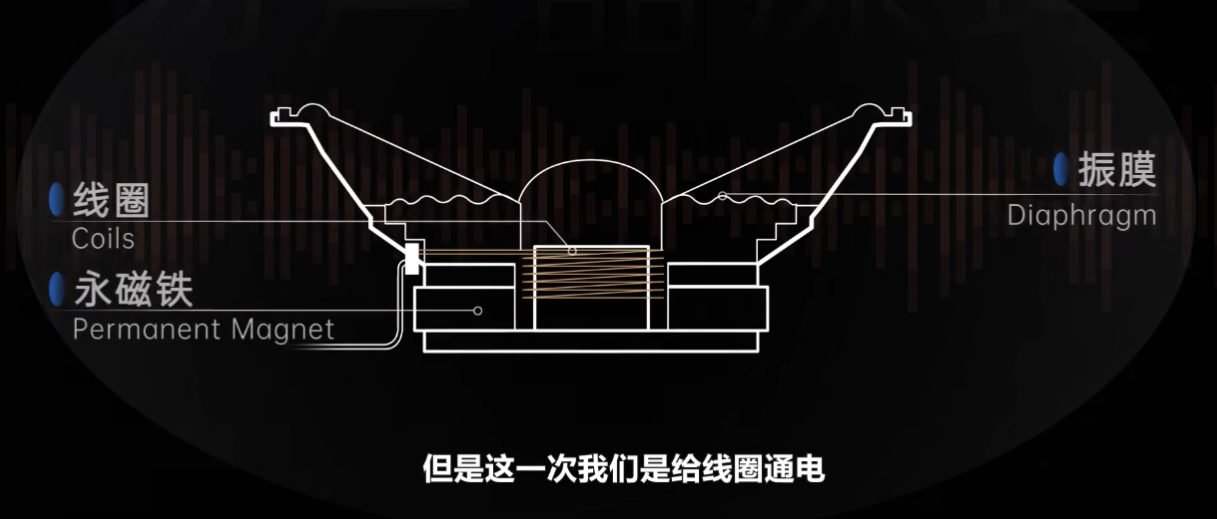
不同类别的扬声器,比如耳机、音响等,底层的工作原理几乎是一模一样的,只不过在设备的尺寸和形态上可能略有差别,这一部分就不再细化了。 OK 到了这里,你就算弄清楚麦克风和扬声器的工作原理了
固态硬盘的缓存是干什么的?有缓存和无缓存有什么区别?
固态硬盘早些年属于高端奢侈品,只有小部分土豪才能用得起的硬件。随着 TLC 颗粒的普及,已经走入了家家户户的电脑中,无论是笔记本还是台式机都存在他们的身影。
在选购固态硬盘时,我们有时候会看到某些评测文章或者视频,提及某款固态硬盘是有缓存方案还是无缓存方案。在关于性能测试的部分,经常会听到固态硬盘的缓内速度和缓外速度这一概念。这里边缓存指的究竟是什么?对固态硬盘的性能又有什么影响?固态硬盘的缓存主要分为外置 d RAM 和 SLC cache。

这两个缓存的概念和用途截然不同,为了理解它们的区别和作用,我们首先要从固态硬盘最基础的工作原理开始了解起。这是一块三星的 970 Evo PLUS 2 tb 固态硬盘。撕开表面带有型号和参数的贴纸以后,就能看到构成固态硬盘的几个基础结构。其中主控控制着固态硬盘数据的读取和写入数据时,数据会经过主控处理,随后被存放在难的闪存颗粒中。读取数据时,主控会从难的颗粒里找到数据,之后通过 m 2 接口和 PCE 总线发送给计算机的其他配件。



970 Evo plus 有两块难的闪存,每颗容量1TB。两颗共同组成了 2 tb 主控和难的颗粒,中间是 DRAM 缓存颗粒,里边存放着文件的逻辑物理映射表 FTL 表。要理解这个映射表有什么用,我们就得拆开难的颗粒,看看它的基础结构。颗粒由多层晶片呆屈谱构成,每个呆屈谱有两个区plane。如果我们在对区进行放大,就可以看到密密麻麻、排列整齐、横纵交错的结构

这里边最基础的单位是晶体管。碍于篇幅限制,我们这期节目不会详细讲解具体工作原理,你只需要简单的把它理解为一个可以存储电子的结构即可。我们用一个方块作为简化模型替代。为了方便理解,我们假设一个浮山内最多可以存储 7 个电子,当电子的数量大于等于 4 个时,判定数据是 0 电子的数量小于等于 3 个时,判定是1。这就是 SLC 颗粒。每个佛山晶体管只能存放 1 比特的数据。而 MLC 颗粒每个佛山晶体管可以存储 2 比特的数据,也就是00011011,它的电子有更多的状态。 6 到 7 个电子对应的是 004 到 5 个电子,对应的是 012 到 3 个电子,对应的是 100 到 1 个电子,对应的是11。而 TLC 颗粒,每个数量的电子都对应一个数据,所以每个浮山晶体管就可以存储 3 比特的数据。
